
Real head-to-head · same prompt, one shot
Claude Fable 5 vs Claude Sonnet 5
The newest Anthropic model — first Mythos-class made generally available. vs The agentic SWE frontier — 82% SWE-bench Verified, Dev Team mode.
Head-to-head verdict: Claude Fable 5 wins 22–15 with 5 ties.
What I tested — same prompt, two models
I run the same fixed prompt set through every new model the day it drops — same string, one shot, single HTML file out — and I score the result 0–10 on whether it ran, how close it hit the brief, and how good it looked. Below is what came out when I gave the exact same prompts to Claude Fable 5 and Claude Sonnet 5, side by side, on 42 shared tasks inside the Agent Operating System.
Both models were given identical prompts inside the Agent Operating System — no help, no iteration, no "best of N" tricks. I run each prompt once, save the HTML file the model produces, and score it 0–10 on whether it ran, how close it hit the brief, and how good it looked. The scoring is mine. The verdicts below are pulled from my source comparison guides at agentos.guide where I publish every score and the reasoning behind it.
Claude Fable 5 · Selected from Agent OS for the highest-stakes one-shot work — it replaced Opus 4.8 as the safety net on hard prompts, and the full 42-task bench run now backs that call.
Claude Sonnet 5 · Reach for it in Agent OS when the job is iterative, tool-using software engineering. For one-shot visual builds, GLM 5.2 (free) beat it 4-1 here.
Side-by-side on 42 shared tasks
Click any cell to play that model's actual one-shot attempt. Medals are derived from my 0–10 scores per task (highest = 🥇, second = 🥈, third = 🥉).
Task ↓
Claude Fable 5
Claude Sonnet 5
Game
Game


