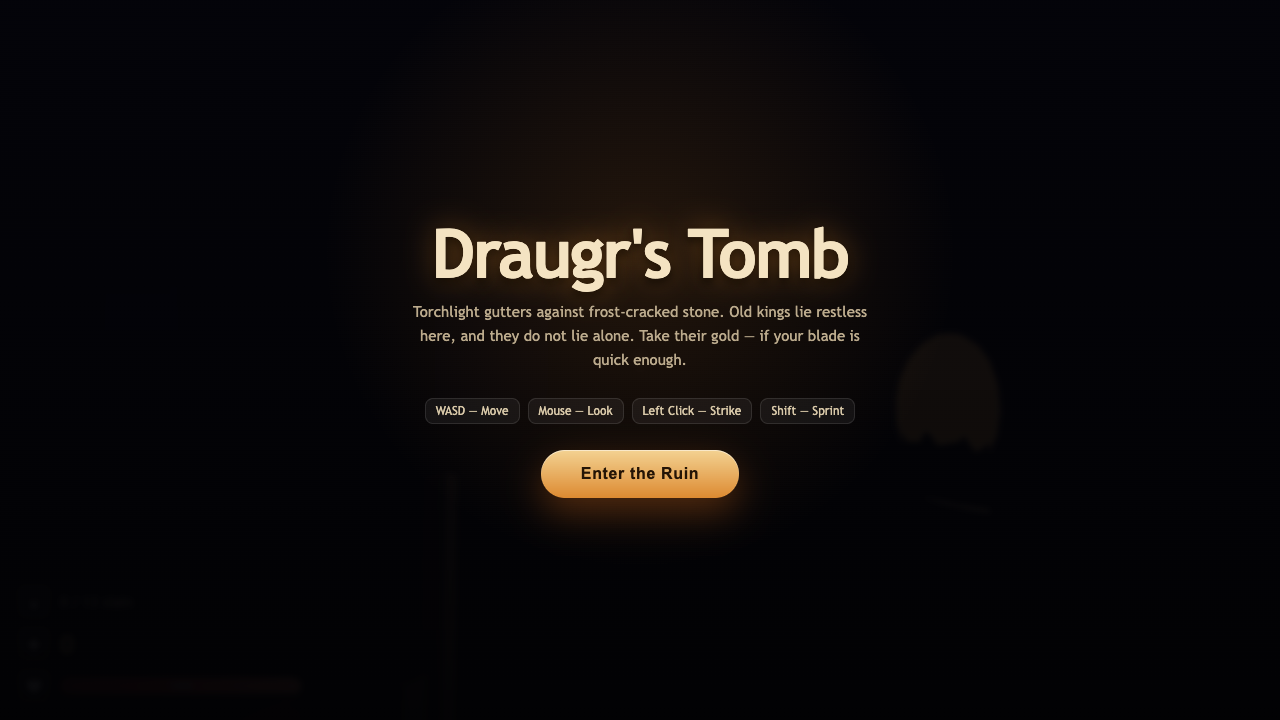
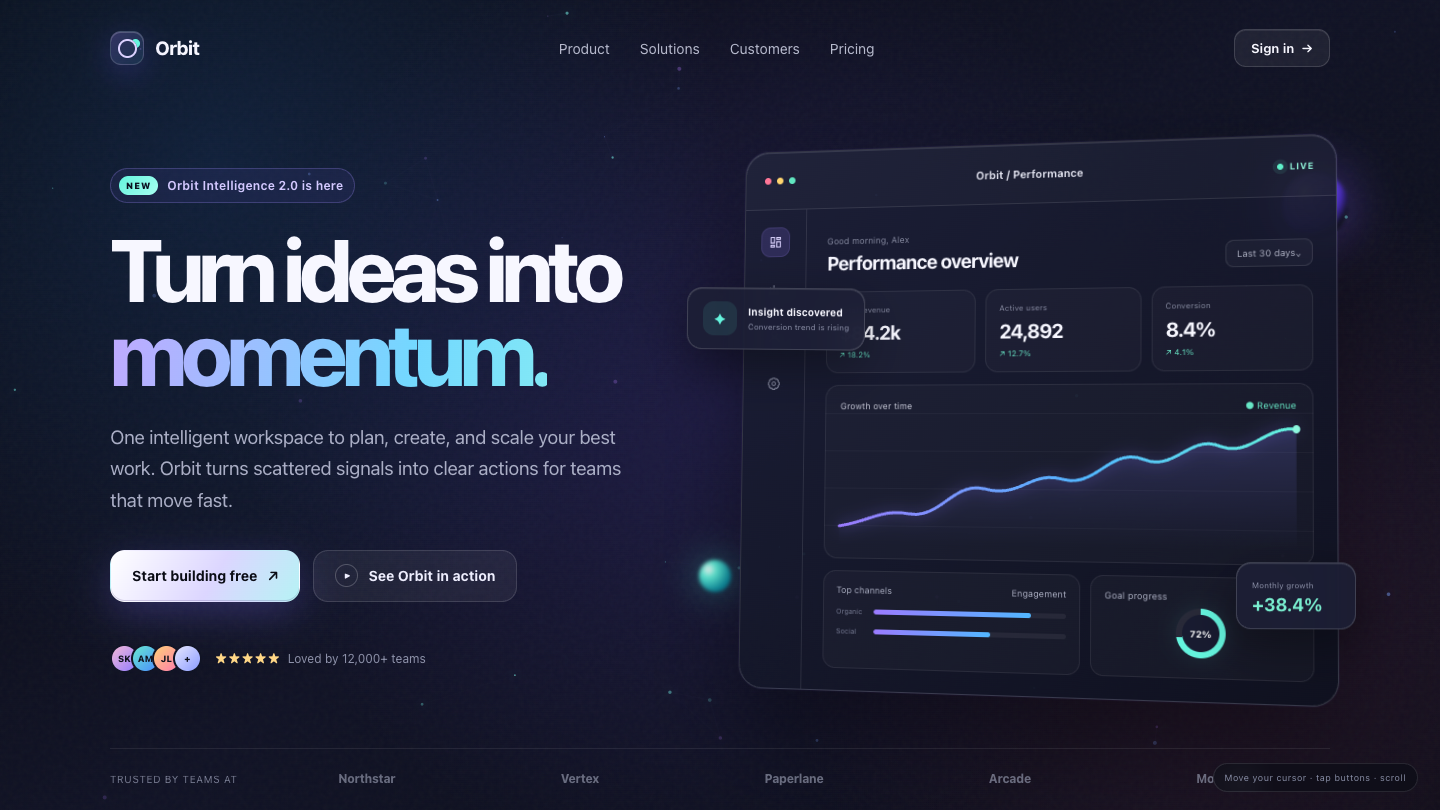
An open model leaderboard
Every AI model. Every task.
Every AI model. Every task.
Ranked.
The Goldie AI Model Leaderboard — every model, every task, every demo, ranked. Click into any cell for the live, playable demo — every model gets the same prompt, every result is on the same page.
1120Live demos
50Tasks
28Models
851Curated verdicts
The leaderboard
Ranking = Julian's actual 0–10 scores averaged across all tasks both ran. Medals = per-task rank (highest = 🥇 gold, second = 🥈 silver, third = 🥉 bronze). Models without scored verdicts are unranked — their demos are still on the bench, but Julian hasn't put a number on them yet.
Scores extracted from Julian's GLM-5.2 vs Kimi K2.7 vs Opus 4.8 and GLM-5.2 vs Qwen 3.7 vs Opus 4.8 guides. See methodology for data provenance.
Ranked by overall average across all tasks. Tap a category to see who wins at it.
Click any column header to sort ↕
| Rank | Model | Best at | Tasks | Medals | Avg / 10 | Reference benchmark |
|---|---|---|---|---|---|---|
| #1 |
Fusion
OpenRouter
|
★ best at Games | 47 tasks47/47 scored | 🥇 21🥈 3🥉 3 | 8.59 | 69.0% DRACO deep-research (premium panel) |
| #2 |
Claude Opus 5
Anthropic
|
★ best at Sims | 50 tasks50/50 scored | 🥇 13🥈 7🥉 5 | 8.27 | — |
| #3 |
Hermes MoA
Hermes · Mixture of Agents
|
★ best at Visuals | 47 tasks47/47 scored | 🥇 4🥈 9🥉 4 | 8.17 | — |
| #4 |
GPT-5.6 Sol
OpenAI
|
★ best at Pages | 50 tasks50/50 scored | 🥇 3🥈 8🥉 12 | 8.16 | 60.5 (+8.7 vs 5.5) HealthBench Professional (Sol) |
| #5 |
Claude Fable 5
Anthropic
|
★ best at Games | 47 tasks47/47 scored | 🥇 4🥈 2🥉 1 | 8.10 | 7.72 avg One-shot pass, before agentic repair of 8 crashed/weak tasks |
| #6 |
Qwen 3.8
Alibaba
|
★ best at Sims | 45 tasks45/45 scored | 🥇 8🥈 7🥉 7 | 8.10 | — |
| #7 |
Grok
xAI
|
★ best at Games | 47 tasks43/47 scored | 🥇 5🥈 1🥉 1 | 8.09 | — |
| #8 |
MiniMax M3
MiniMax
|
★ best at Games | 47 tasks47/47 scored | 🥇 2🥈 1🥉 4 | 7.97 | 1,048,576 tokens Context window |
| #9 |
Fugu Ultra
Sakana AI
|
★ best at Visuals | 42 tasks42/42 scored | 🥇 5🥈 2🥉 2 | 7.94 | 73.7 SWE Bench Pro |
| #10 |
Kimi K3
Moonshot AI
|
★ best at Games | 50 tasks50/50 scored | 🥇 8🥈 4🥉 7 | 7.89 | ~Fable/Sol tier; Terminal Bench the standout Launch-day community benchmarks |
| #11 |
GLM-5.2
Zhipu / Z.ai
|
★ best at Pages | 47 tasks47/47 scored | 🥇 5 | 7.77 | 62.1% SWE-bench Pro |
| #12 |
Fugu Mini
Sakana AI
|
★ best at Visuals | 37 tasks36/37 scored | 🥇 2🥉 1 | 7.75 | — |
| #13 |
Opus 4.8
Anthropic
|
★ best at Sims | 47 tasks47/47 scored | 🥇 3🥈 1🥉 1 | 7.51 | 88.6% SWE-bench Verified |
| #14 |
Kimi K2.7
Moonshot AI
|
★ best at Games | 47 tasks25/47 scored | 🥇 1🥈 2 | 7.46 | 80.2% SWE-bench Verified (K2.6 — K2.7 internal) |
| #15 |
Gemini 3.6 Flash
Google
|
★ best at Pages | 50 tasks50/50 scored | 🥇 1🥈 2🥉 2 | 7.08 | — |
| #16 |
Claude Sonnet 5
Anthropic
|
★ best at Pages | 47 tasks47/47 scored | 🥉 4 | 7.01 | 82.1% SWE-bench Verified |
| #17 |
Qwen 3.7
Alibaba
|
★ best at Games | 47 tasks47/47 scored | — | 7.00 | — |
| #18 |
Fugu Ultra 1.1
Sakana AI
|
★ best at Games | 24 tasks23/24 scored | 🥈 1🥉 2 | 6.94 | 73.7 SWE-Bench Pro (reported) |
| #19 |
Inkling
Thinking Machines
|
★ best at Pages | 50 tasks50/50 scored | — | 6.07 | 77.6% — ahead of Nemotron 3 Ultra (70.7) SWE-bench Verified (agentic coding) |
| prov |
LongCat-2.0
Meituan
|
★ best at Games | 4 tasks4/4 scored · provisional | — | 8.12 | 70.8 Terminal-Bench 2.1 |
| prov |
Hy3
Tencent Hunyuan
|
★ best at Games | 7 tasks7/7 scored · provisional | — | 6.76 | 2.67/4 Expert blind eval |
| — |
DeepSeek V4 Flash
DeepSeek
|
— | 50 tasks0/50 scored | — | unranked | — |
| — |
DeepSeek V4 Pro
DeepSeek
|
— | 50 tasks0/50 scored | — | unranked | — |
| — |
Kimi K2.7 · Fast
Moonshot AI
|
— | 47 tasks0/47 scored | — | unranked | 65s Build time · solar system (one shot) |
| — |
Kimi K2.7 · No-Think
Moonshot AI
|
— | 47 tasks0/47 scored | — | unranked | 47s Build time · solar system (one shot) |
| — |
Kimi K2.7 · Quality
Moonshot AI
|
— | 47 tasks0/47 scored | — | unranked | 71s Build time · solar system (one shot) |
| — |
Claude Mythos 5
Anthropic
|
— | 0 tasks | — | unranked | Vetted partners only Restricted access |
| — |
Kilo Code
Kilo
|
— | 0 tasks | — | unranked | 8.3/10 Cheaper-plan quality (GPT-5.5 cohort) |
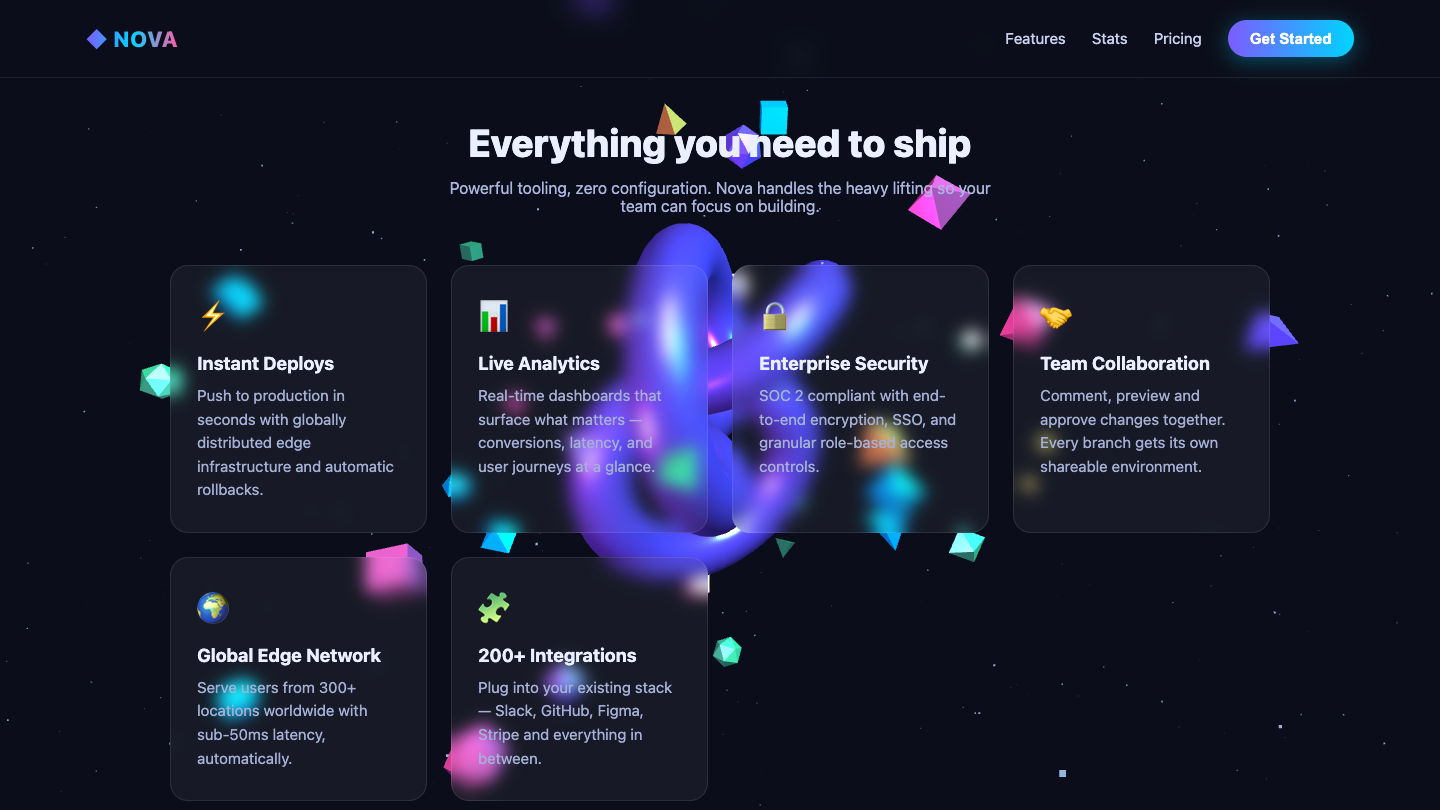
The matrix — tasks × models
Each cell is a live, playable demo. Click any thumbnail to run that model's attempt at that task. Empty cells mean we haven't tested that combo yet.
Task ↓ · Model →
Fusion
Claude Opus 5
Hermes MoA
GPT-5.6 Sol
Claude Fable 5
Qwen 3.8
Grok
MiniMax M3
Fugu Ultra
Kimi K3
GLM-5.2
Fugu Mini
Opus 4.8
Kimi K2.7
Gemini 3.6 Flash
Claude Sonnet 5
Qwen 3.7
Fugu Ultra 1.1
Inkling
LongCat-2.0
Hy3
DeepSeek V4 Flash
DeepSeek V4 Pro
Kimi K2.7
Kimi K2.7
Kimi K2.7
Game









