Claude Sonnet 5
The agentic SWE frontier — 82% SWE-bench Verified, Dev Team mode.
Reference benchmarks for Claude Sonnet 5
These are external benchmarks I pulled from the source comparison guides on agentos.guide — SWE-bench Verified, DRACO, Kilo plan rubric, build-time measurements, vendor-reported coding scores. They are not goldiebench medal scores (those come only from same-prompt one-shot creative coding tasks in the matrix). I surface them here so the spec sheet for Claude Sonnet 5 is honest about what's measured.
What is Claude Sonnet 5?
Claude Sonnet 5 is the Anthropic frontier model with a 1,000,000 tokens context window, released 2026-06-30. Tagline: The agentic SWE frontier — 82% SWE-bench Verified, Dev Team mode.. Official source: anthropic.com.
Pricing detail. $3.00 input / $15.00 output per million tokens; introductory $2.00/$10.00 through 2026-08-31.
How I use it inside the Agent OS. Reach for it in Agent OS when the job is iterative, tool-using software engineering. For one-shot visual builds, GLM 5.2 (free) beat it 4-1 here.
What I built with Claude Sonnet 5
Every model on Goldie Bench gets the same fixed prompt set — one shot, single HTML file out — and I score the result 0–10 inside the Agent Operating System. Here's what Claude Sonnet 5 shipped on the bench: 42 one-shot demos across 1,000,000 tokens of context. Of those, 42 are scored against the field with my honest 0–10 from the source guides at agentos.guide.