Game

Game

Game


Game


Game


Game

Game


Game


Game


Game


Game

Game


Game


Game
Game


Game


Game
Page
Page
Sim


Sim
Sim


Where Claude Fable 5 beat Claude Sonnet 5
The tasks where I gave Claude Fable 5 a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
Aurora
Visual
Claude Fable 5 8.6
·
Claude Sonnet 5 2.5
(+6.1)
· shader aurora curtains
What I saw: Beautiful WebGL fragment shader with layered green-blue aurora ribbons, twinkling starfield, snow-rimmed mountain silhouette, and elegant title typography — genuinely convincing northern lights. Interactive mouse sway and click surge plus the reflected glow push it to task-topping polish.
Solar
Sim
Claude Fable 5 8.0
·
Claude Sonnet 5 2.5
(+5.5)
What I saw: Renders cleanly with all 8 planets, elliptical orbit rings, glowing sun, Saturn's ring, and a polished title/legend UI; log-scaled distances plus interactive orbit/zoom controls are a thoughtful touch. Weaknesses are flat-colored planets (no textures) and inner planets crowding t…
Orbit
Sim
Claude Fable 5 7.6
·
Claude Sonnet 5 3.5
(+4.1)
What I saw: Renders cleanly with a glowing sun, colored planets, starfield and solid 3D orbit/zoom/spawn controls plus real N-body physics with softening and substeps; however the screenshot shows no visible orbital trails and a somewhat sparse, static-looking layout, keeping it strong-but-g…
Blackhole
Sim
Claude Fable 5 8.7
·
Claude Sonnet 5 5.0
(+3.7)
· Interstellar-grade lensing
What I saw: Strong Interstellar-style render with a clean event-horizon shadow, tilted accretion disk wrapping over/under the black hole, visible Doppler beaming brightening one side, and a subtle lensed arc — all polished with tasteful nebula/starfield and typography. Minor nit is the sligh…
Wormhole
Sim
Claude Fable 5 6.5
·
Claude Sonnet 5 3.0
(+3.5)
What I saw: The tunnel core with depth-fading rings and colorful particles reads convincingly as a wormhole and the UI/title are clean, but the flat teal fog fills most of the frame instead of an immersive tunnel, and the oversized foreground particle squares plus the misplaced solid-tube ge…
Where Claude Sonnet 5 beat Claude Fable 5
The tasks where I gave Claude Sonnet 5 a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
Crypt
Game
Claude Sonnet 5 6.5
·
Claude Fable 5 2.0
(+4.5)
What I saw: Renders with atmospheric HUD, functional minimap showing the maze, and a working torch-lit dungeon architecture in code, but the screenshot is too dark/muddy with no visible walls, torches, or dungeon geometry — the dim ambient/fog balance undersells the crawler and looks flat ra…
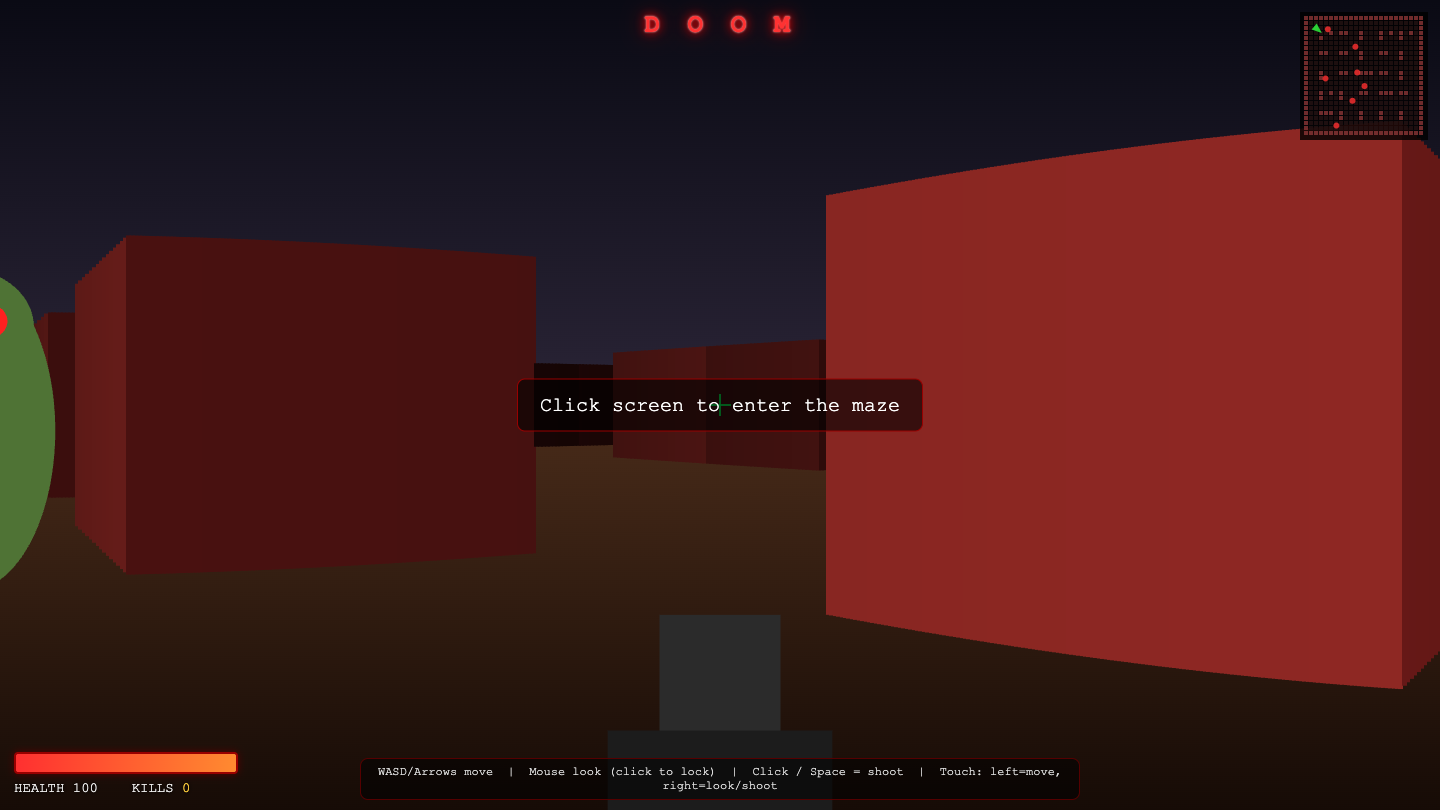
Doom
Game
Claude Sonnet 5 8.0
·
Claude Fable 5 6.2
(+1.8)
What I saw: Renders a clean raycaster maze with atmospheric red-lit walls, working minimap, HUD health/kills bar, crosshair and a monster visible at screen edge; solid feature set (hitscan shooting, chasing AI, damage flash, touch controls) makes it strong and shippable, though the wall shad…
Fireworks
Visual
Claude Sonnet 5 8.3
·
Claude Fable 5 7.2
(+1.1)
What I saw: Strong 3D scene with starfield, skyline silhouette, additive-blended particle bursts and a polished shimmering title—clearly on-brief and shippable. Particles read slightly blocky/square rather than glowing sparks, and the depth composition feels a touch flat, keeping it just shy…
Twilightvale
Game
Claude Sonnet 5 3.0
·
Claude Fable 5 2.5
(+0.5)