—






—




Game













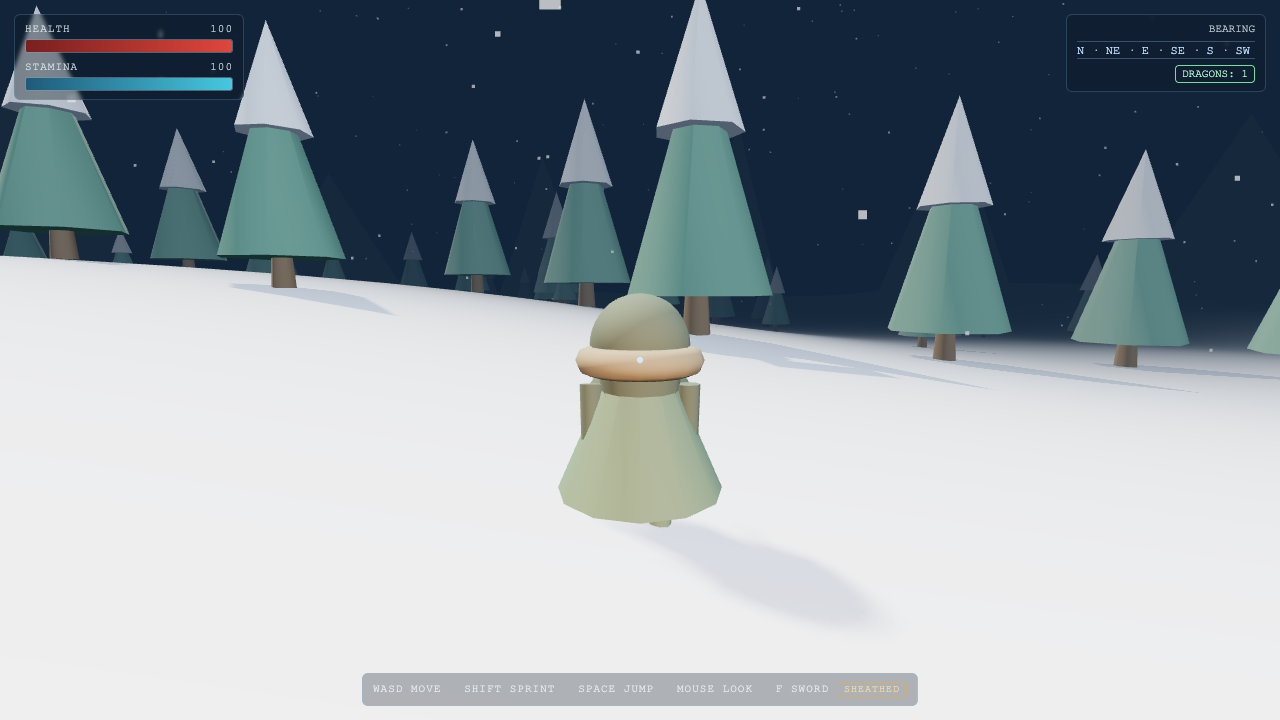

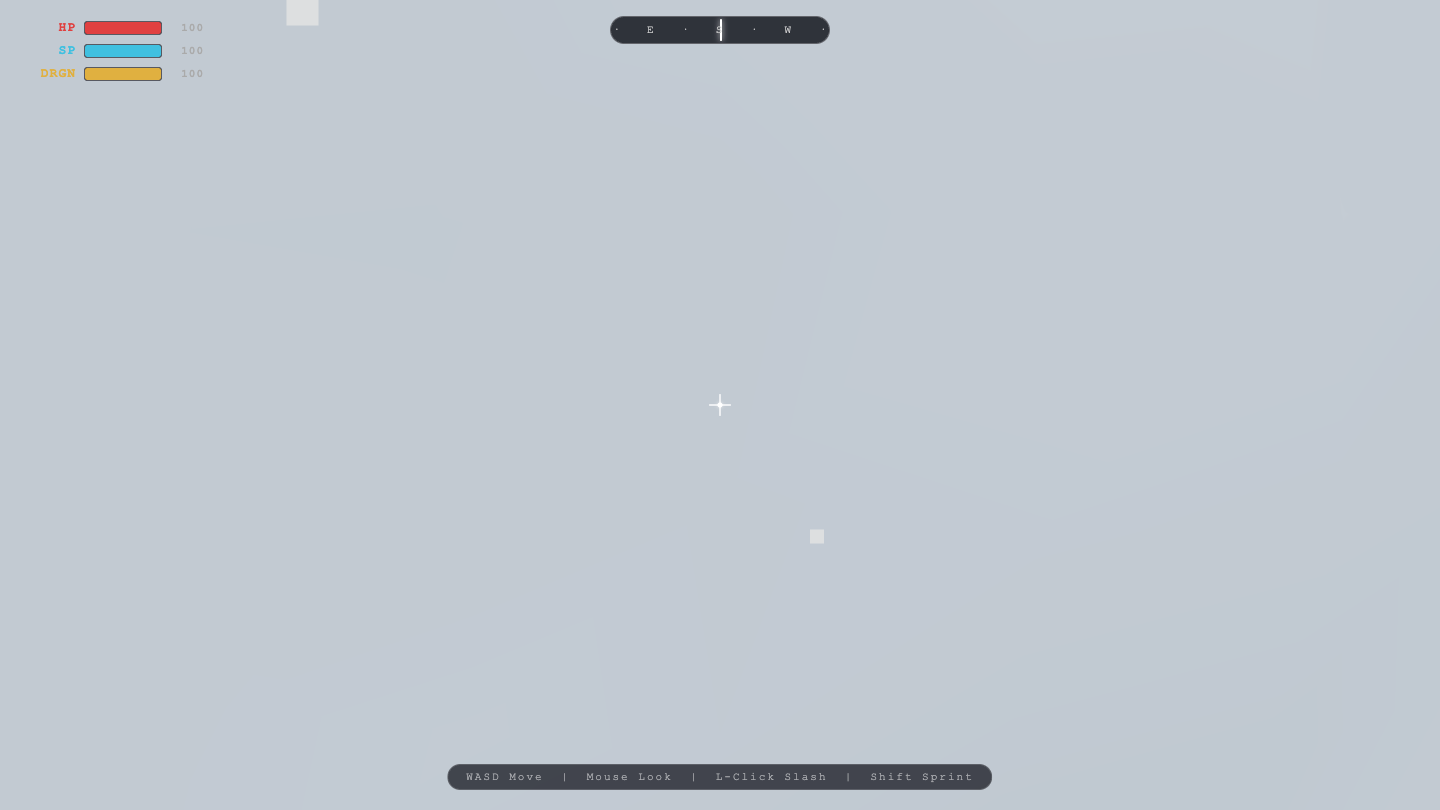



Game

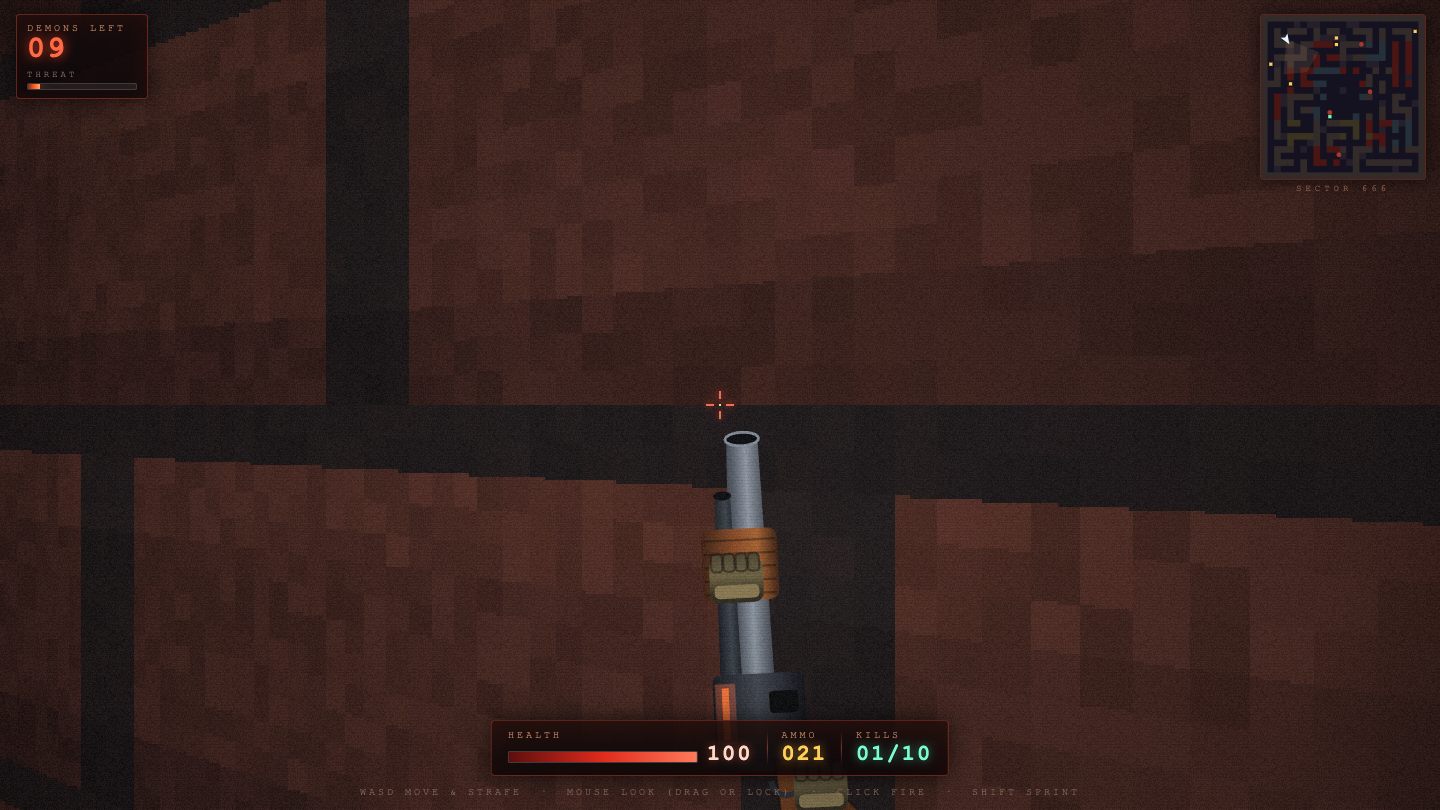




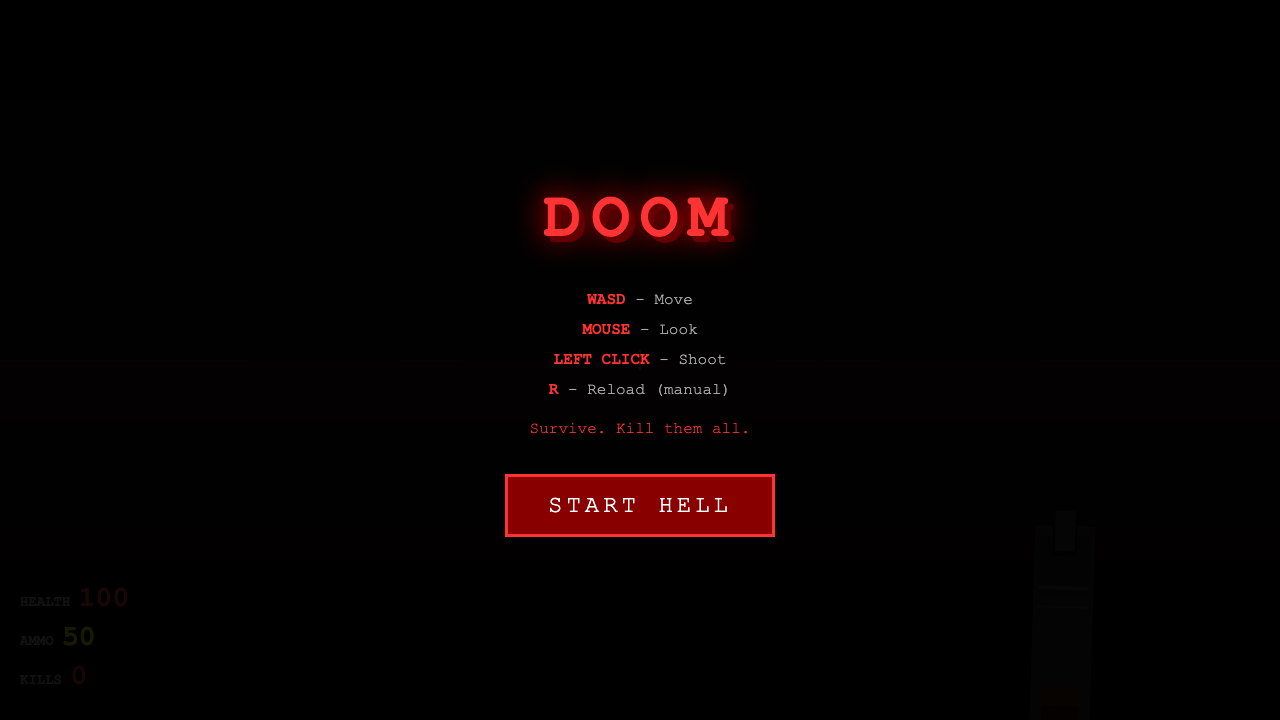





—

Game











—
—

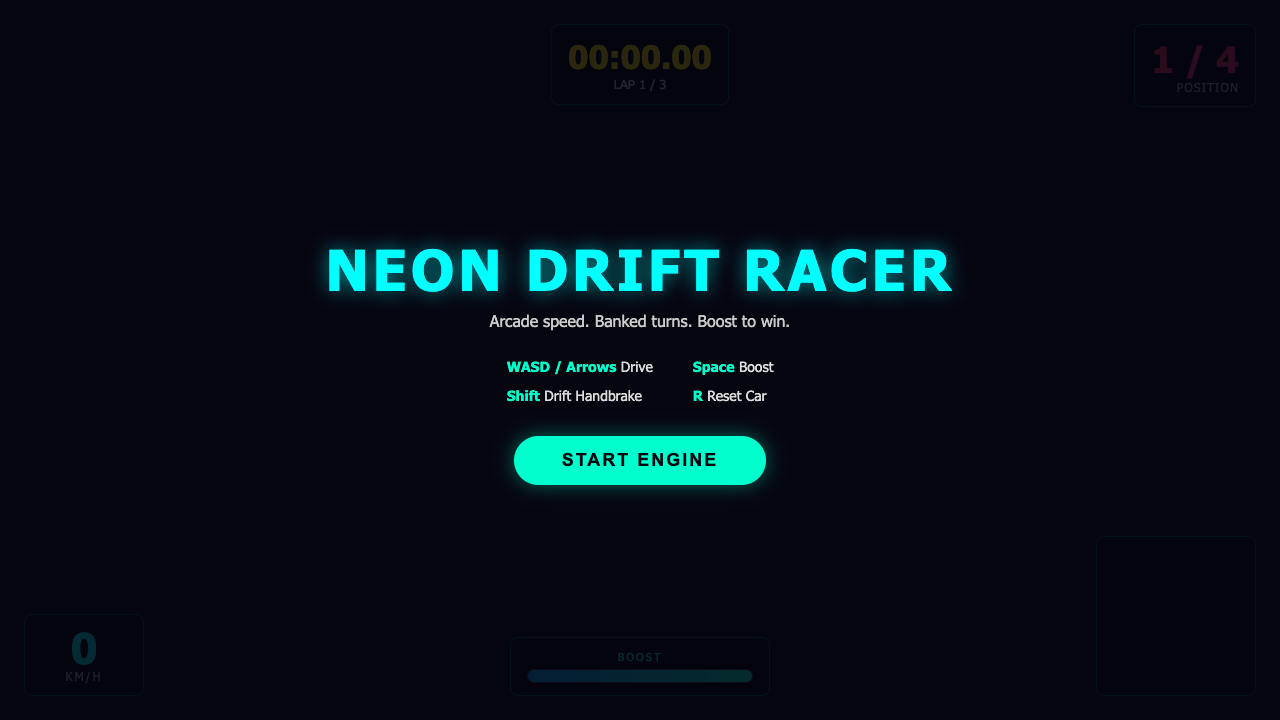

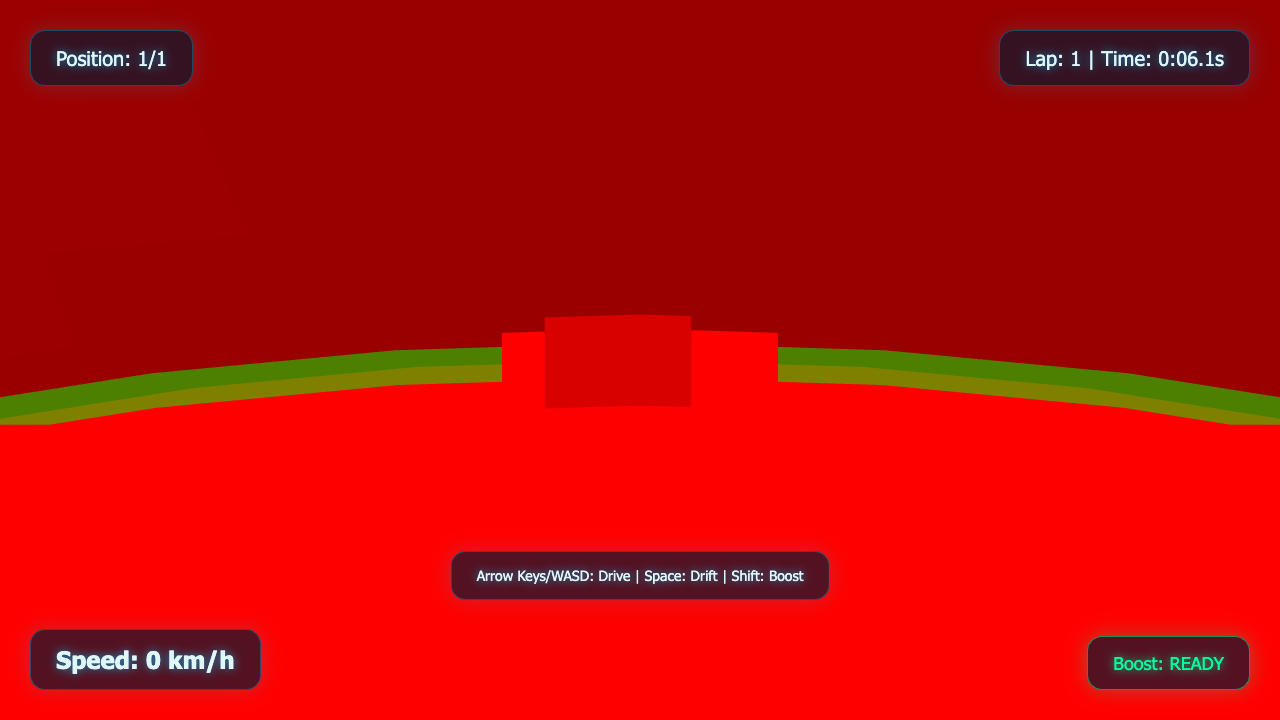
Game

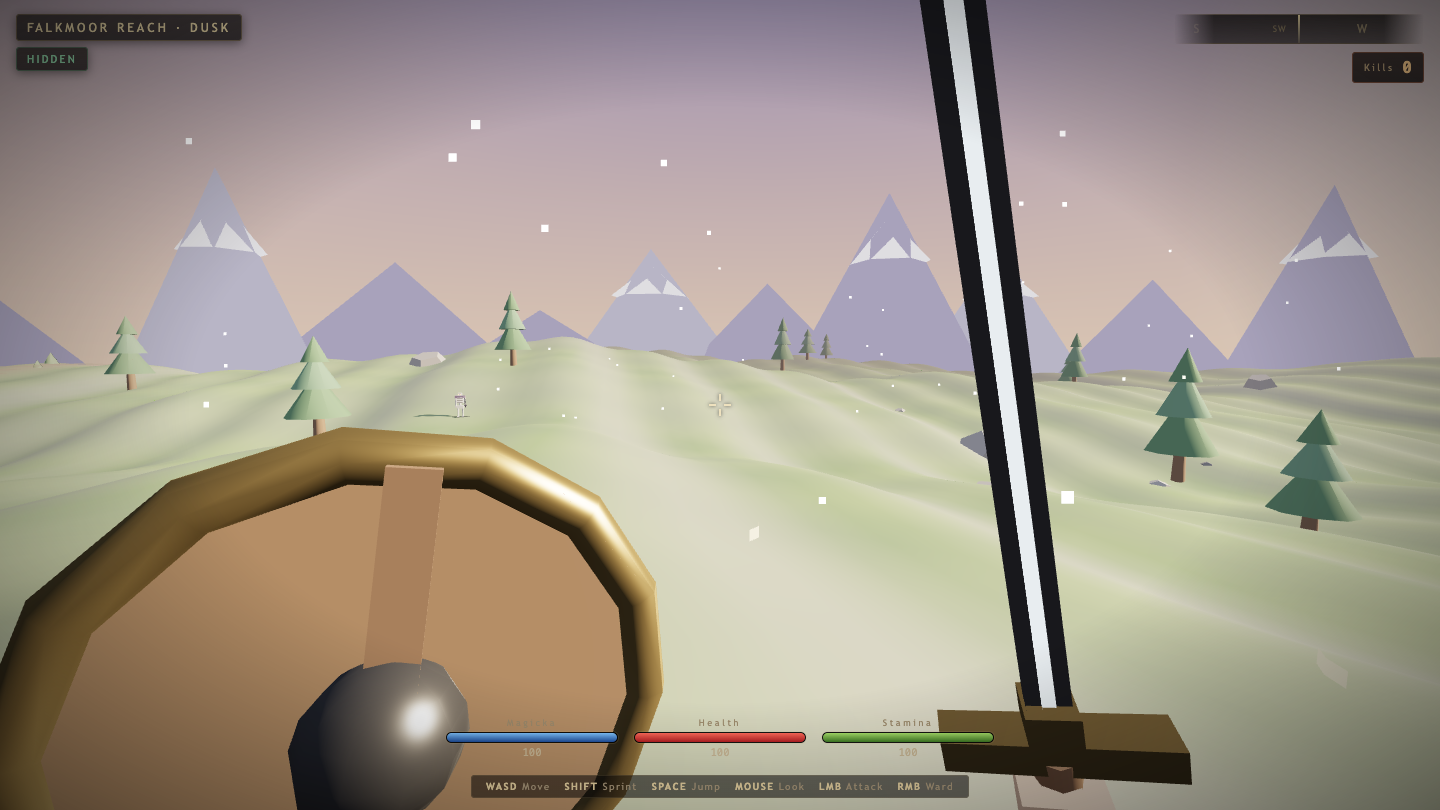