Strengths
- 82.1% SWE-bench Verified — first model past 80% on real GitHub-issue repair
- Dev Team multi-agent mode + 1M context for repo-level agentic work
- Precision on hard logic — won the raycaster the open-weight field kept botching
Trade-offs
- One-shot creative-visual builds trail GLM 5.2 here (lost 4 of 5) — no iteration to catch its own bugs
- A temporal-dead-zone bug blanked its N-body orbit sim on the first shot
Best for
- Agentic software engineering — write / run / test / fix loops on real repos
- Repo-level reasoning across a 1M-token context (Dev Team multi-agent mode)
- Precise logic — raycasters, physics — where one-shot open models slip
Every demo by Claude Sonnet 5
42 live demos, sorted by category. Click any tile to play the actual one-shot result. Verdicts and 0–10 scores are pulled from the source guides where I posted them publicly.
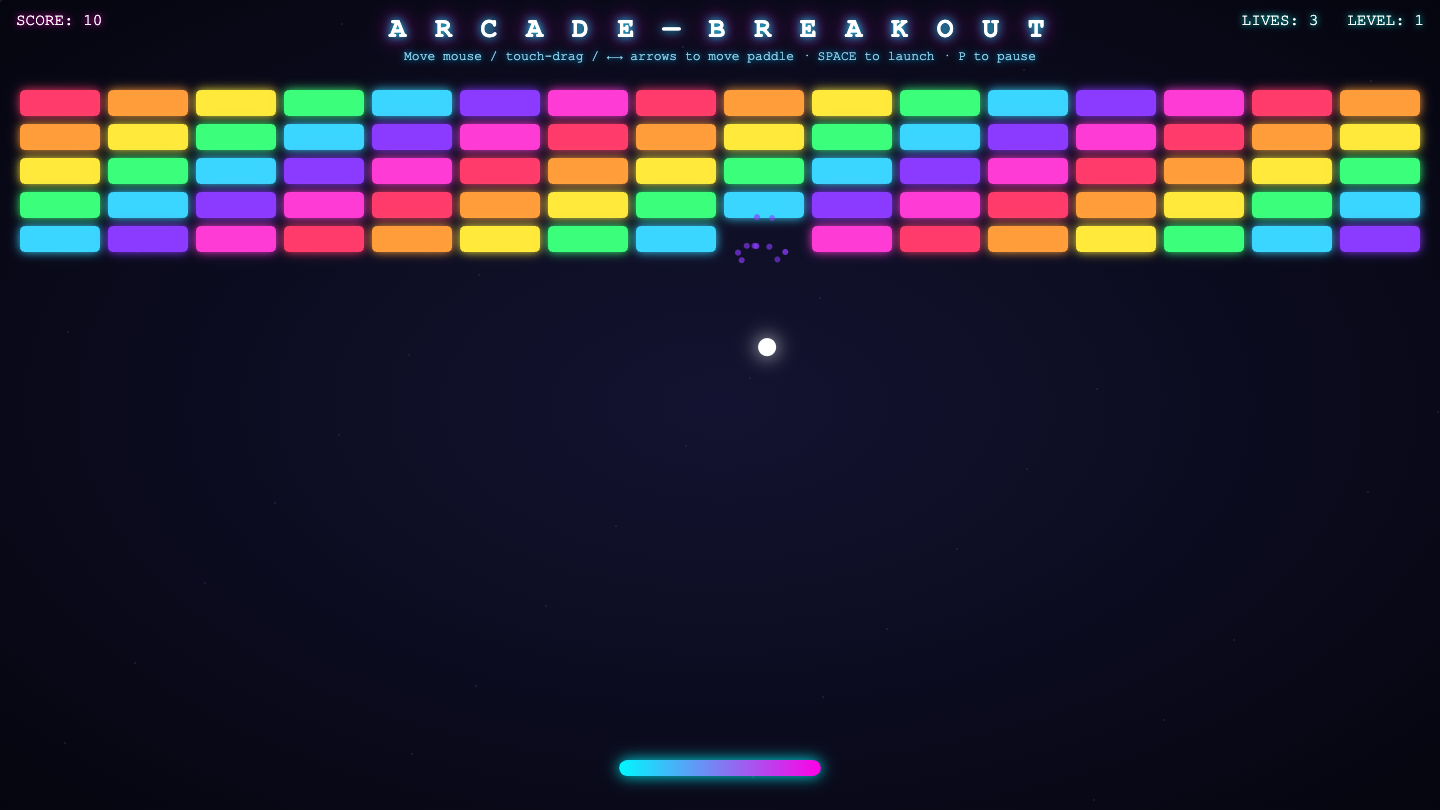 ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE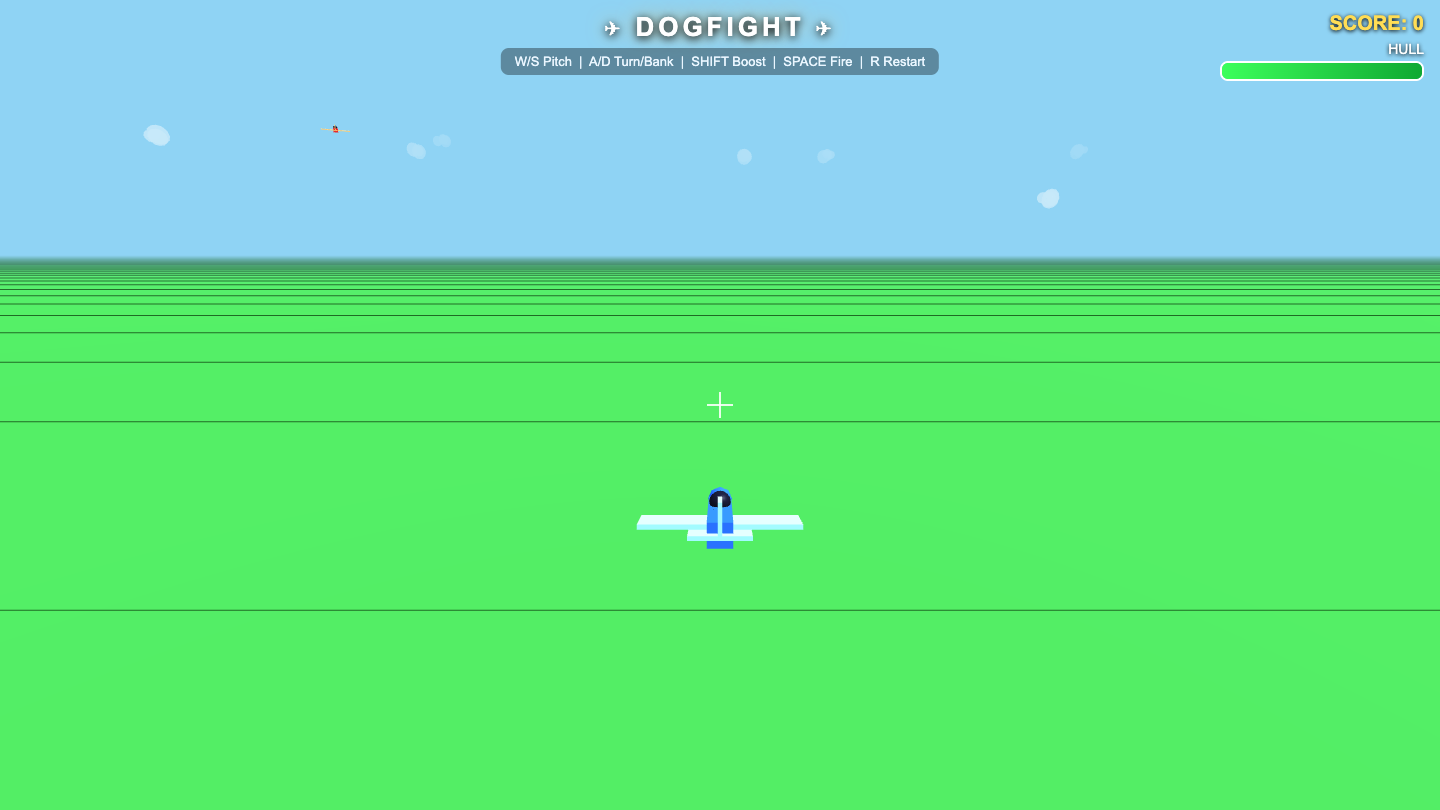 ▶ LIVE
▶ LIVE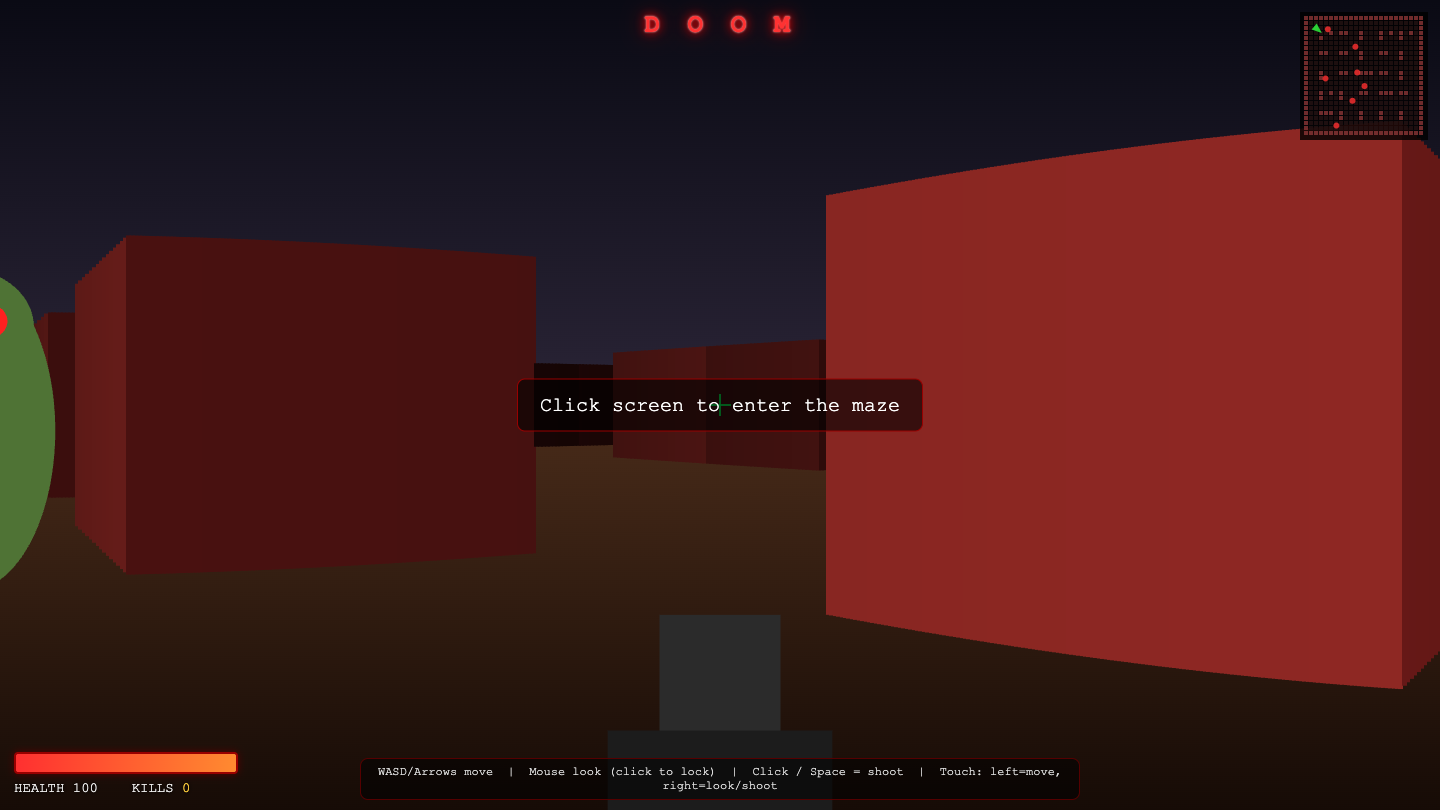 ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE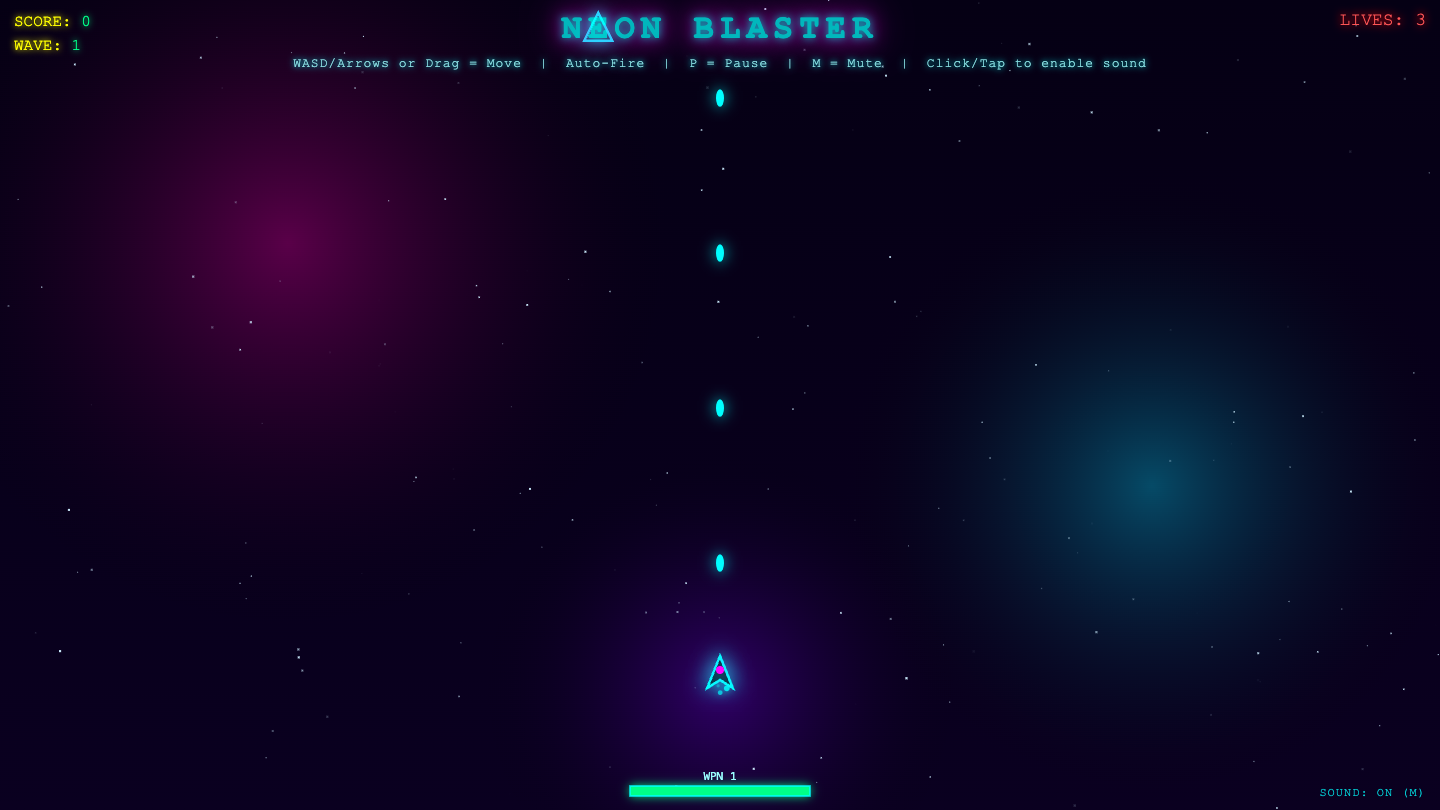 ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE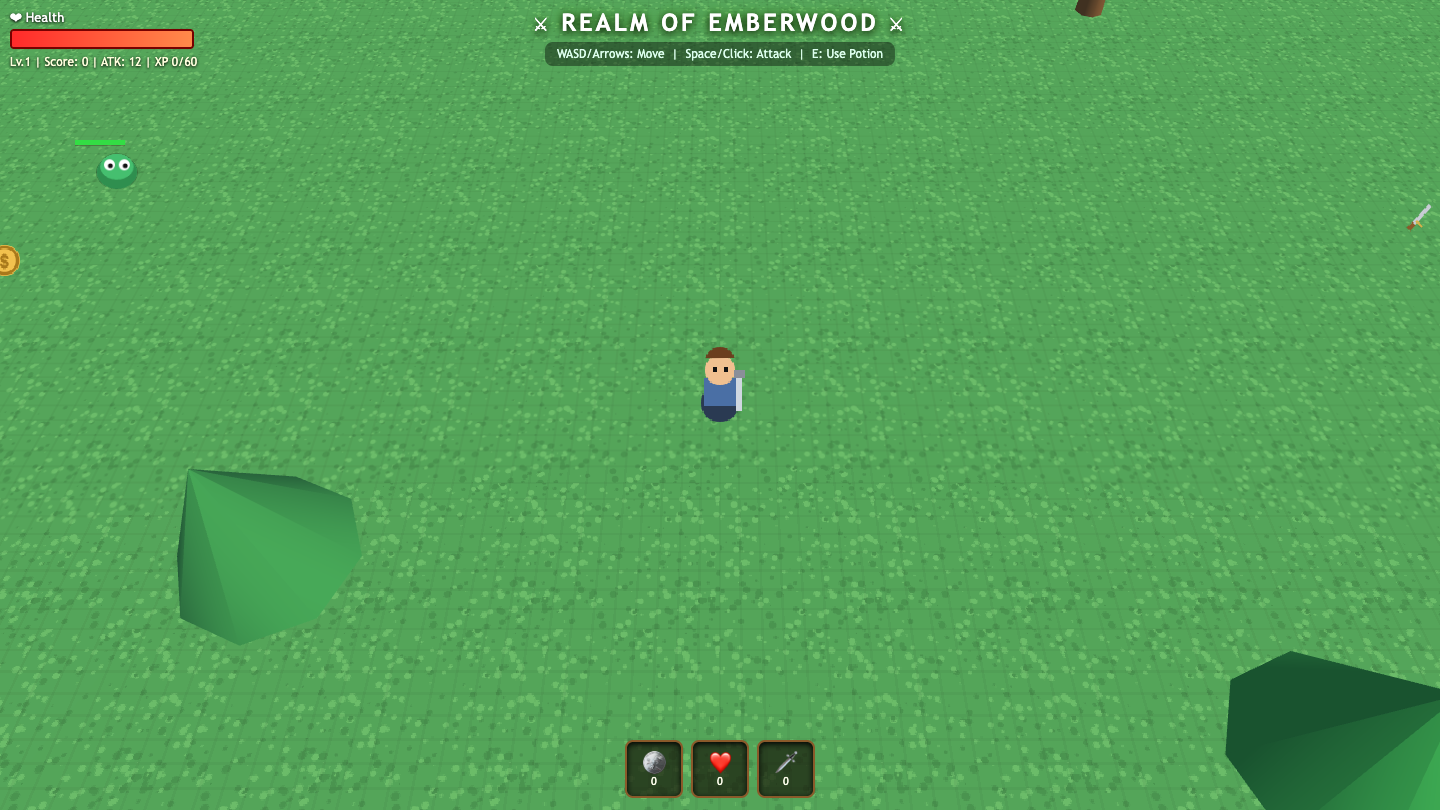 ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE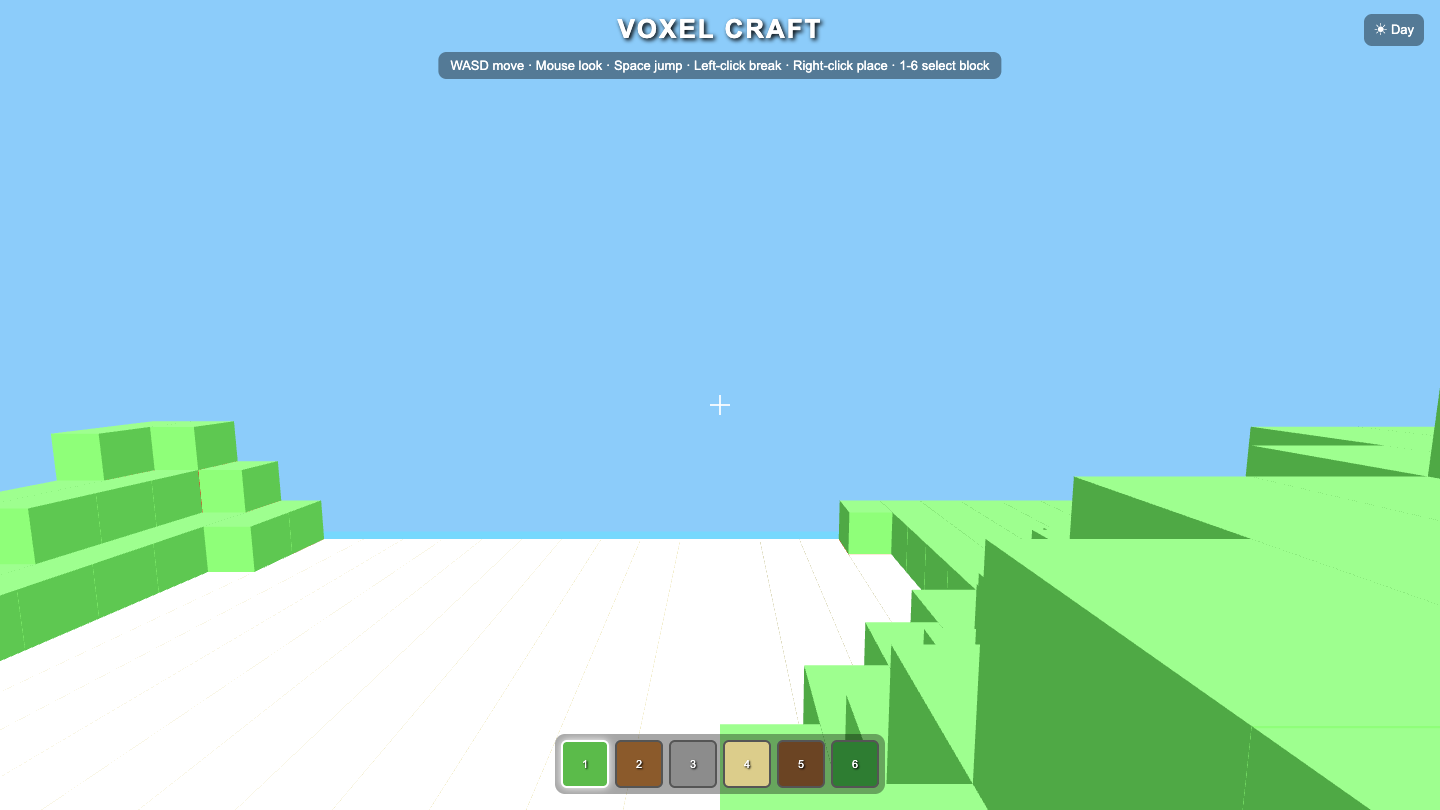 ▶ LIVE