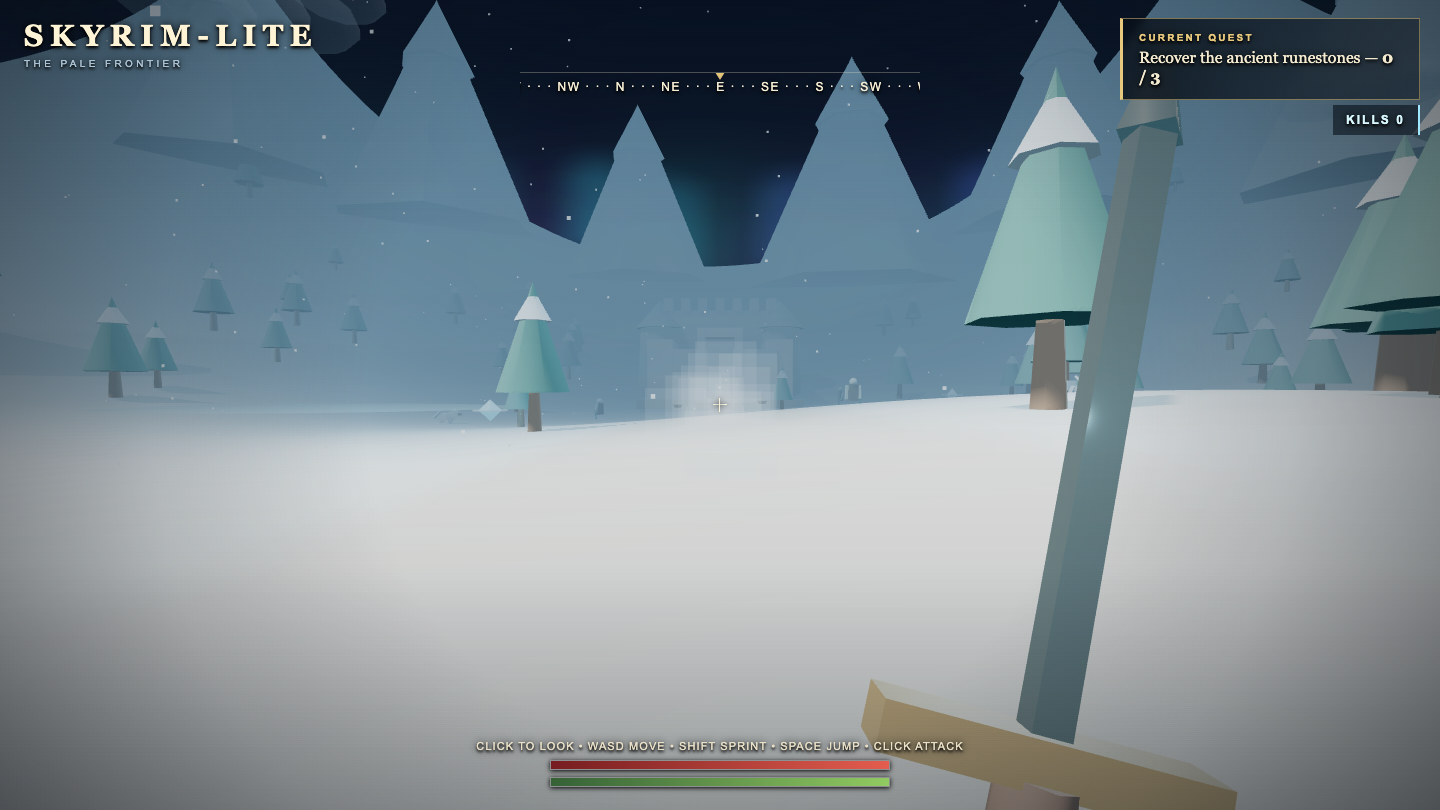








—




Game







—




—
—

Game


—

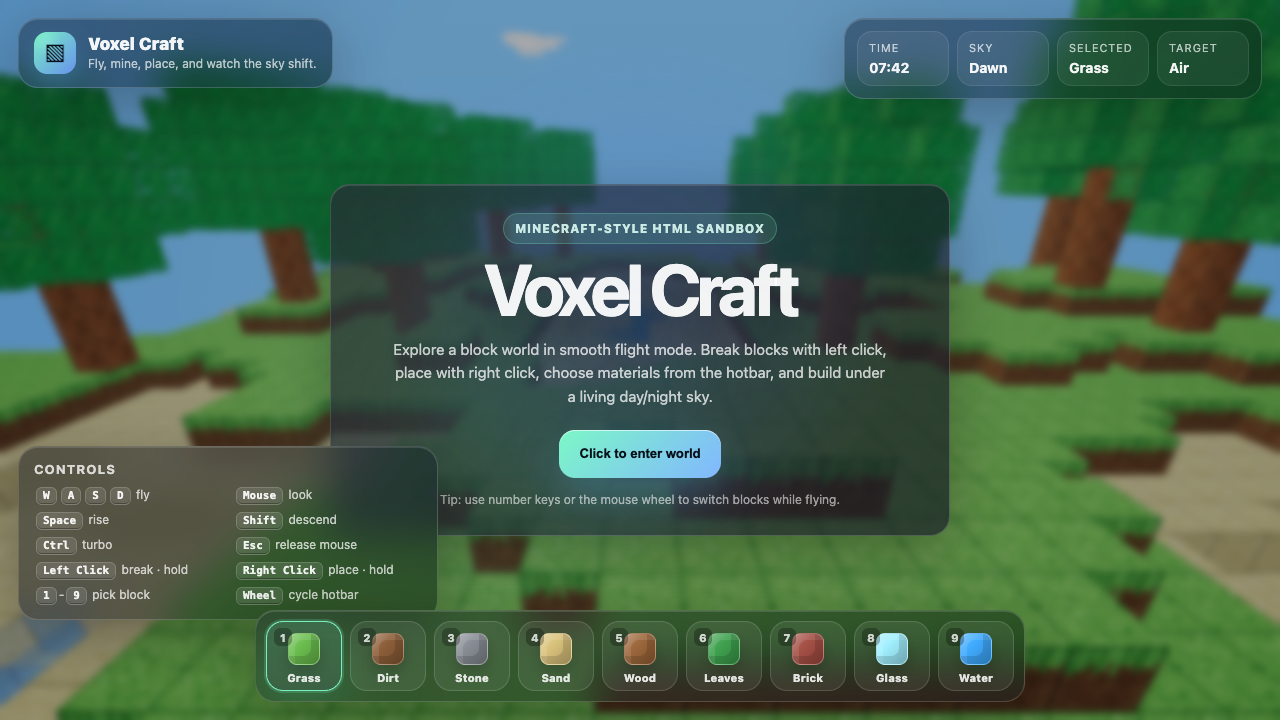
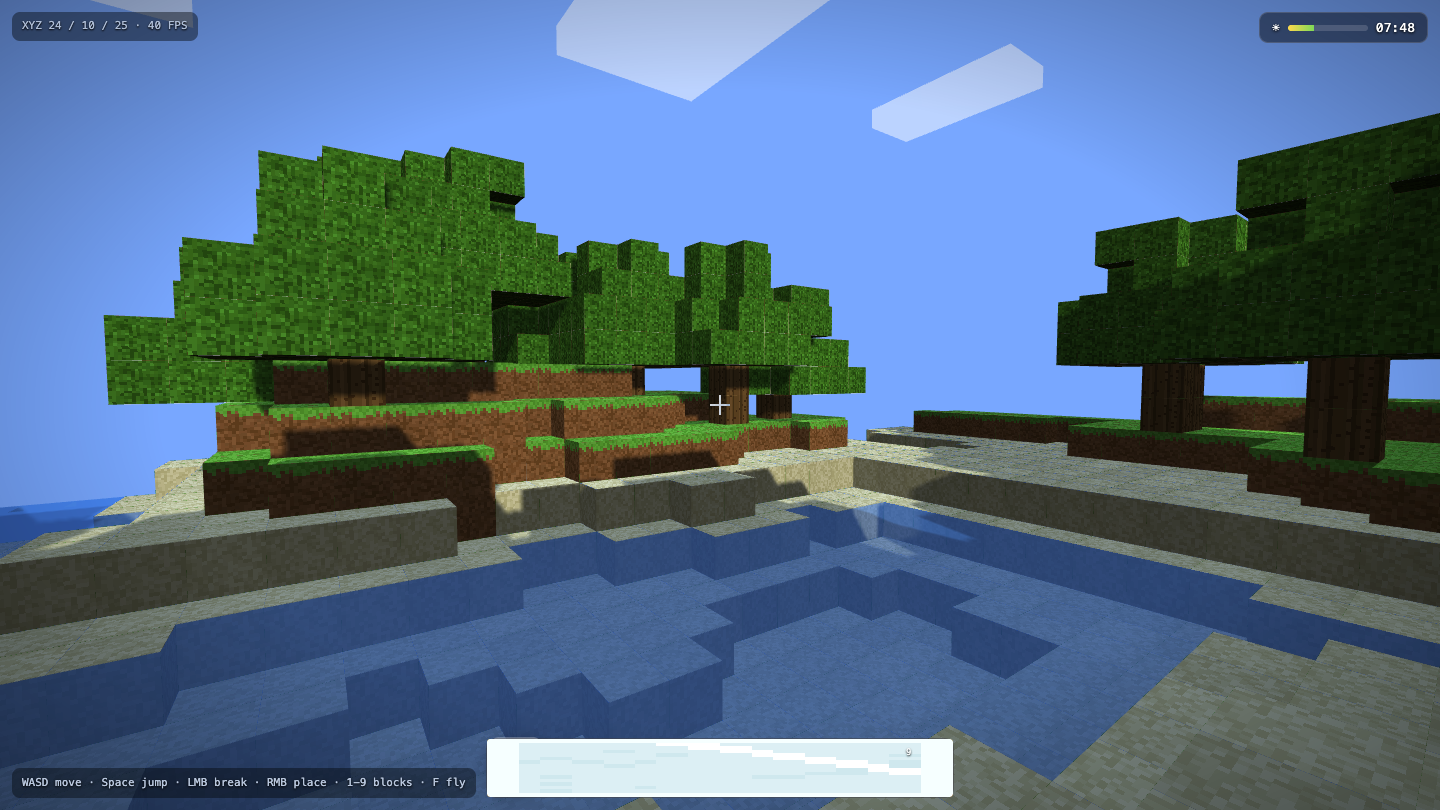

—
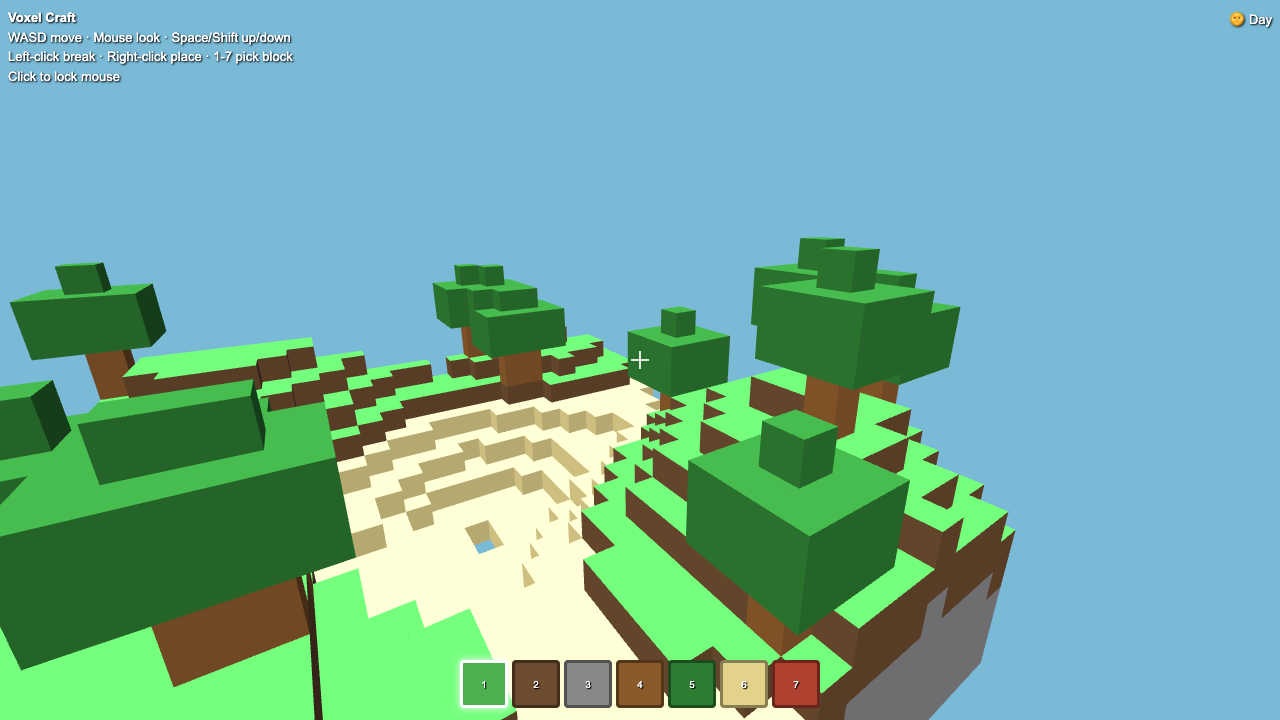
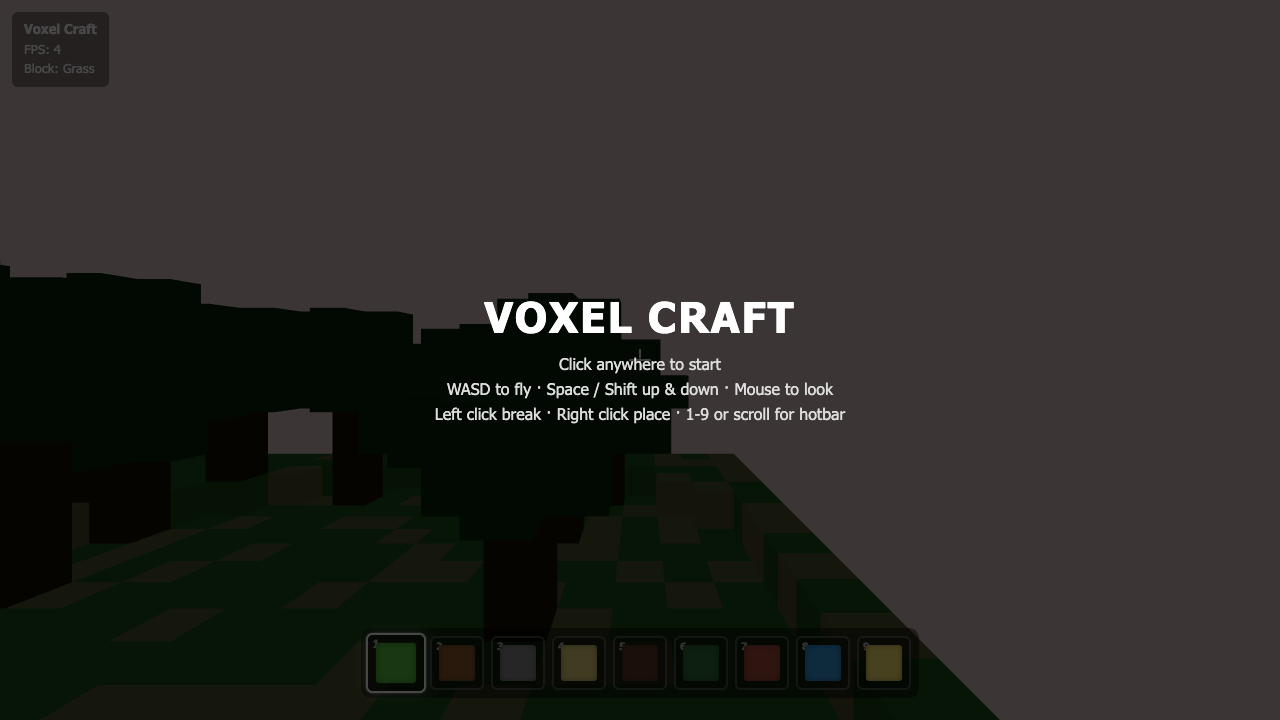
—

—


Game



—


—




—




Game






—


—




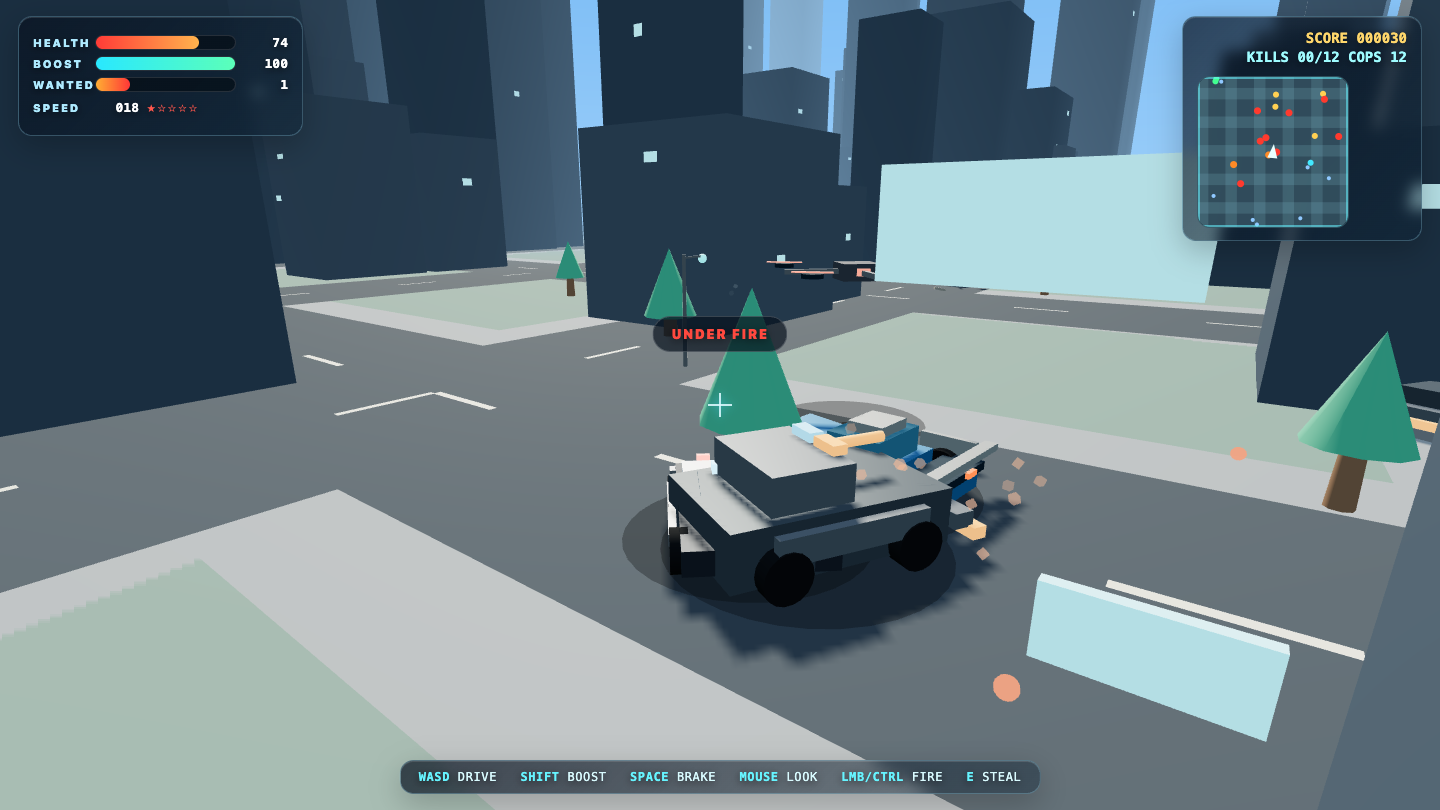
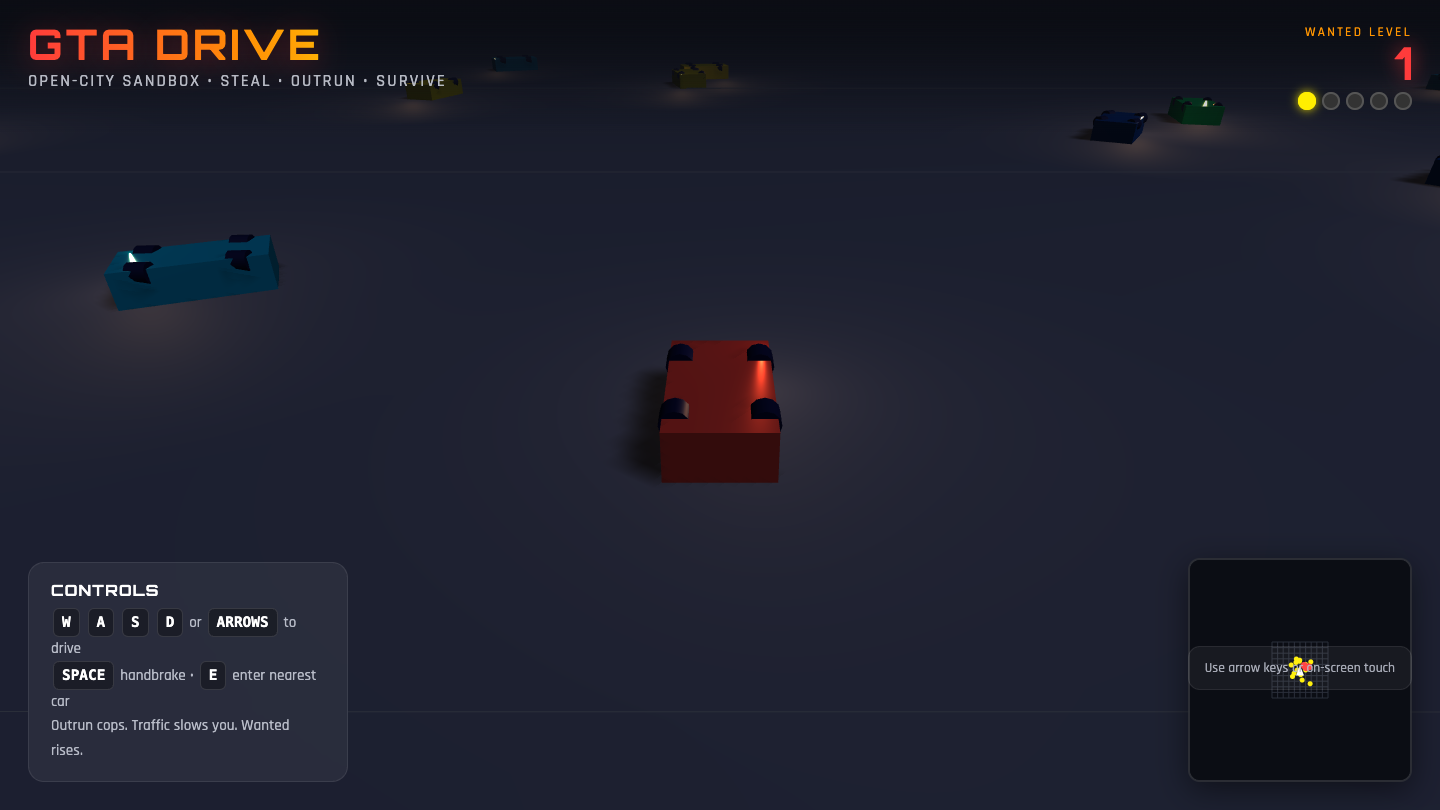
—


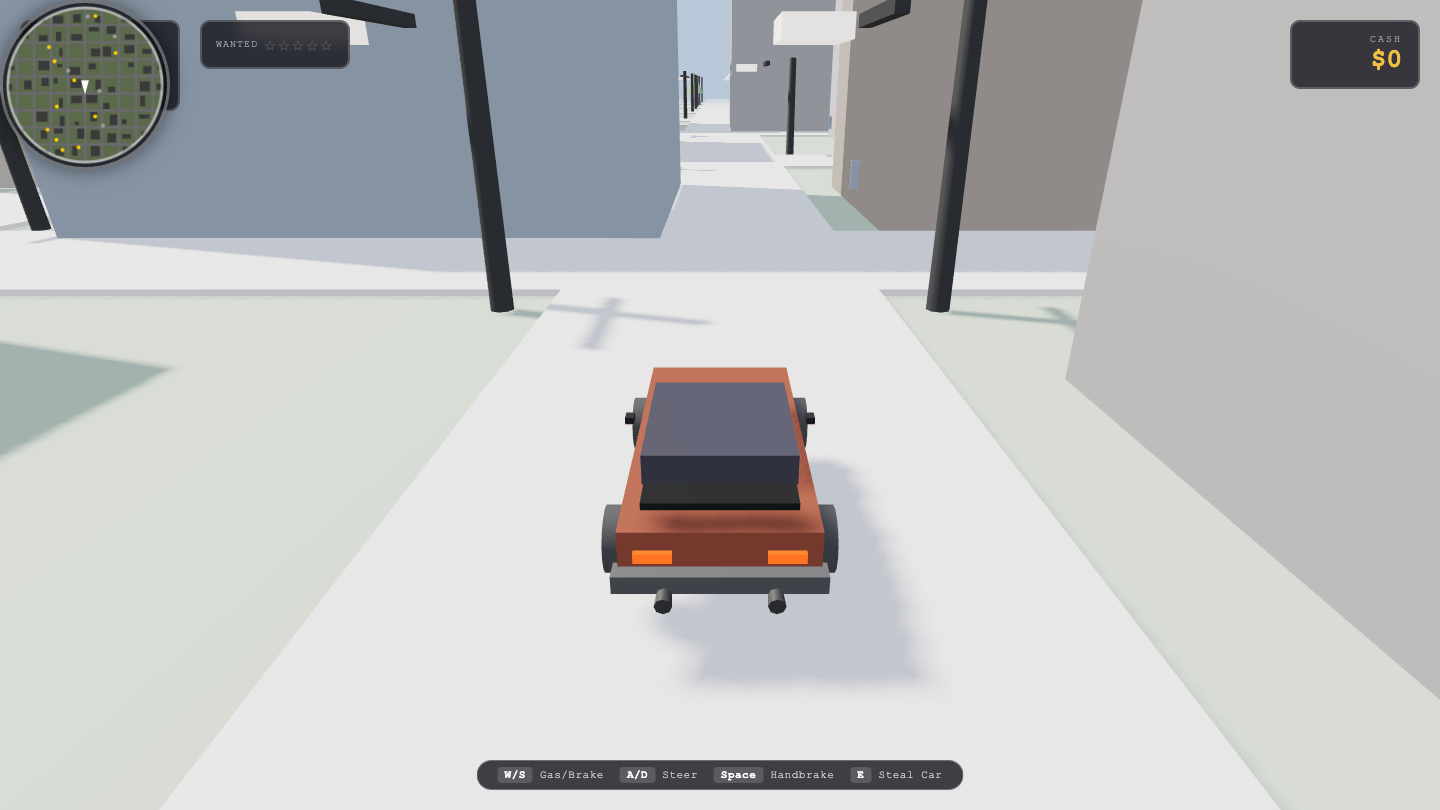



Page








—


—






—




Game




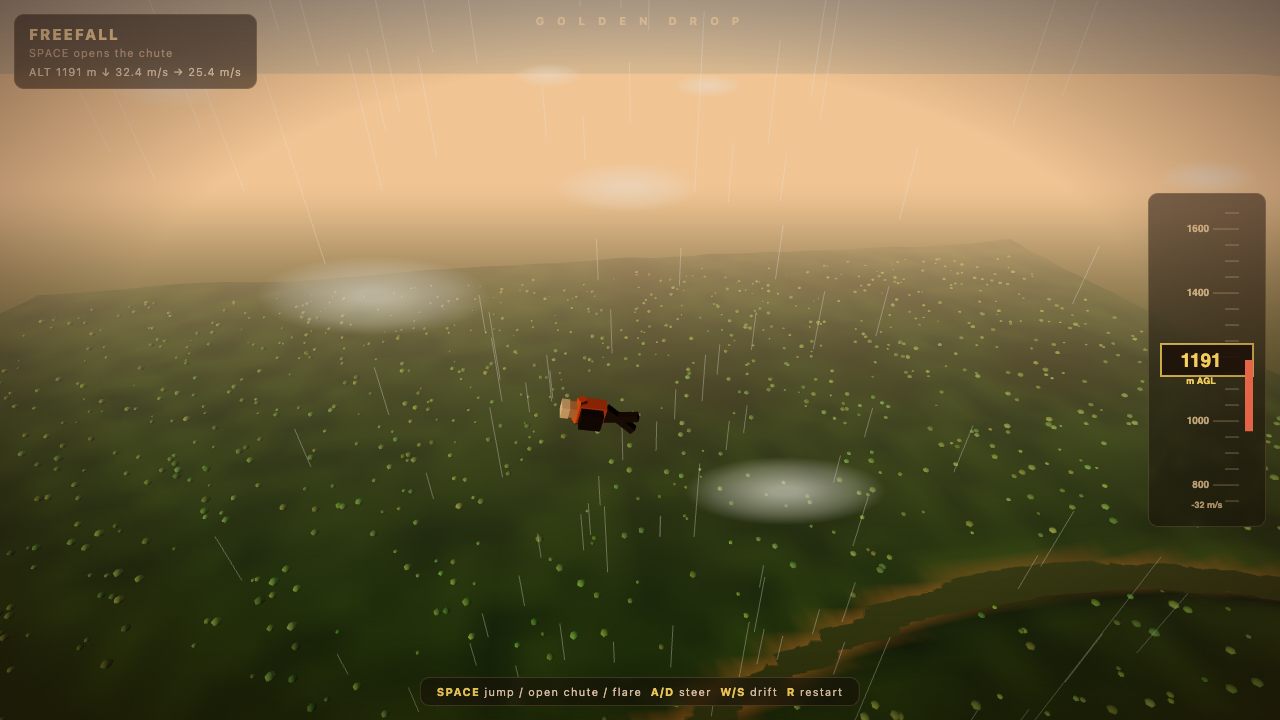
—

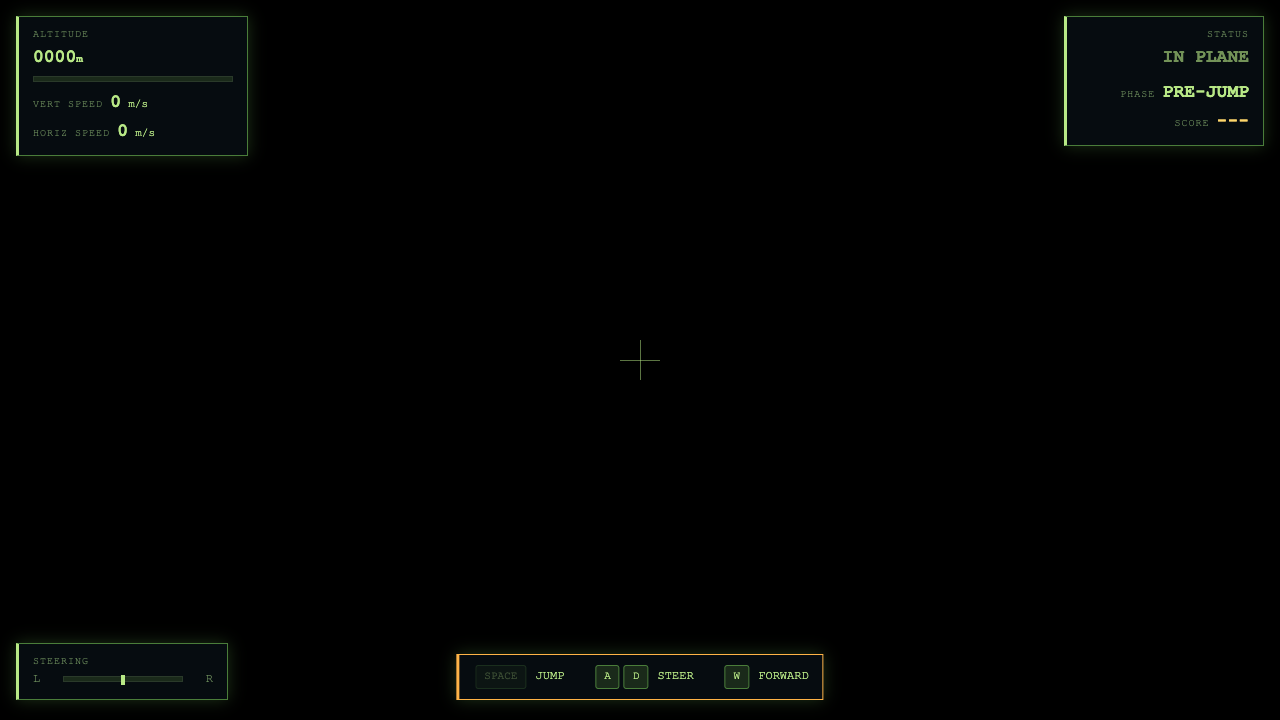
—

—






—


Game


—

—

—


Game








—
—




Visual

















—
—





Game












—
—




Game













—
—



Game















—
—





Game
















—
—


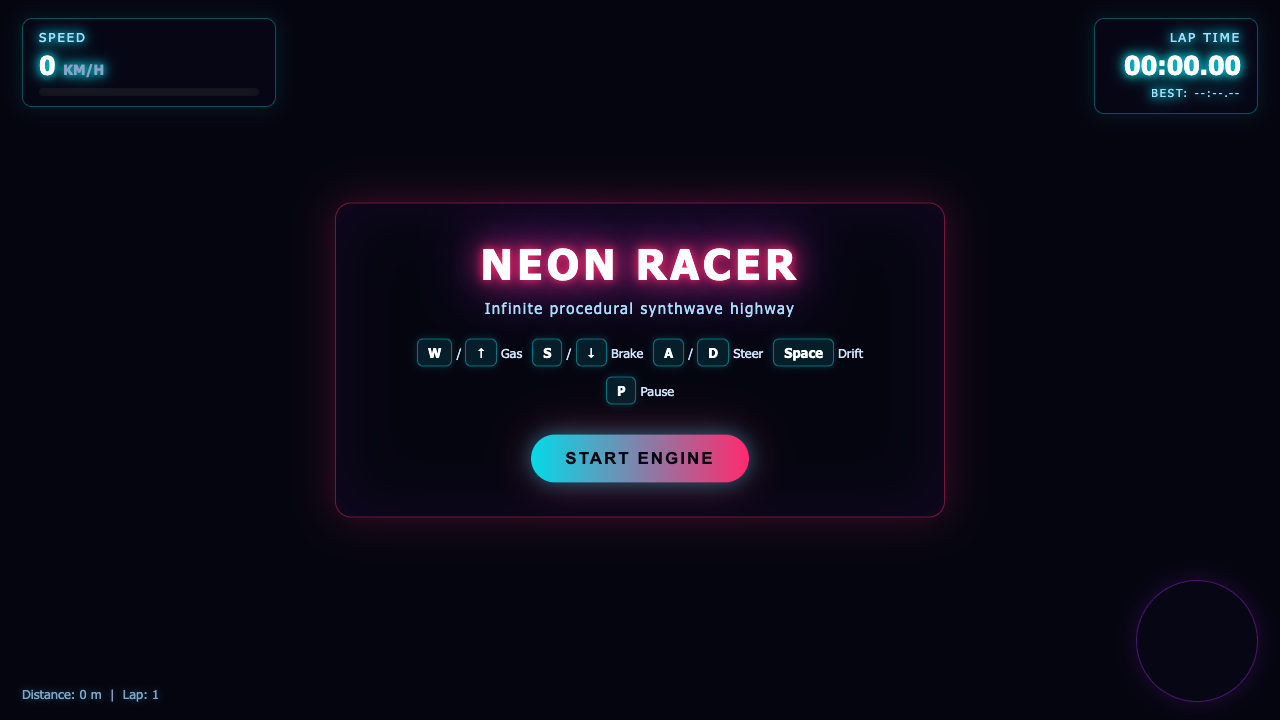


Game
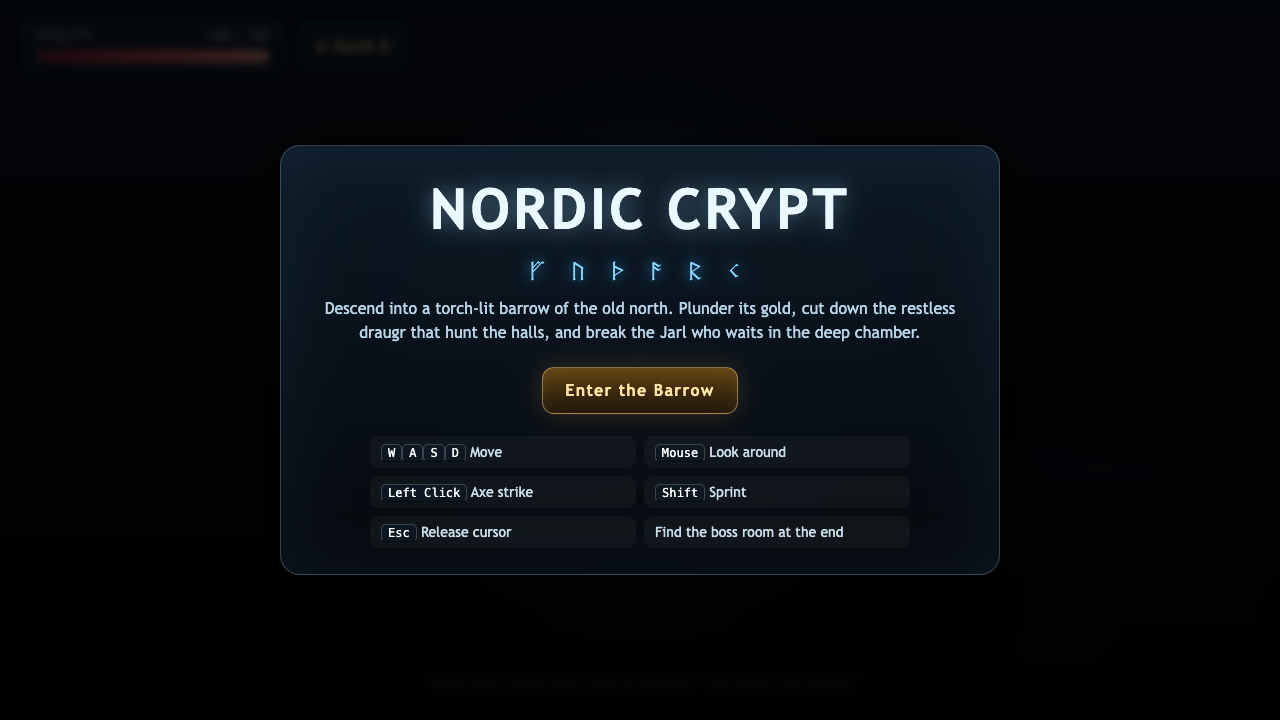