▶ LIVE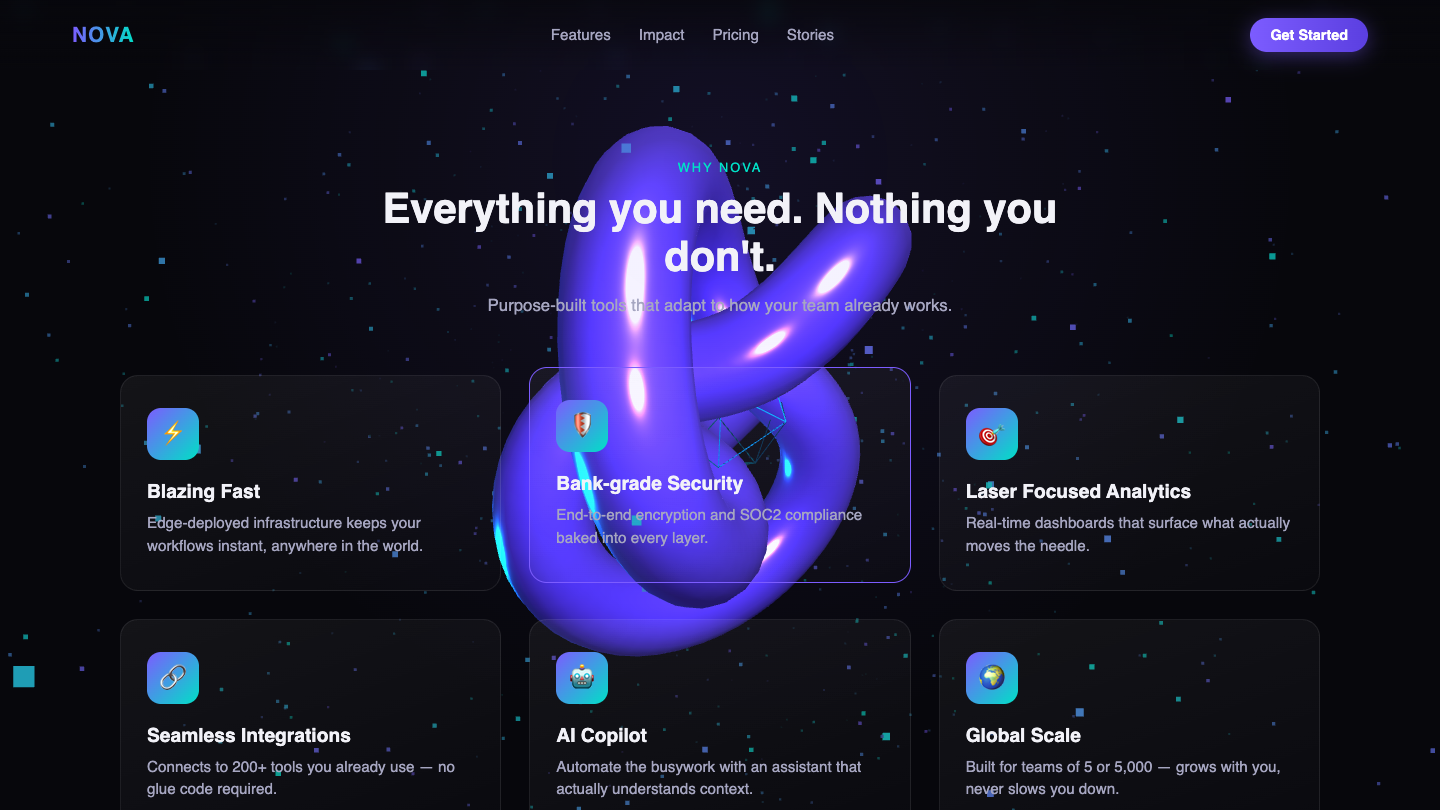 ▶ LIVE
▶ LIVE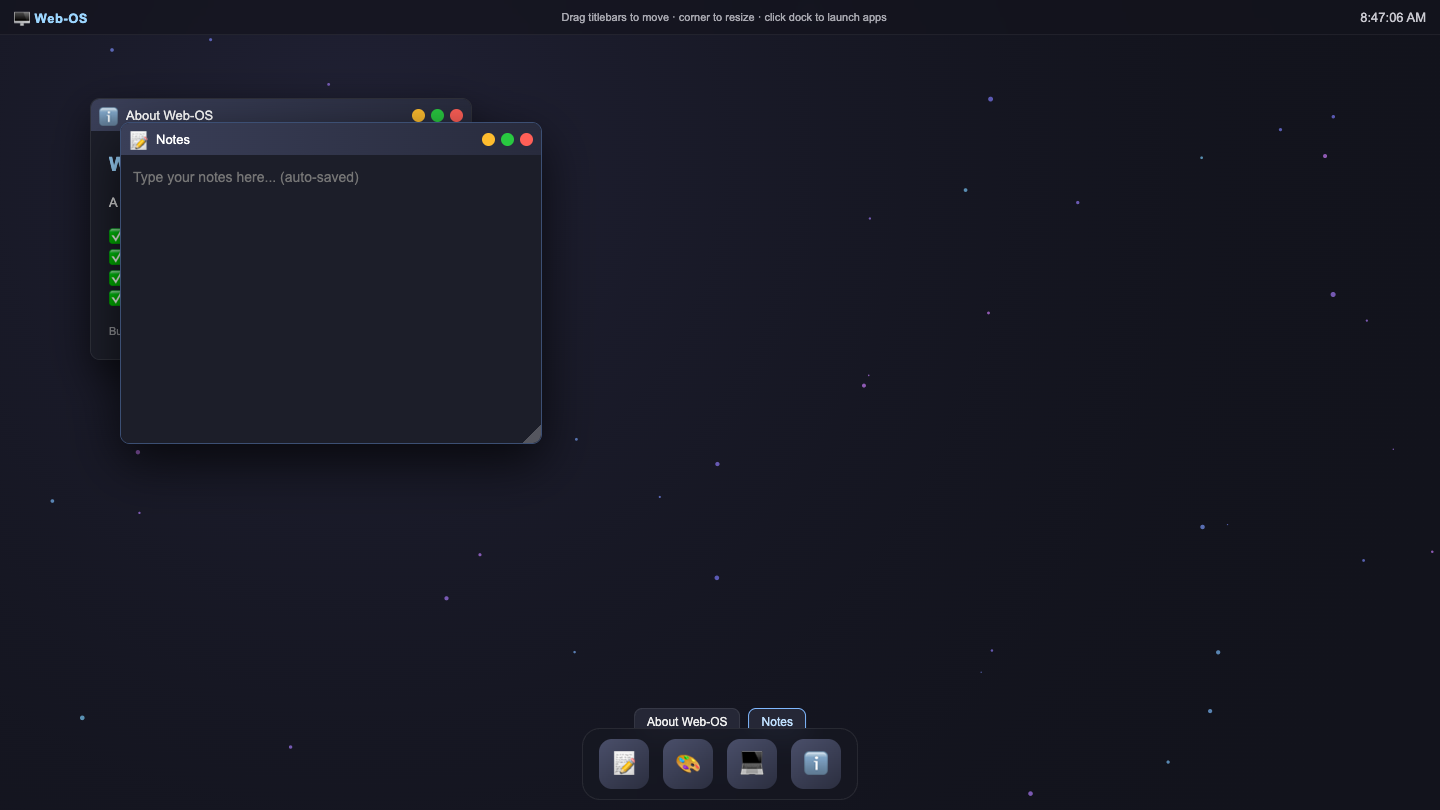 ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVECompare Claude Sonnet 5 against every other model
Every head-to-head featuring Claude Sonnet 5. Verdicts shown for scored pairs.
See all 66 comparisons across every model →
Quick pill index
Direct comparisons against every other scored model on the bench:
Claude Sonnet 5 vs Fusion Claude Sonnet 5 vs Hermes MoA Claude Sonnet 5 vs Grok Claude Sonnet 5 vs MiniMax M3 Claude Sonnet 5 vs Fugu Ultra Claude Sonnet 5 vs GLM-5.2 Claude Sonnet 5 vs Fugu Mini Claude Sonnet 5 vs Opus 4.8 Claude Sonnet 5 vs Kimi K2.7 Claude Sonnet 5 vs Qwable 5 27B Coder Claude Sonnet 5 vs Qwen 3.7 Claude Sonnet 5 vs Qwythos 9B Claude Sonnet 5 vs LongCat-2.0 Claude Sonnet 5 vs Gemma-4 12B CoderRead more on agentos.guide: /sonnet-5-vs-glm-5-2
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.