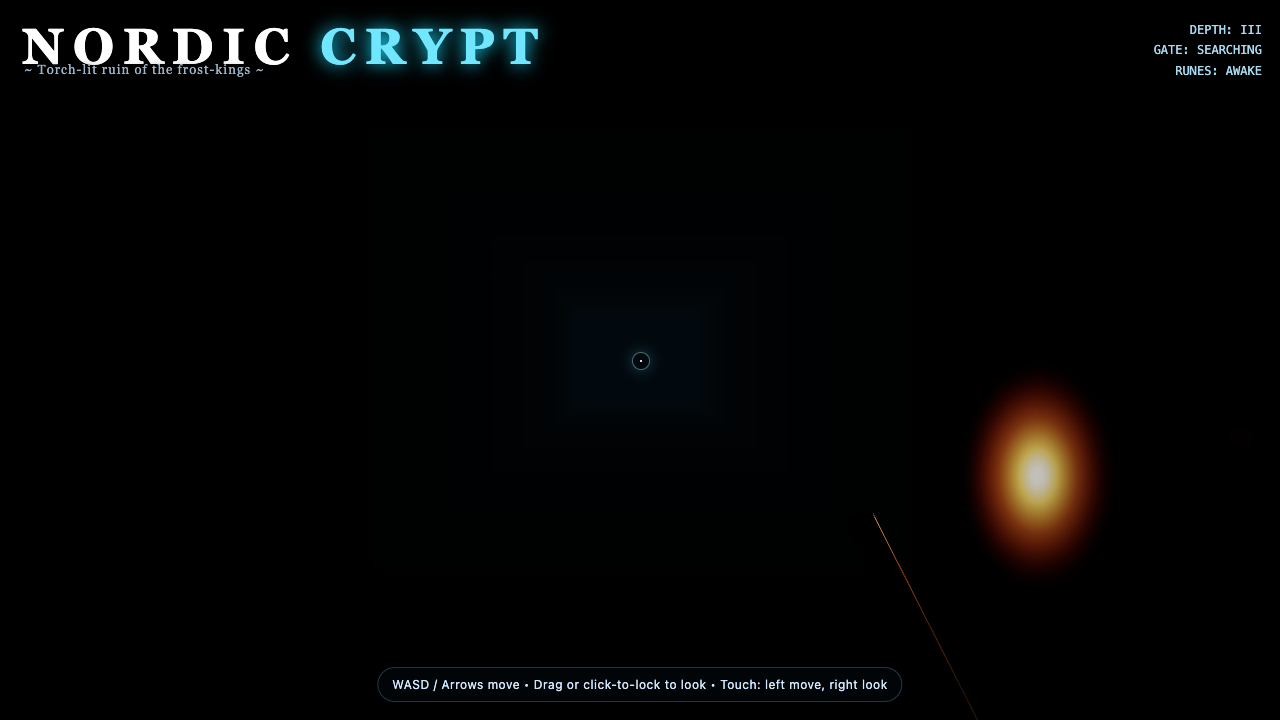


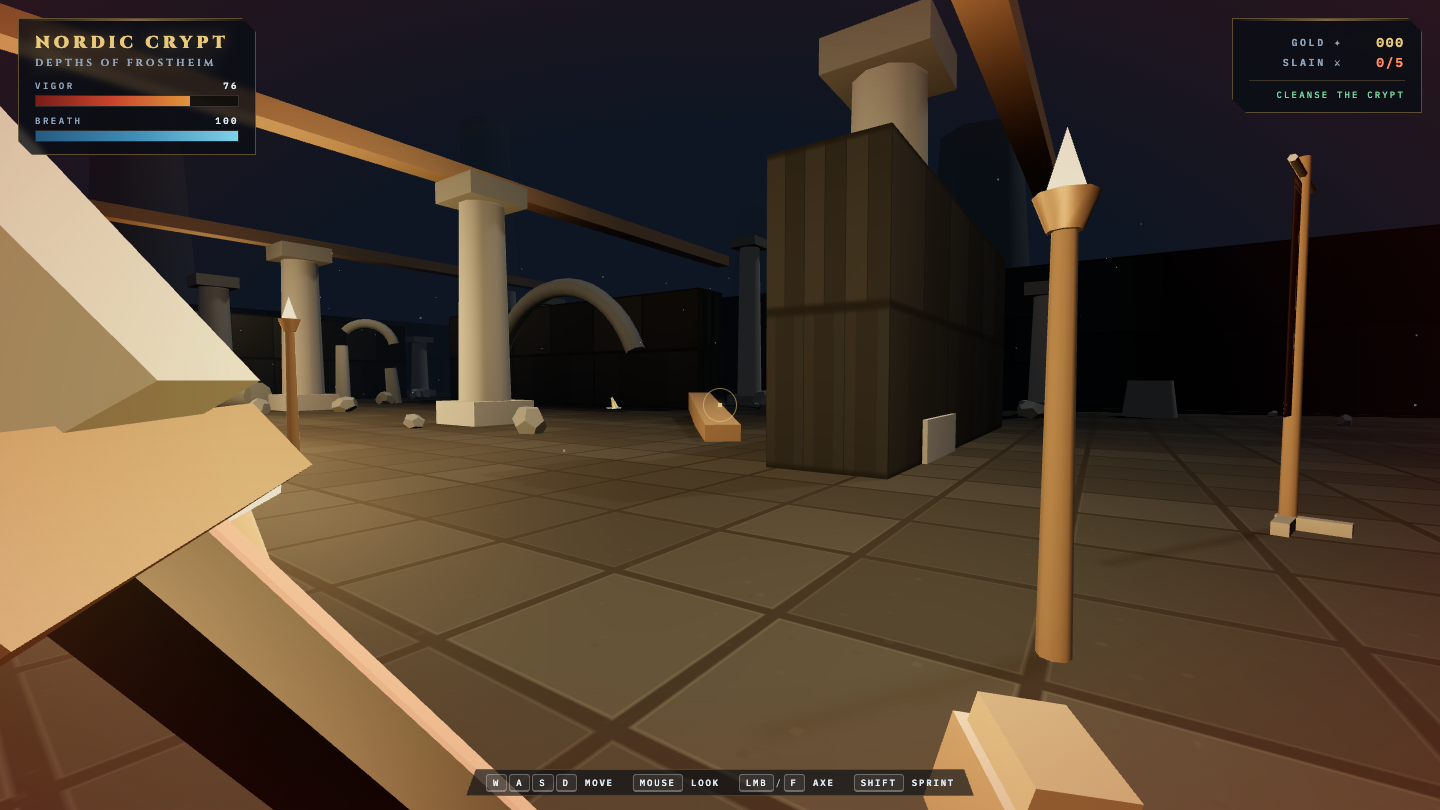











—
—




Game


















—
—
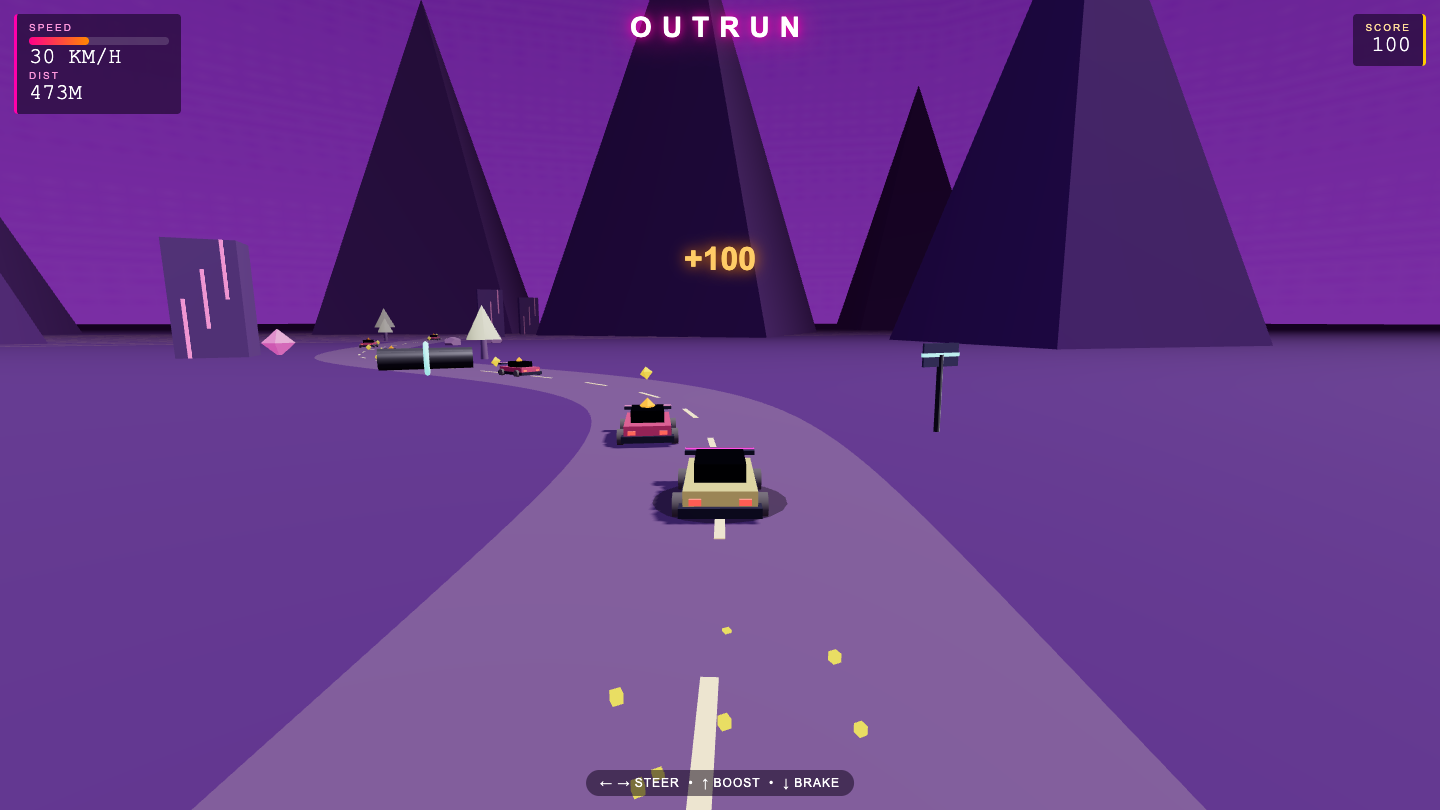




Game
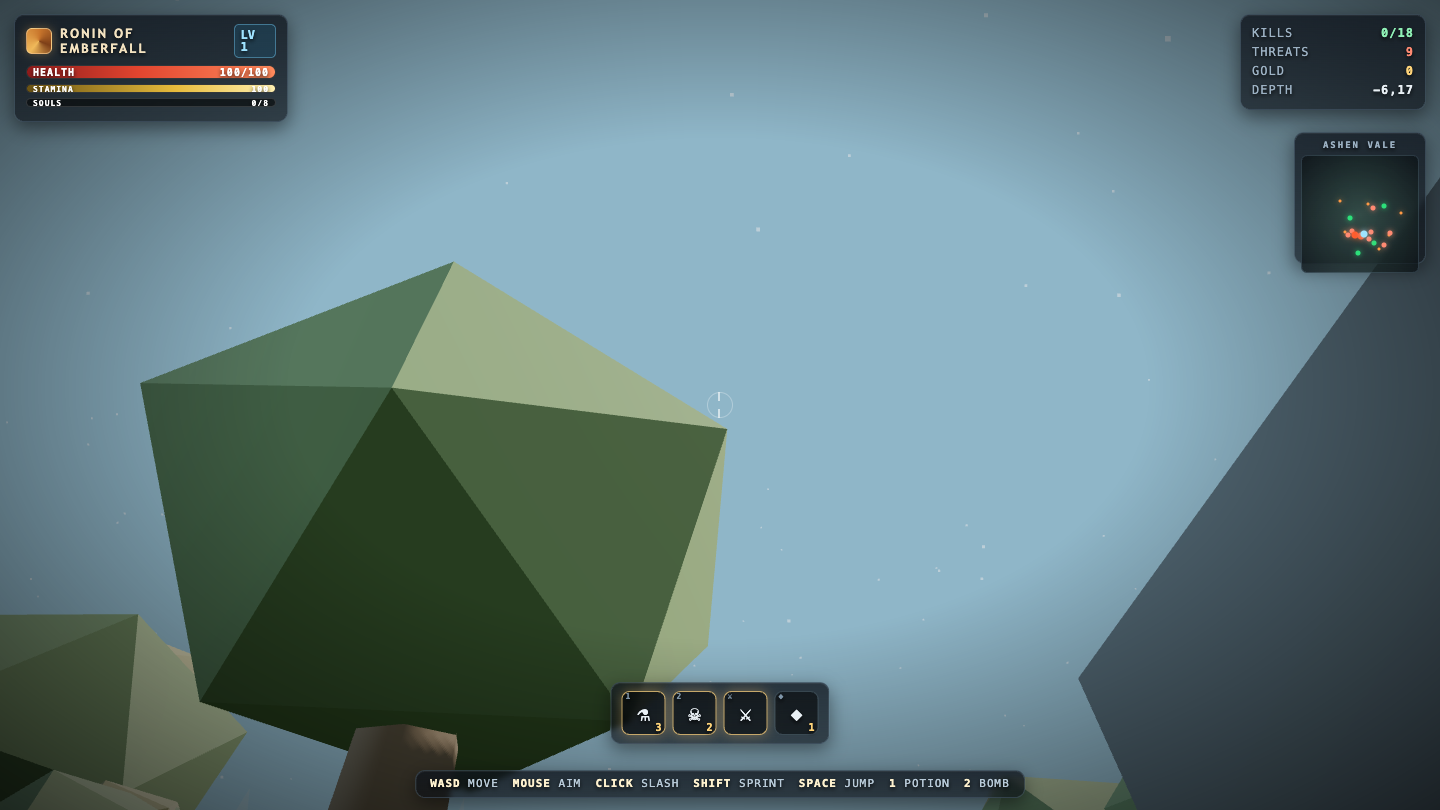

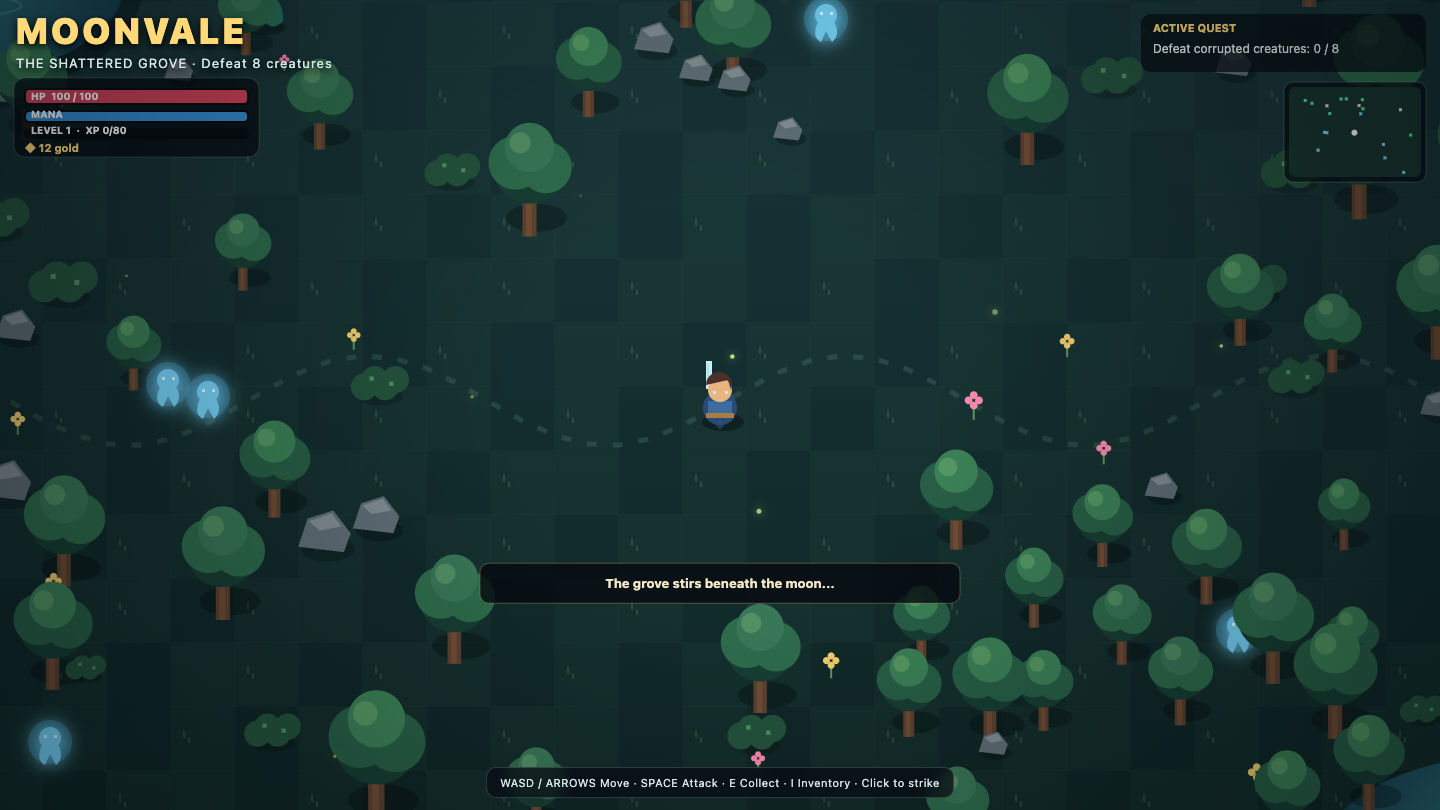




—
—


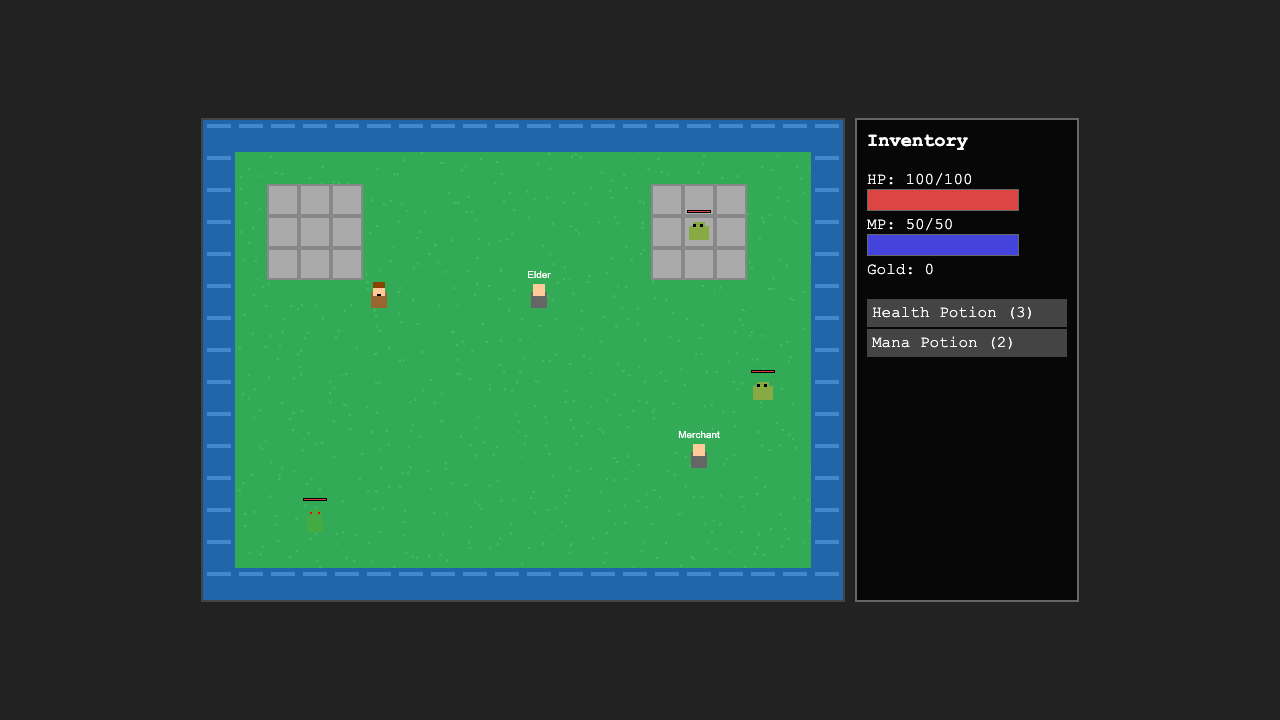
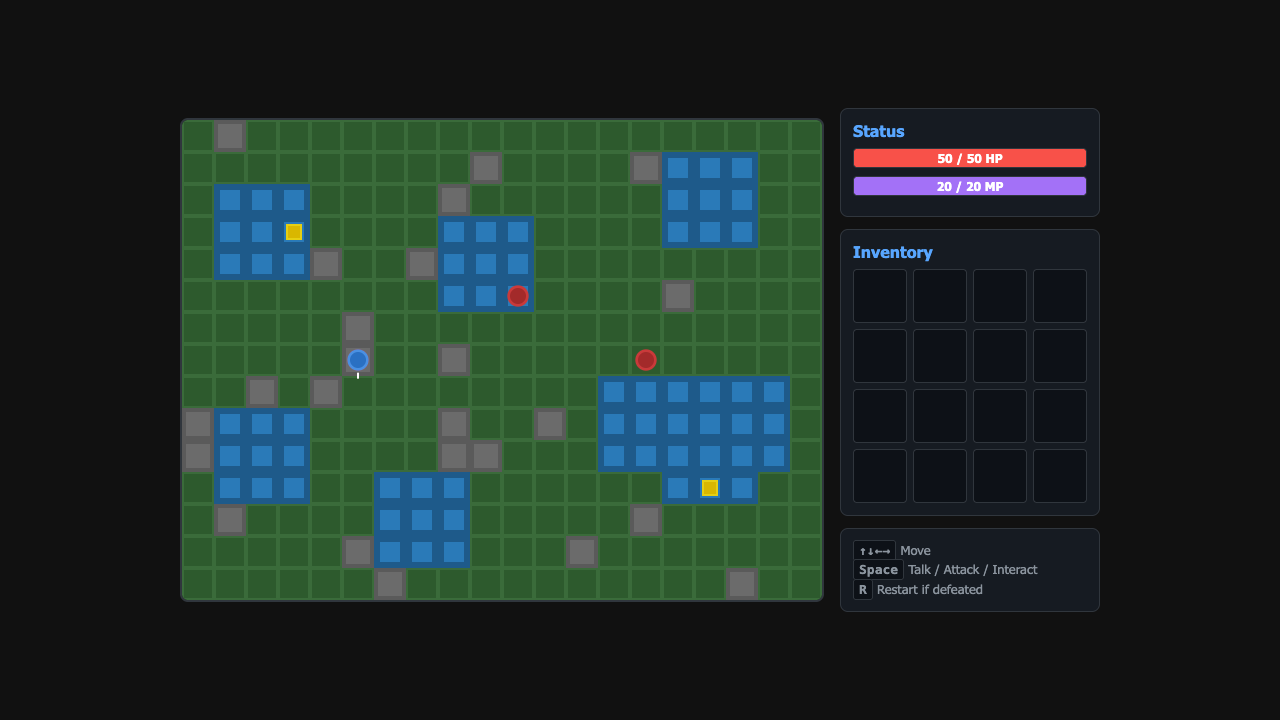
Sim

















—

—
—





Sim

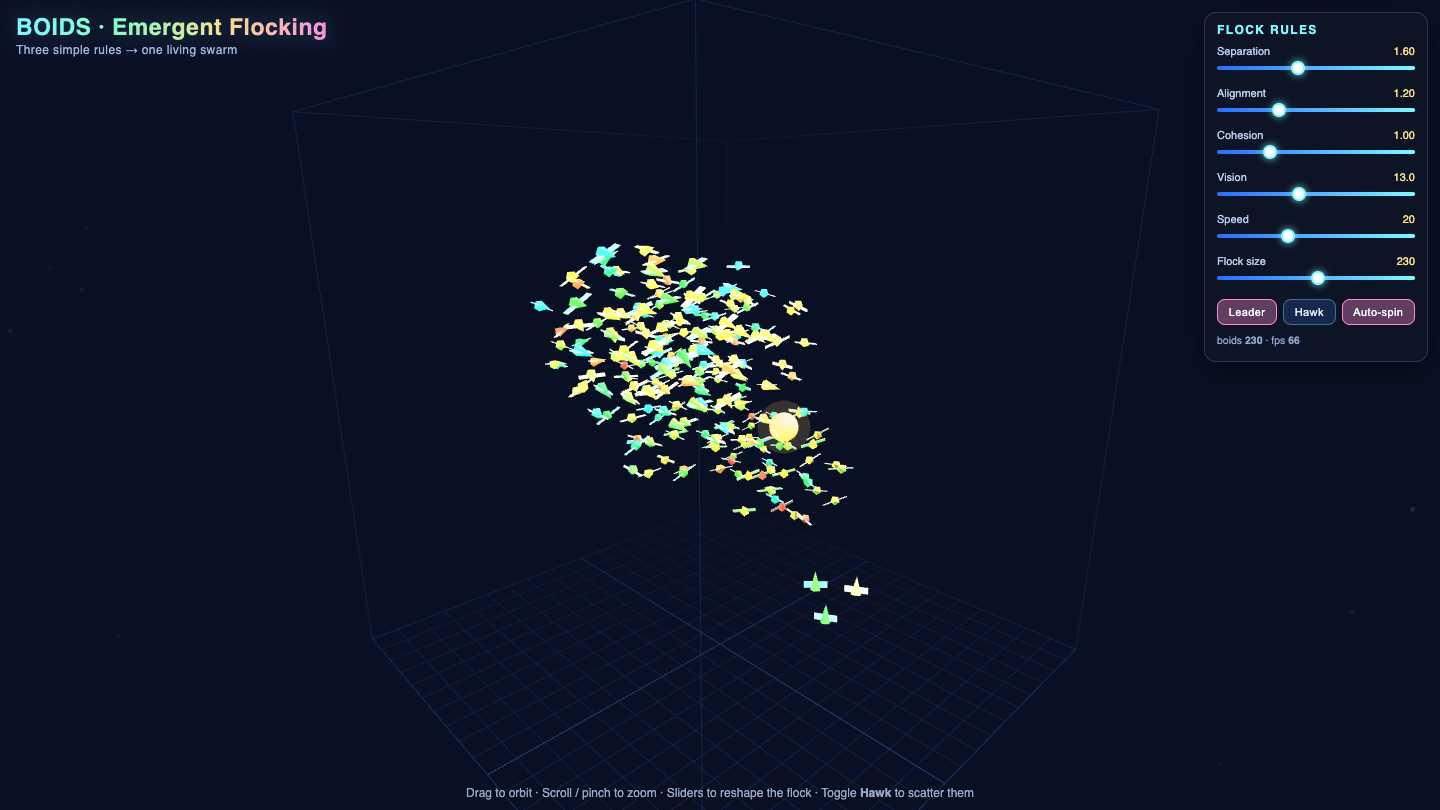
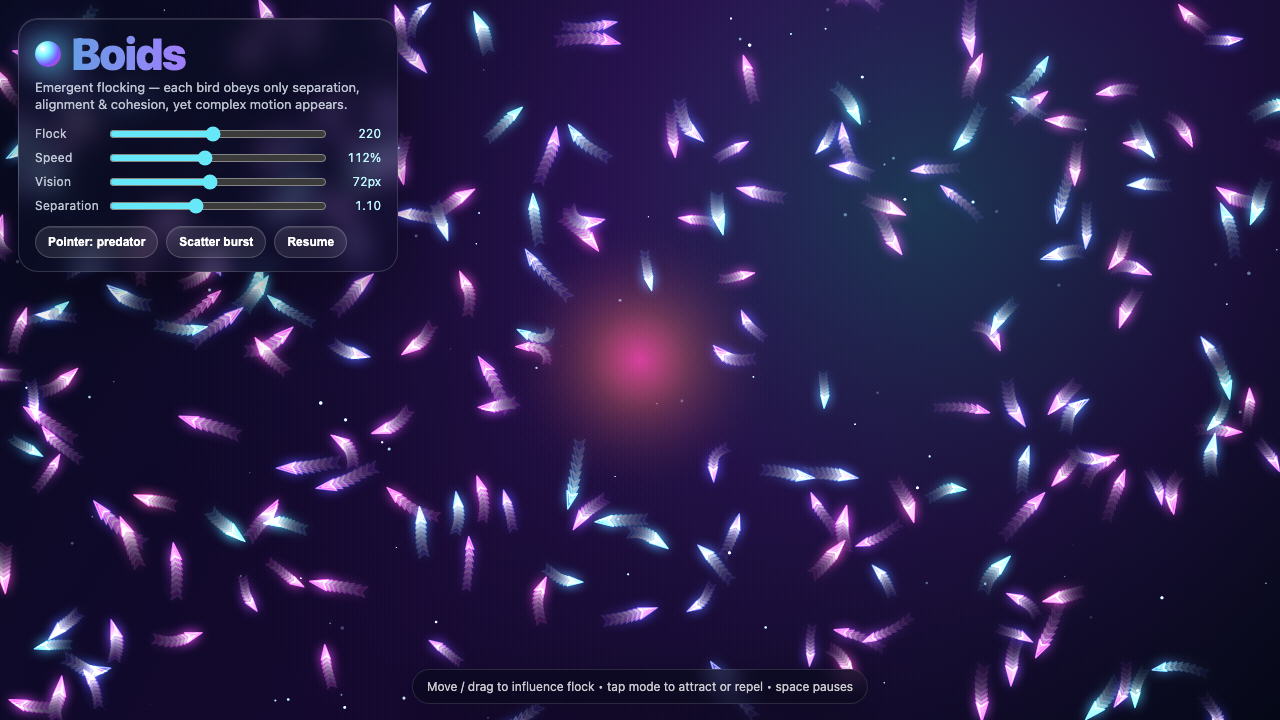






—

—
—




Sim








—

—
—



Visual














—

—
—




Sim











—

—
—



Sim











—

—
—




Sim










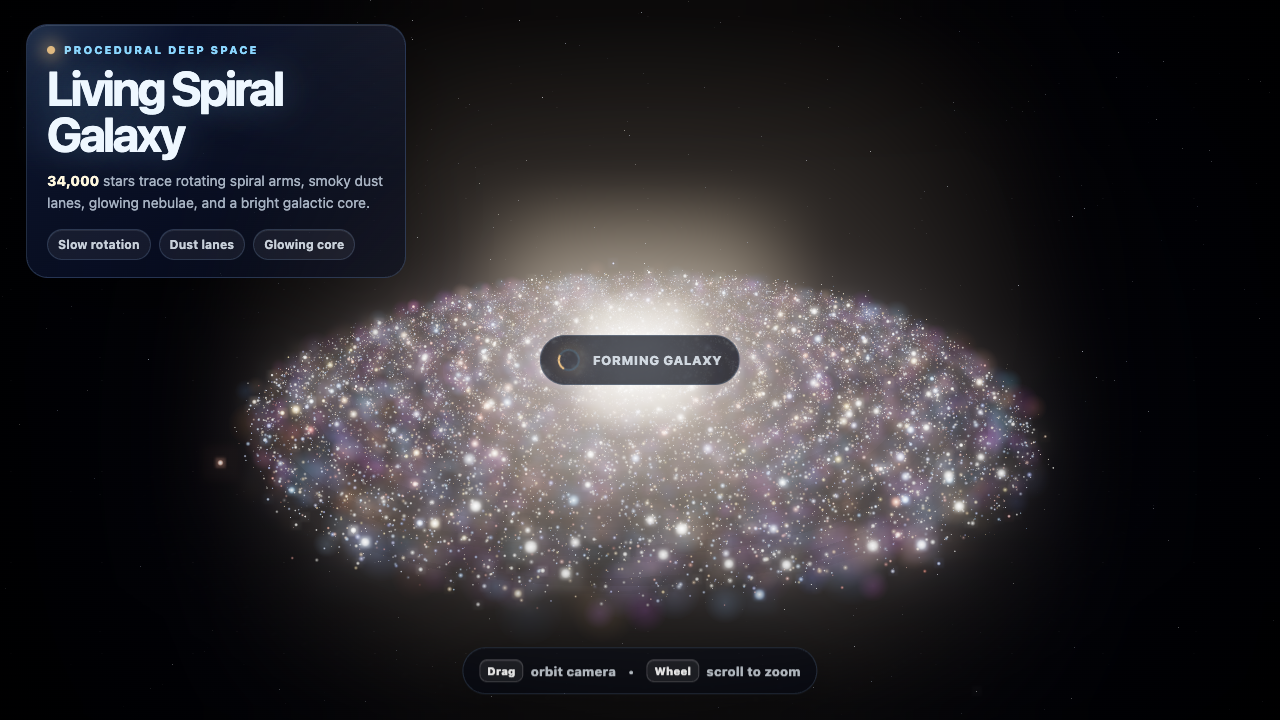



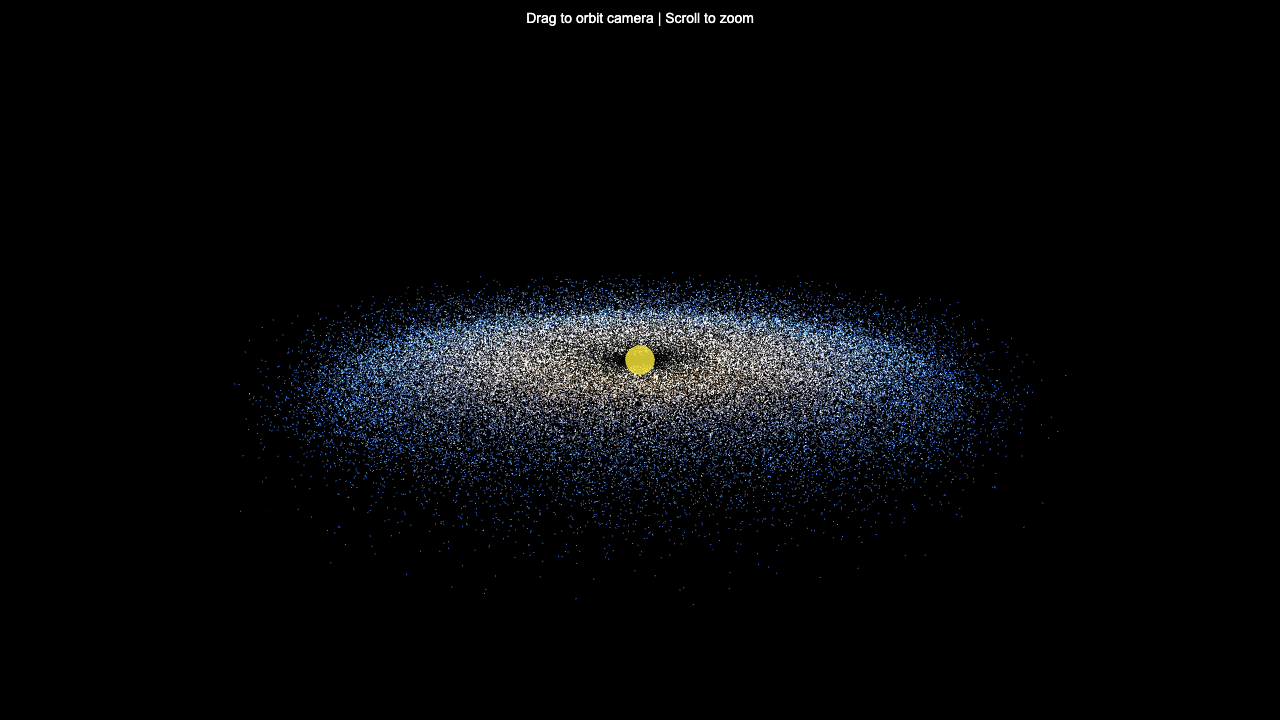
—

—
—





Page
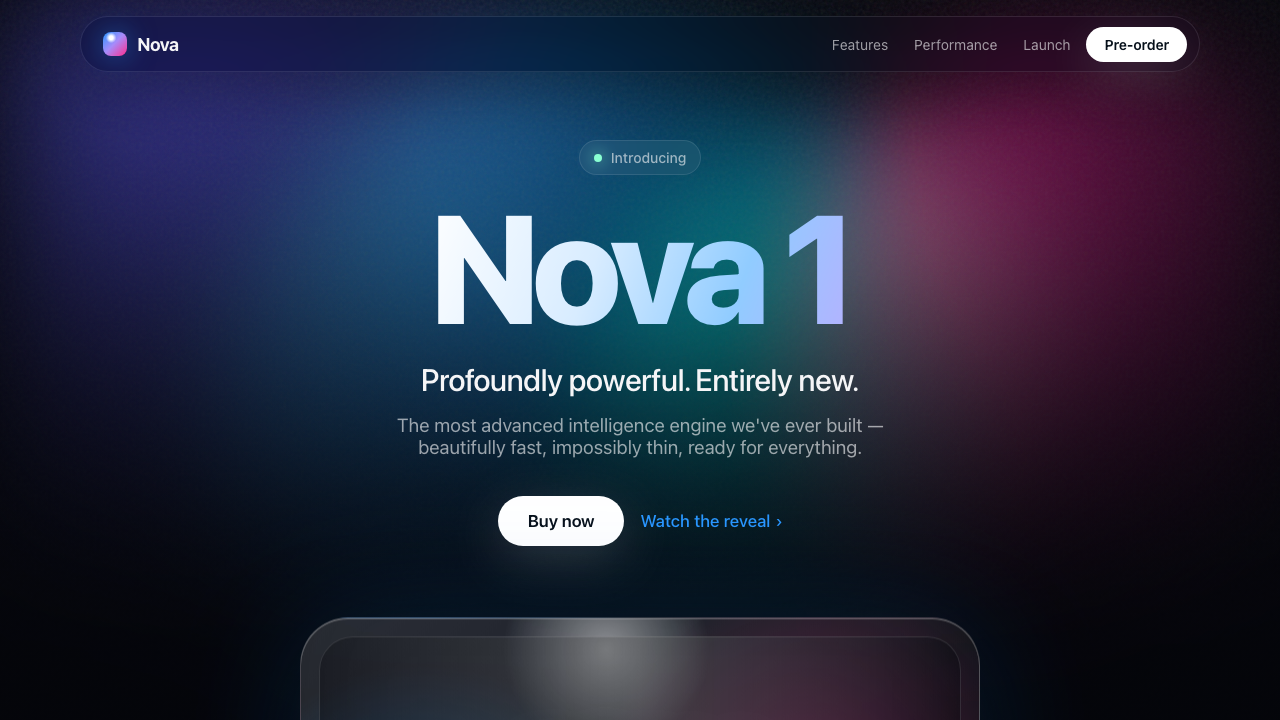

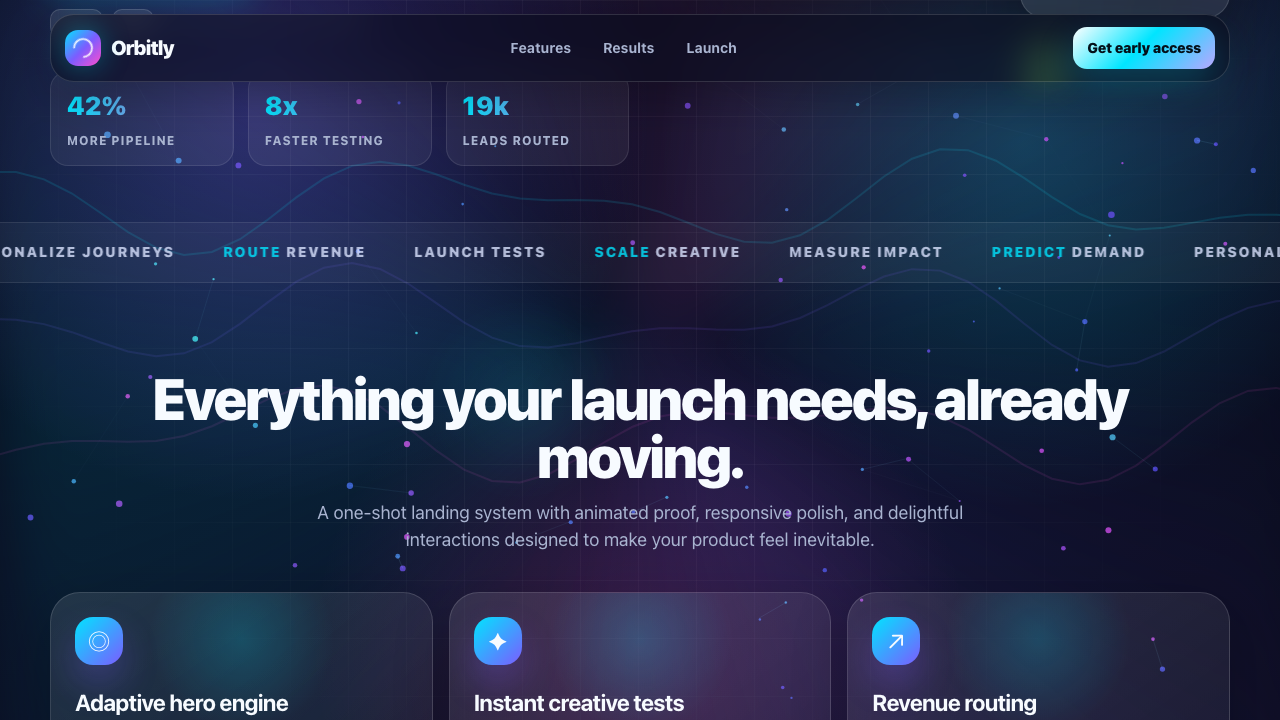

—
—
—




Visual















—

—
—




Visual











—

—
—



Game








—


—
—




Game





—













—
—




Sim






—

—
—



Sim










—

—
—


Visual











—

—
—




Game


—








—
—




Sim






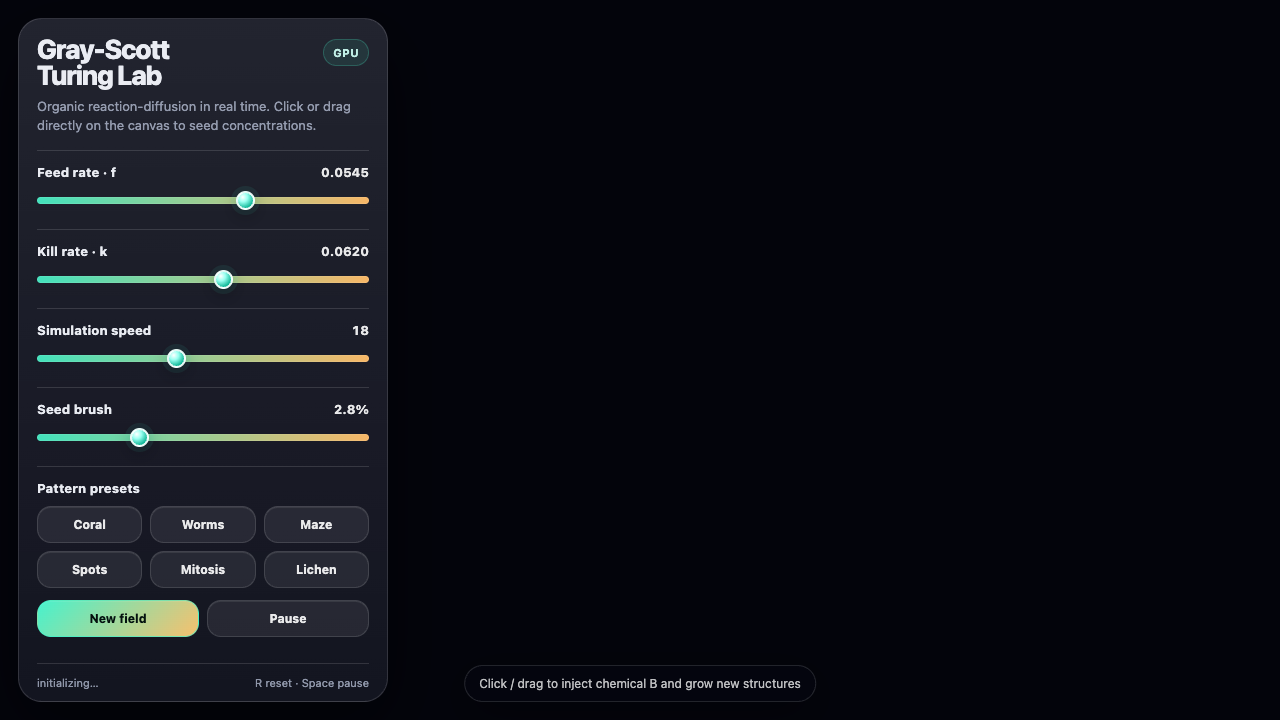

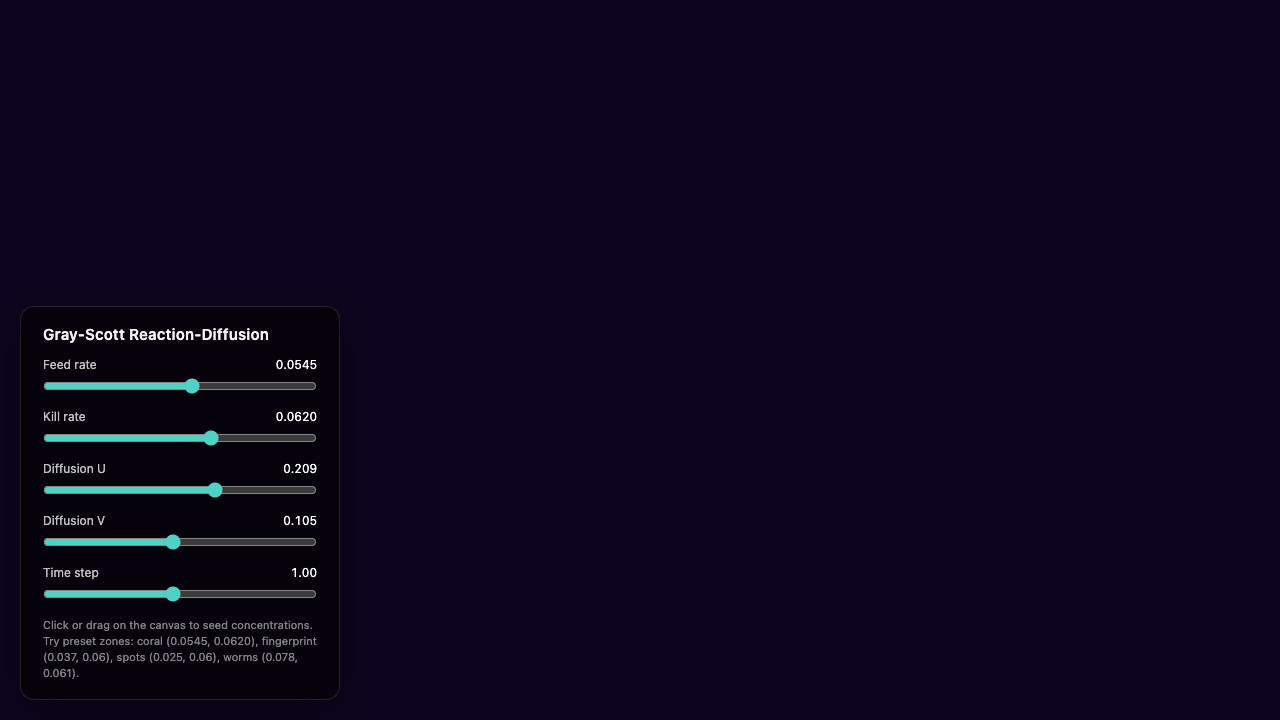



—
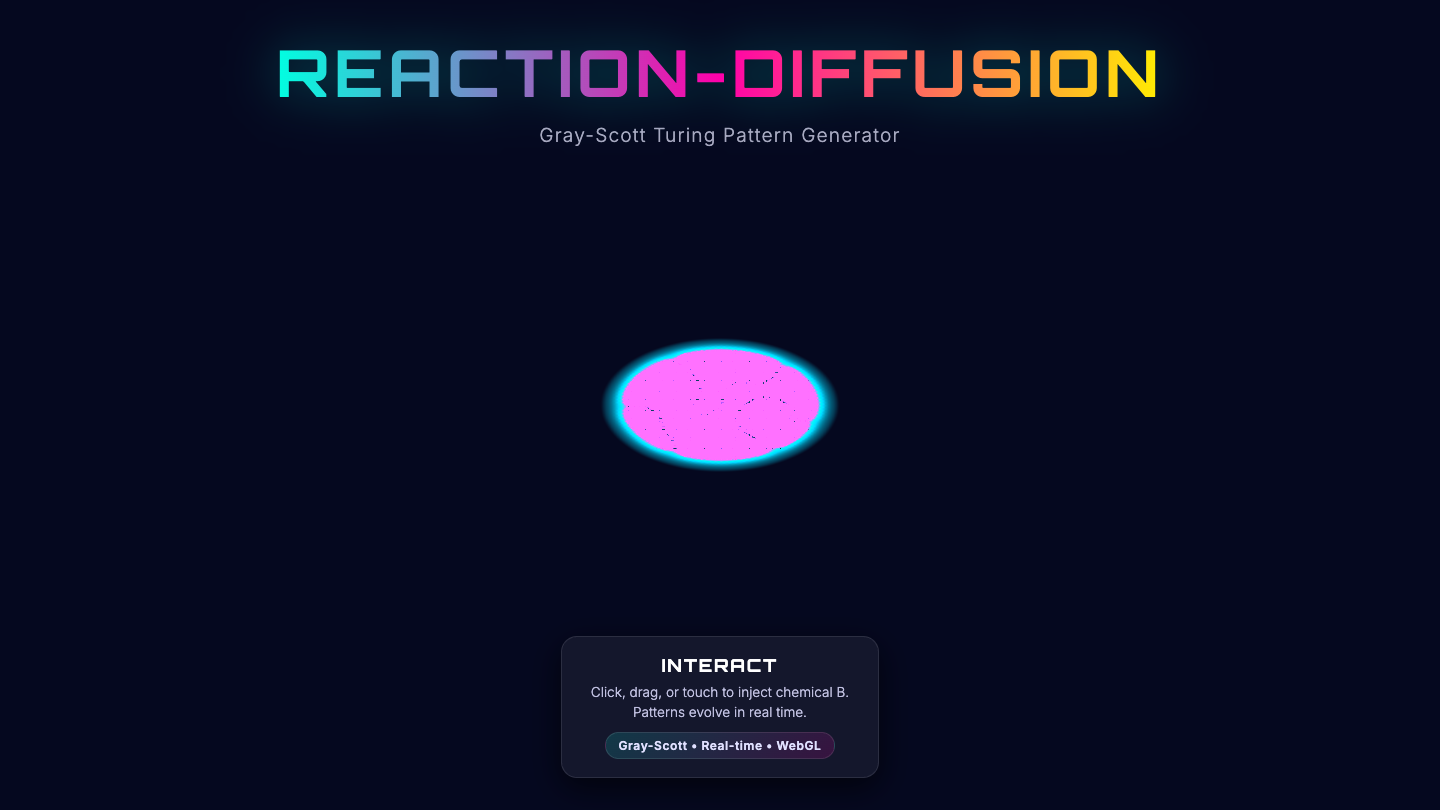
—
—


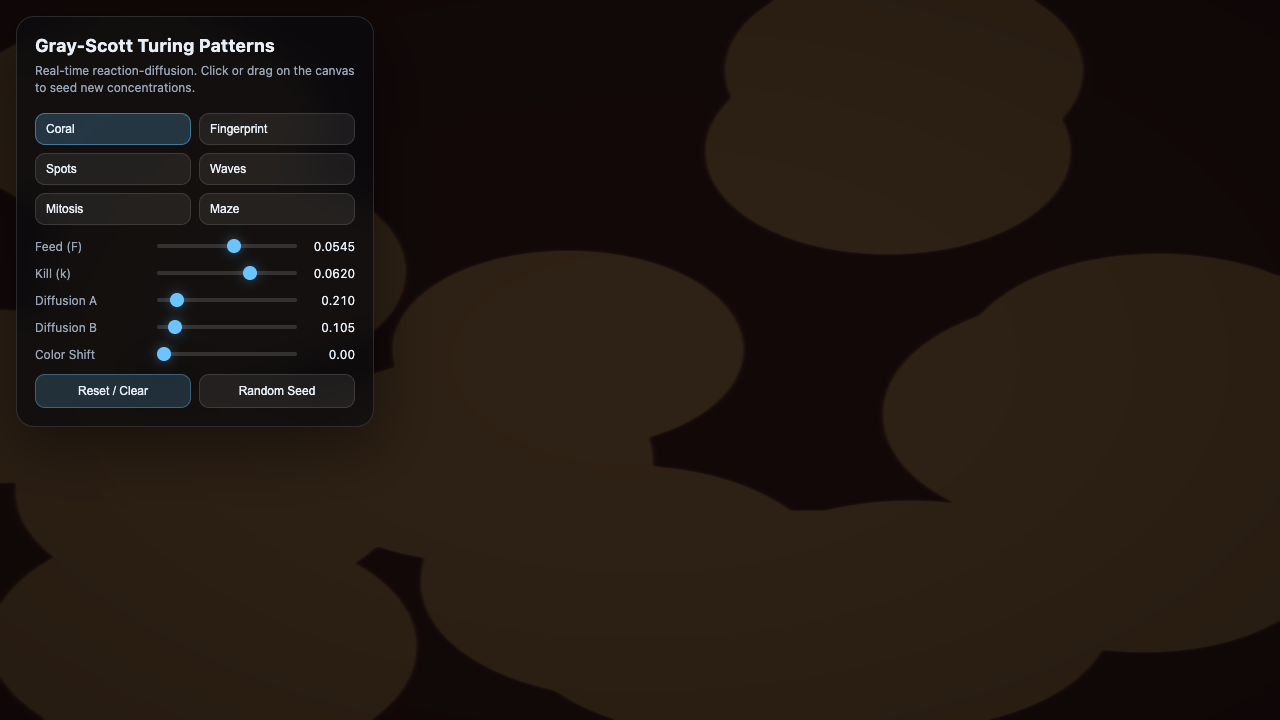


Sim

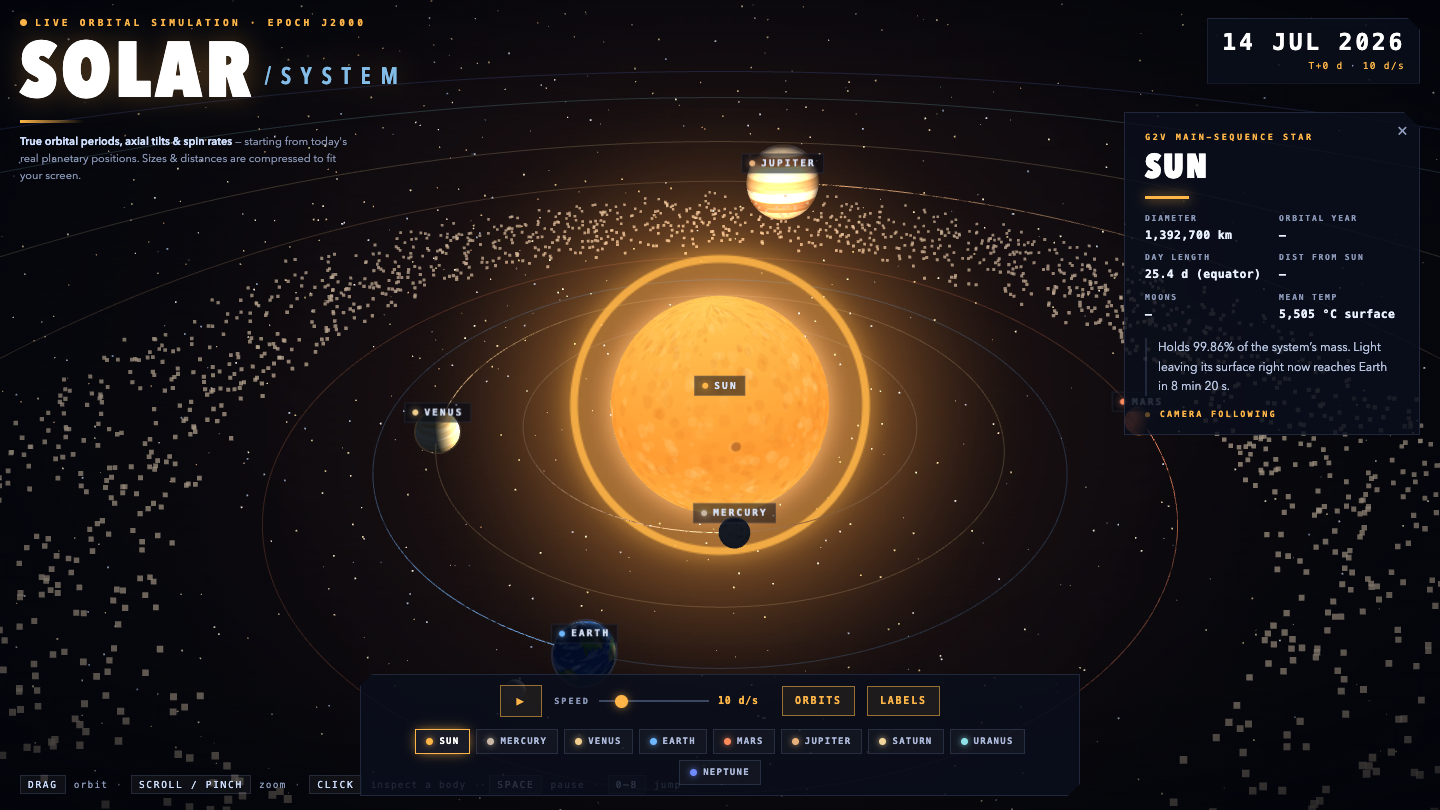

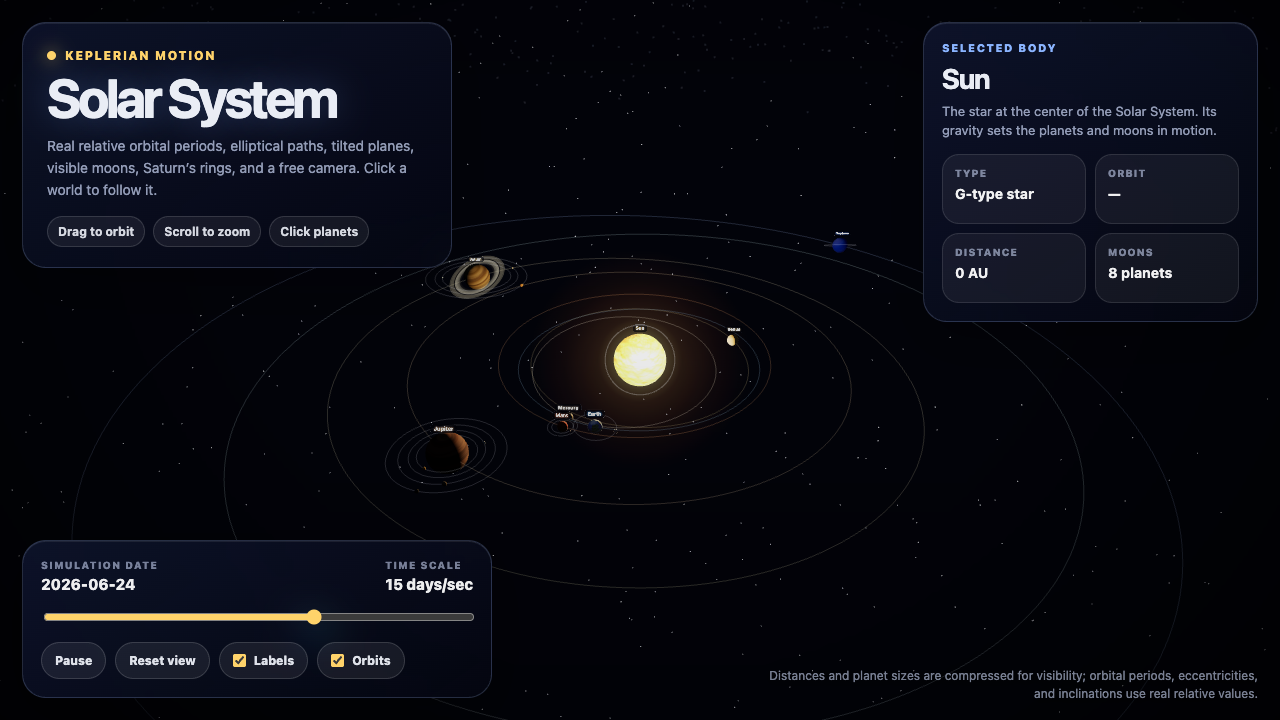
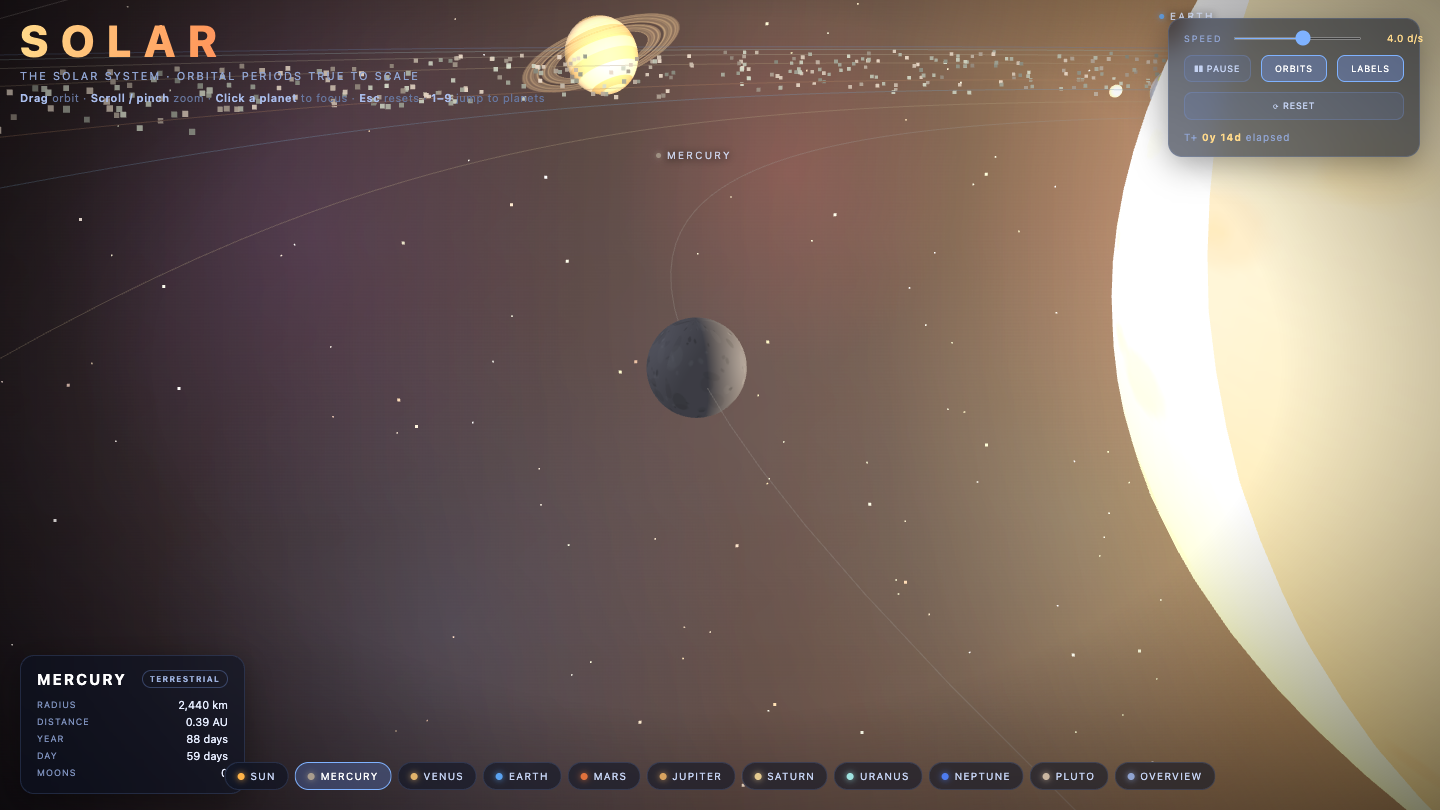


—

—
—
Visual

















—

—
—





Visual











—

—
—




Visual












—

—
—





Visual












—

—
—





Page
—
—
—

Sim













—

—
—




Sim













—

—
—



Game



—


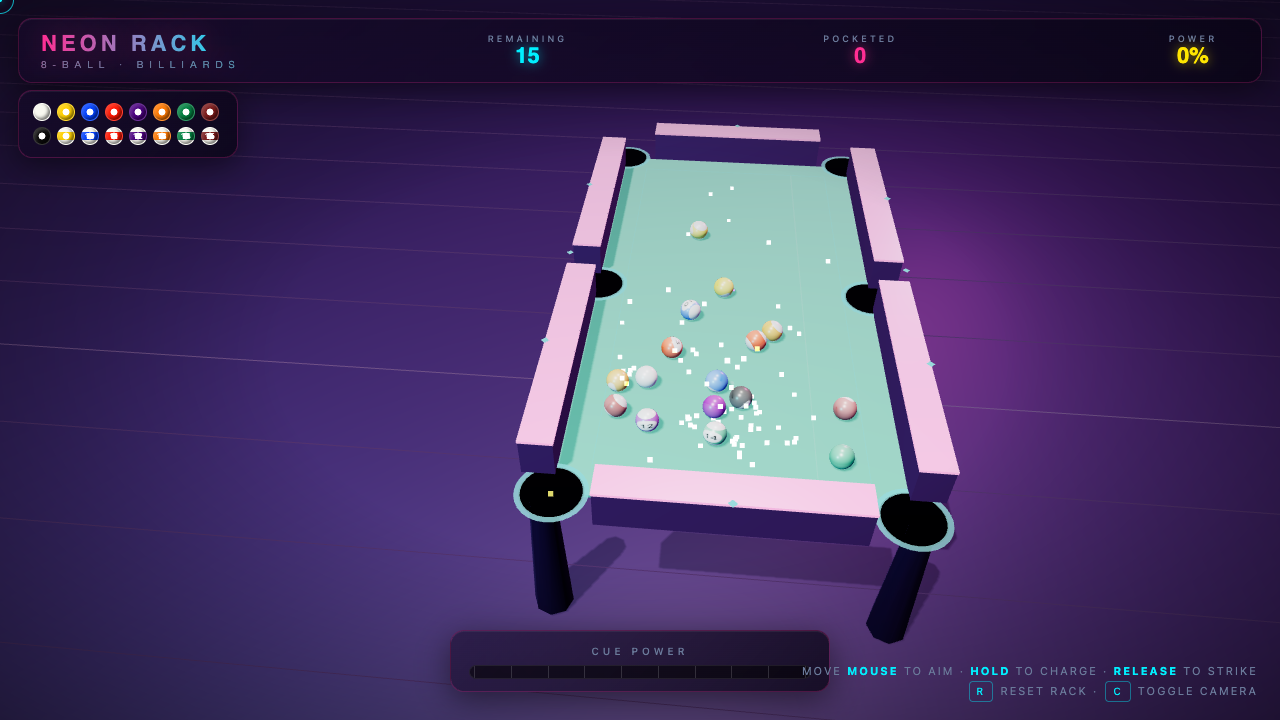
—
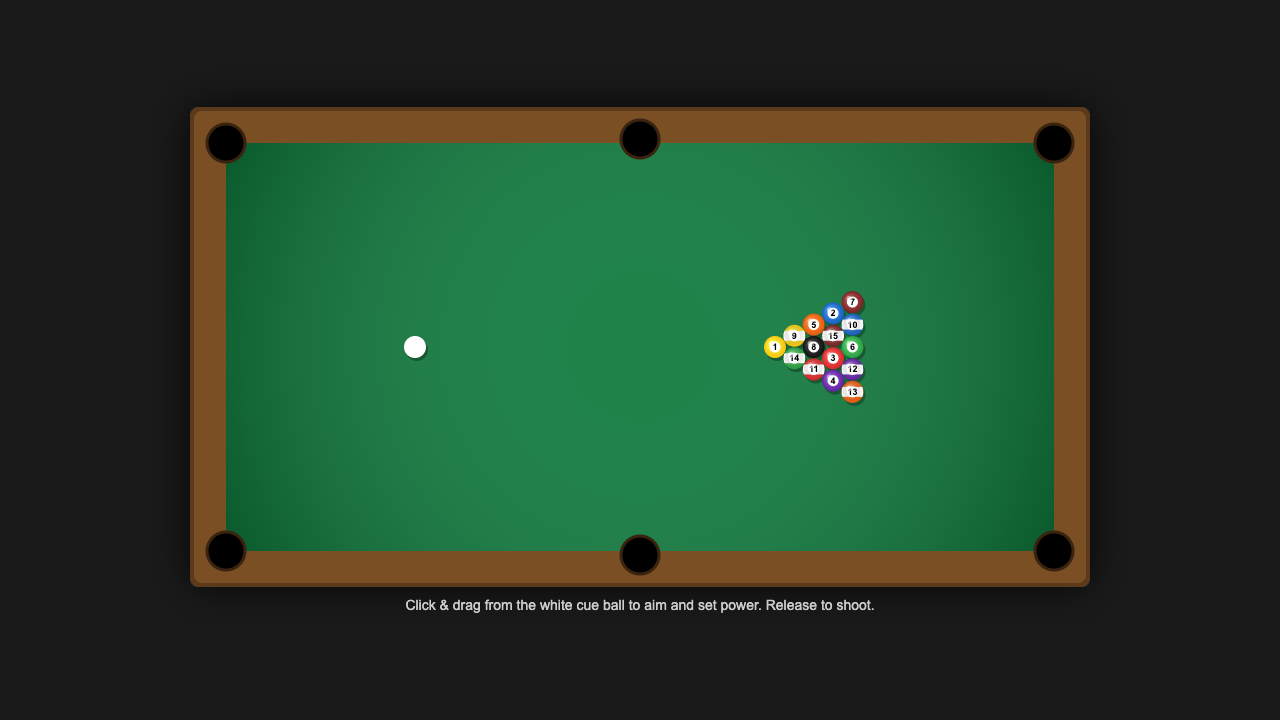
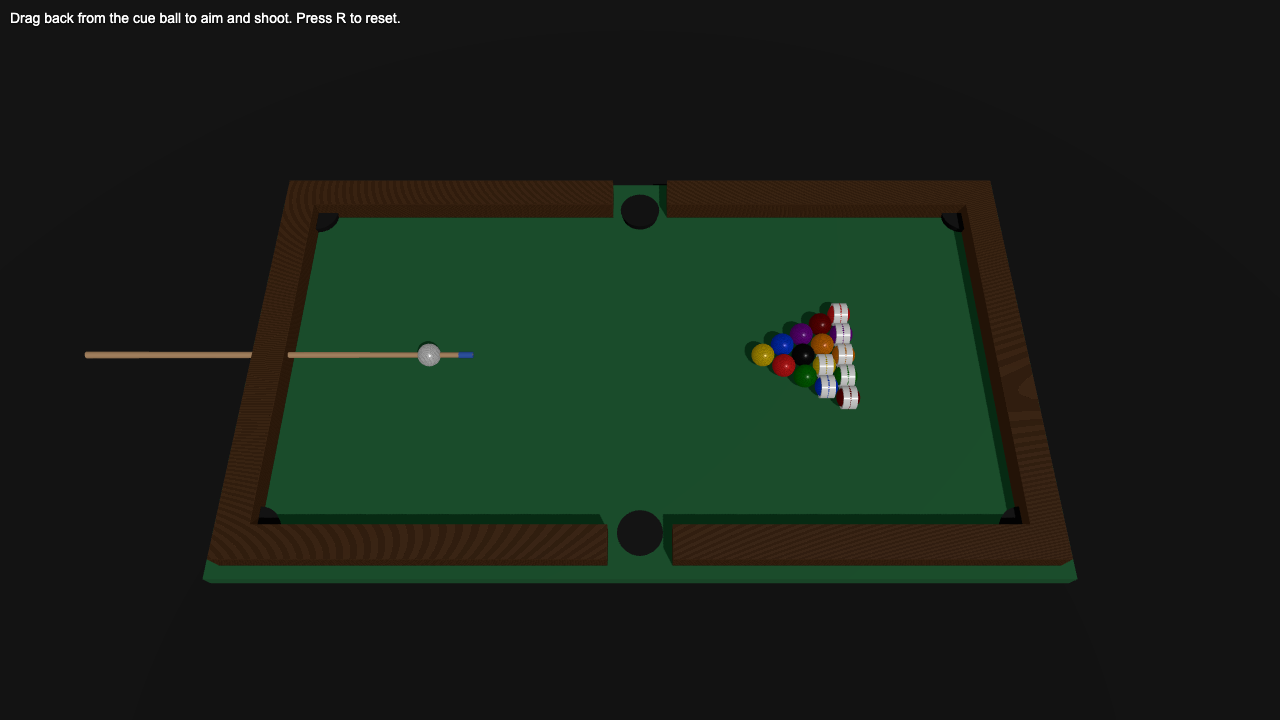
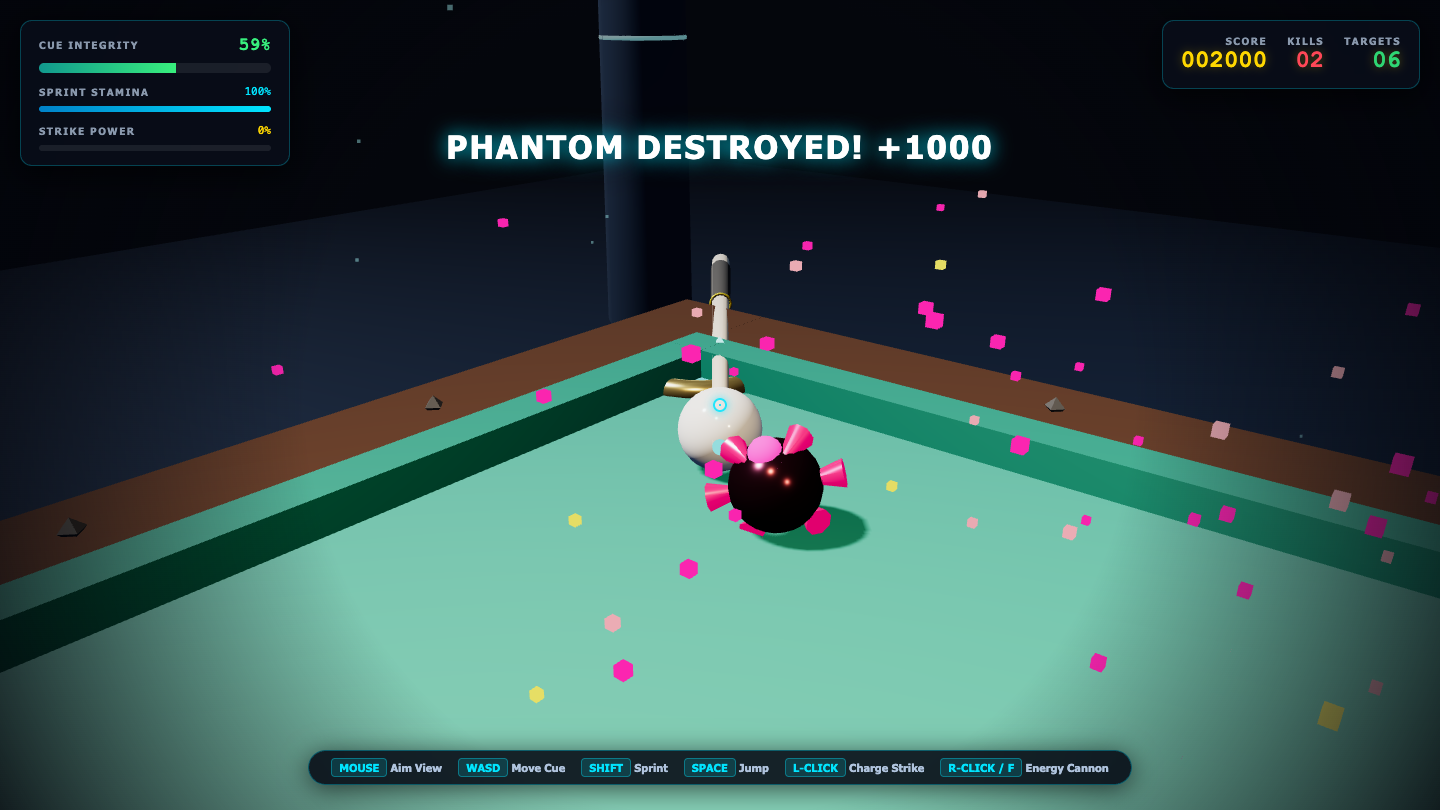




—
—


Other
—
—
—

—
—
—

—
—
—
—

—
—
—

—
—


—
—
—
Other
—

—
—
—
—
—

—
—
—
—
—
—
—

—
—

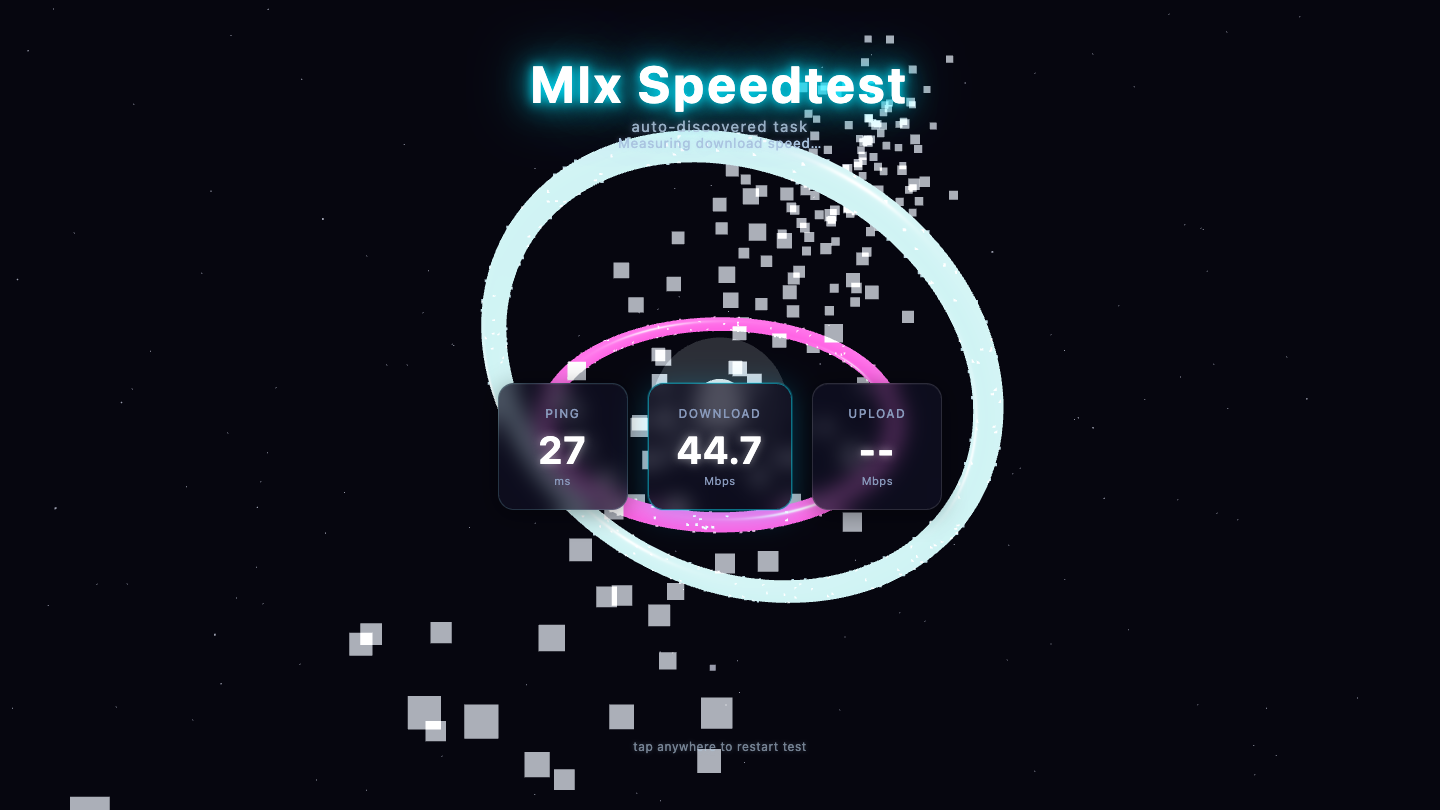
—
—
—
Other
—

—
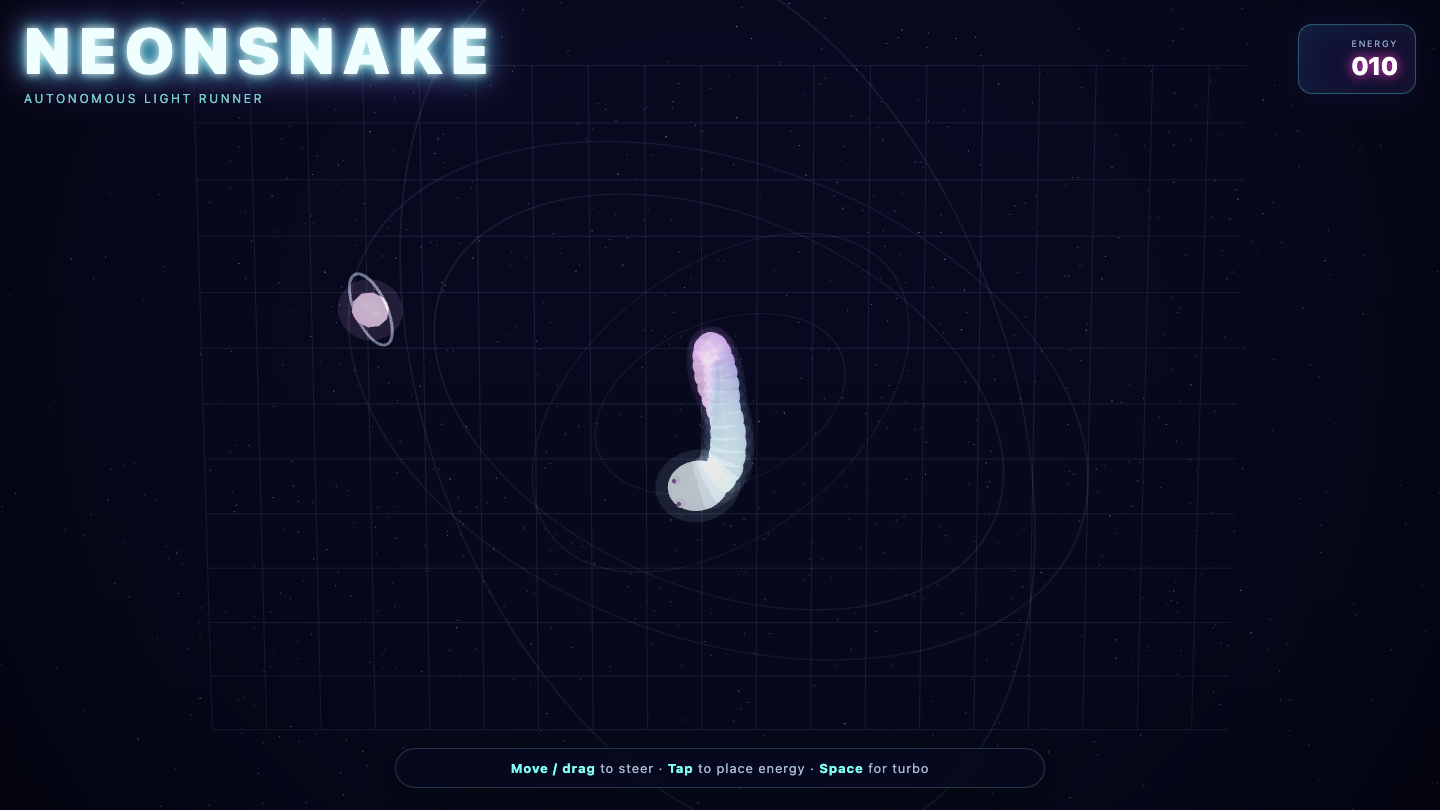
—
—
—
—

—
—
—
—
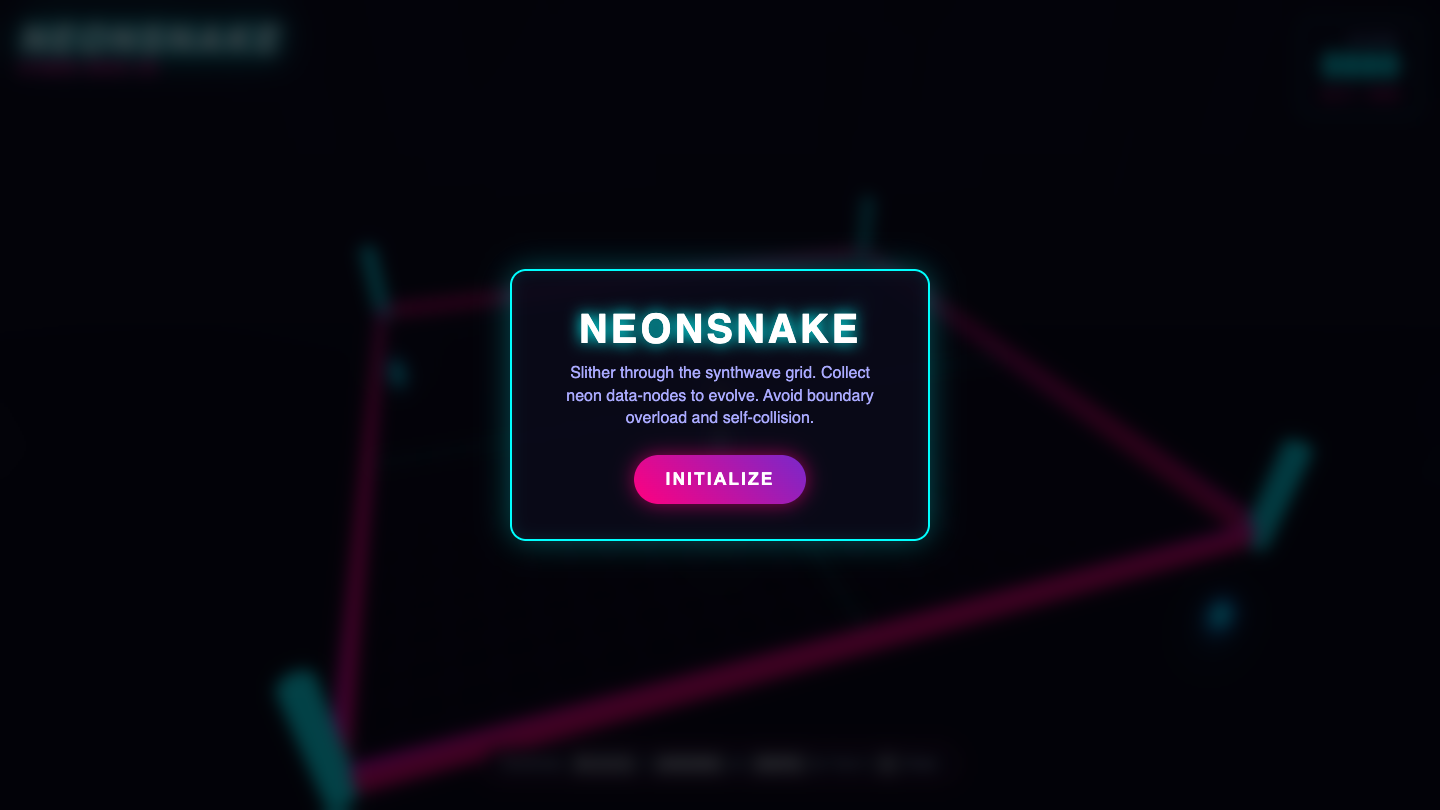
—
—
—
—
—


—
—
—
Showing the 50 most-tested tasks. See all 50 tasks → · Browse all 66 head-to-head comparisons →
The models on the bench
28 AI models tested so far — every frontier release I've put through the same fixed prompt set inside the Agent Operating System. Click any card for the full model review, every demo, and direct head-to-head comparisons. Models without published Julian-graded per-task scores (Fable 5, Mythos 5, Kilo) are listed as unranked until I publish their scored head-to-head guides. Fusion is currently graded by Claude's AI judge (read each demo's HTML, compared to existing scored attempts on the same prompt) — its scores carry a "claude-bench-judge" source label and will be replaced with Julian's own scores when his Fusion head-to-head ships.
Fusion
OpenRouter
Multi-model panel — Fable 5 + GPT-5.5, ensembled. Beats Fable 5 at half the price.
8.59avg
47tasks
21🥇
3🥈
Claude Opus 5
Anthropic
The new Anthropic flagship — benched on all 45 one-shot builds the day it landed.
8.27avg
50tasks
13🥇
7🥈
Hermes MoA
Hermes · Mixture of Agents
A panel of frontier models, merged by a chair. The model doesn't matter — the system does.
8.17avg
47tasks
4🥇
9🥈
GPT-5.6 Sol
OpenAI
OpenAI's flagship — the Sun of the 5.6 lineup.
8.16avg
50tasks
3🥇
8🥈
Claude Fable 5
Anthropic
The newest Anthropic model — first Mythos-class made generally available.
8.10avg
47tasks
4🥇
2🥈
Qwen 3.8
Alibaba
Alibaba's 2.4T flagship — benched through Qoder.
8.10avg
45tasks
8🥇
7🥈
Grok
xAI
Snappy + real-time — the X-native model.
8.09avg
47tasks
5🥇
1🥈
MiniMax M3
MiniMax
1M-context frontier model at $0.30/M tokens — cheapest big-context model on the bench.
7.97avg
47tasks
2🥇
1🥈
Fugu Ultra
Sakana AI
Sakana's multi-agent answer to Fusion — frontier ensemble without single-vendor risk.
7.94avg
42tasks
5🥇
2🥈
Kimi K3
Moonshot AI
Moonshot's 2.8T flagship — 1M context, tuned for long-horizon agent work.
7.89avg
50tasks
8🥇
4🥈
GLM-5.2
Zhipu / Z.ai
The never-forgets agent — 1M context, open weights.
7.77avg
47tasks
5🥇
0🥈
Fugu Mini
Sakana AI
Fugu's fast mini variant — single model, no panel, ~3 min per build.
7.75avg
37tasks
2🥇
0🥈
Opus 4.8
Anthropic
The reasoning king — deepest thinking, premium price.
7.51avg
47tasks
3🥇
1🥈
Kimi K2.7
Moonshot AI
The heavy lifter — frontier coder at flat-rate.
7.46avg
47tasks
1🥇
2🥈
Gemini 3.6 Flash
Google
Google's launch-day Flash — faster, cheaper, fewer tokens.
7.08avg
50tasks
1🥇
2🥈
Claude Sonnet 5
Anthropic
The agentic SWE frontier — 82% SWE-bench Verified, Dev Team mode.
7.01avg
47tasks
0🥇
0🥈
Qwen 3.7
Alibaba
Multilingual open-weights — strong on Chinese reasoning.
7.00avg
47tasks
0🥇
0🥈
Fugu Ultra 1.1
Sakana AI
Sakana's multi-agent orchestrator, v1.1 — routes experts per request.
6.94avg
24tasks
0🥇
1🥈
Inkling
Thinking Machines
A 975B open-weights frontier model — yours to own and run.
6.07avg
50tasks
0🥇
0🥈
LongCat-2.0
Meituan
The open 1.6T MoE that builds — a frontier coder trained on non-Nvidia ASIC superpods.
8.12avg
4tasks
0🥇
0🥈
Hy3
Tencent Hunyuan
Tencent's open-weights coder — Apache-2.0, cheap, beats GLM-5.1 on frontend in Tencent's blind eval.
6.76avg
7tasks
0🥇
0🥈
DeepSeek V4 Flash
DeepSeek
DeepSeek's cheap tier, retrained for agents — same size, sharper loops.
—avg
50tasks
0🥇
0🥈
DeepSeek V4 Pro
DeepSeek
DeepSeek's flagship tier — benched head-to-head against its own cheap Flash.
—avg
50tasks
0🥇
0🥈
Kimi K2.7 · Fast
Moonshot AI
Fast mode — top speed, minimal thinking.
—avg
47tasks
0🥇
0🥈
Kimi K2.7 · No-Think
Moonshot AI
Pure execution mode — no chain of thought.
—avg
47tasks
0🥇
0🥈
Kimi K2.7 · Quality
Moonshot AI
Quality mode — deepest thinking, best output.
—avg
47tasks
0🥇
0🥈
Claude Mythos 5
Anthropic
Restricted-access flagship — vetted partners only.
—avg
0tasks
0🥇
0🥈
Kilo Code
Kilo
Fable 5-class intelligence at ~59% less. The split-the-cost play.
—avg
0tasks
0🥇
0🥈
What is Goldie Bench?
Goldie Bench is a one-shot AI model leaderboard. Every model gets the same fixed prompt, single HTML file out, live on the page. No iteration. No "best of N." What came out on the first run is what's on the matrix — and I score each result 0–10 on whether it ran, how close it hit the brief, and how good it looked.
Who I am — and why I built this.

I'm Julian Goldie. I run Goldie Agency — a 7-figure SEO + link-building agency with 70+ employees that ships AI-driven work for clients every day. I built the Agent Operating System — a dashboard where my AI crew dispatches frontier models from one shared kanban — so I can run it all. The bench is a slice of my actual daily work, not a synthetic benchmark.
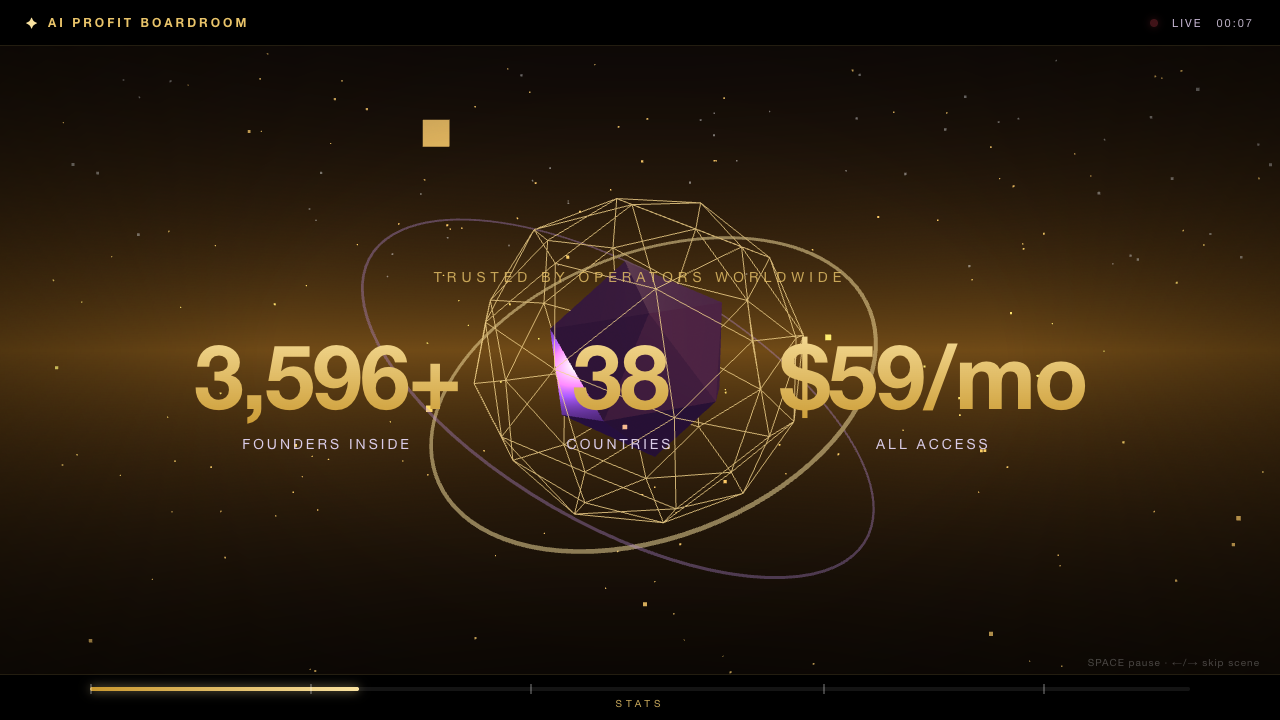
I also run the AI Profit Boardroom (4,000+ founders, 38 countries), publish daily AI + SEO tutorials on my YouTube channel (400k subscribers), post on X (163k followers), and wrote Link Building Mastery on Amazon. Every model on this leaderboard is one I dispatched personally from inside Agent OS.
Why I built this AI model leaderboard
Standard AI benchmarks — MMLU, HumanEval, SWE-bench, LiveCodeBench — measure narrow things. Did the model output text that matches an expected answer? Did the code compile? Did the patch pass the test? These benchmarks are useful for vendors who want to make a number go up. They have almost nothing to do with whether a frontier model can ship a thing on the first prompt.
The buyer audience for these models — founders, builders, indie devs, agencies, anyone running AI agents day to day — needs a different question answered: can you ask the model for a playable game, a working simulation, a deployable page, and have it ship in one prompt? That's the test that decides whether you'd wire the model into your stack.
Goldie Bench is that test. Same fixed prompt for every model. Single HTML out. Live on the page. Real 0–10 score from me, posted publicly with the reasoning. No vendor pays me. No score gets buried.
How I test — the methodology in 60 seconds
- I pick a creative coding prompt a frontier AI model should be able to ship in one shot — raycaster maze, fluid sim, neon city flythrough, top-down RPG, landing page.
- I dispatch the exact same prompt to each model from the kanban inside the Agent Operating System. No system-prompt cheats, no few-shot tricks.
- I save whatever .html file the model produces on the first run. No iteration. No coaching.
- I score each result 0–10 on three axes: did it run, did it hit the brief, did it look good.
- I publish the scores publicly in the source comparison guides on agentos.guide — and that's the data behind every cell on this page.
Full data provenance on the methodology page.
What makes Goldie Bench different from other AI model leaderboards
- Live demos, not numbers in a table. Click any cell on the matrix and the model's actual one-shot HTML opens in a new tab. You don't have to trust my score — you can play the result and form your own opinion.
- Real 0–10 scores from a working operator, not auto-evaluated against a reference. I run the models inside the same Agent OS my 4,000+ community uses daily, and I score on what would actually ship.
- Same prompt across every model — no per-vendor handicapping. Every model sees the exact same string.
- Publicly sourced data. Every score traces back to a published comparison guide on agentos.guide. Cells without a score are honestly marked as unranked.
- Updated daily-ish. When a new model ships, I run the same prompts through it on camera (you can watch on YouTube, 400k+ subscribers) and the bench updates.
FAQ — about the bench
What's the best AI model right now?
Across 851 scored cells from my source guides, Opus 4.8 tops the leaderboard at 8.46/10 average — most consistent across game-feel, raycasters, and one-shot reasoning. GLM-5.2 is the open-weights challenger at 8.23/10 with the prettiest visual builds. Pick by use case — see Opus 4.8 vs GLM-5.2 for the head-to-head.
Is Goldie Bench the same as the LMArena, Hugging Face, or Chatbot Arena leaderboard?
No. Those rank models on human-preference Elo votes or quiz-style benchmarks. Goldie Bench ranks on a single fixed creative-coding task per cell — same prompt, one shot, scored 0–10 by me. Different methodology, different answer.
How often do new models get added?
Whenever a new frontier release lands. I usually wire it into the Agent OS the same week, run the fixed prompt set through it on camera, and the bench updates. Recent additions: GLM-5.2, Kimi K2.7, Qwen 3.7.
Can I add a model or task?
Ideas land best inside the AI Profit Boardroom community. Members propose tasks, I test, scores get added to the bench.
Are these scores affiliate-driven or vendor-sponsored?
No. No vendor pays me. No score is gated. The Agent OS that runs these tests is built and maintained by me; the community that powers the workflow lives inside AIPB. That's the only commercial layer on this site.
The same stack Julian uses
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 4,000+ founders shipping with it every day all live inside the AI Profit Boardroom.
4,000+founders
258documented wins
38countries
$59/momonthly