What I saw: UI overlays (title, kills, weather, HP bar, hint) render correctly but the 3D scene is completely black — no terrain, trees, player, or enemies visible, meaning the WebGL world failed to render despite solid source code. A non-rendering core makes this effectively broken for a 3D RPG task.
Game
Game
Claude Sonnet 5 8.2
·
Claude Fable 5 7.8
(+0.4)
What I saw: Strong, polished 3D Three.js build with clean neon aesthetic, glowing player orb, colorful octahedron collectibles, spinning obstacles, shadows, starfield, and full HUD/lives/timer loop — clearly shippable. Falls just short of the field's best due to being a fairly familiar colle…
Strengths & weaknesses I logged
Claude Fable 5
Strengths
- Best solo Anthropic model on this bench — 7.72 avg beats Opus 4.8 (7.49) and Sonnet 5 (7.18)
- Wins most head-to-heads vs every solo rival: beats Opus 4.8 on 26/42 tasks and GLM-5.2 on 27/42 — two one-shot crashes, not the craft, cost it the average
- 10 task-winner tags in a single one-shot run — shader/GPU physics is its superpower (Cornell-box path tracer 8.7, black-hole lensing 8.7, synthwave outrun 8.7)
- Tops external SWE-bench Verified at 95.0% in Julian's three-dragons writeup
Trade-offs
- Two one-shot black-screens (crypt, twilightvale) from three.js r128 API drift — called THREE.Geometry / CapsuleGeometry, which the pinned CDN doesn't have
- Free GLM-5.2 still edges it on creative one-shots (7.77 vs 7.72) at $0 — the $10/$50 premium buys agentic depth, not one-shot visuals
Claude Sonnet 5
Strengths
- 82.1% SWE-bench Verified — first model past 80% on real GitHub-issue repair
- Dev Team multi-agent mode + 1M context for repo-level agentic work
- Precision on hard logic — won the raycaster the open-weight field kept botching
Trade-offs
- One-shot creative-visual builds trail GLM 5.2 here (lost 4 of 5) — no iteration to catch its own bugs
- A temporal-dead-zone bug blanked its N-body orbit sim on the first shot
Pricing & context — the spec sheet
| Spec | Claude Fable 5 | Claude Sonnet 5 |
|---|---|---|
| Vendor | Anthropic | Anthropic |
| Context window | 200,000 tokens (1M with extended thinking) | 1,000,000 tokens |
| Price | $10 / $50 per M tokens | $3 / $15 per M ($2/$10 intro) |
| Pricing detail | Released alongside Mythos 5 on June 9, 2026 as the publicly-available member of the new Mythos class. Premium per-token pricing on the Anthropic API; available everywhere Opus 4.8 ships. | $3.00 input / $15.00 output per million tokens; introductory $2.00/$10.00 through 2026-08-31. |
| Release | 2026-06-09 | 2026-06-30 |
| Bench coverage | 42/42 scored · avg 7.72/10 | 42/42 scored · avg 7.18/10 |
The verdict — which should you pick?
Across 42 scored shared tasks, Claude Fable 5 averaged 7.72/10, beating Claude Sonnet 5's 7.18/10 by 0.54 points. Pick Claude Fable 5 when the build has to ship on the first prompt and you can afford the trade-offs in the comparison below.
If you only run one of these inside your stack, the head-to-head average above is the call. If you can run both, my honest play is to wire Claude Fable 5 and Claude Sonnet 5 both into the Agent Operating System and dispatch each from the kanban by task type — mission-critical one-shot builds where you want anthropic's newest reasoning → Claude Fable 5, agentic software engineering — write / run / test / fix loops on real repos → Claude Sonnet 5. That's the same setup I run for the 3,600+ founders inside the AI Profit Boardroom.
FAQ — Claude Fable 5 vs Claude Sonnet 5
Which is better, Claude Fable 5 or Claude Sonnet 5?
On Goldie Bench, Claude Fable 5 averages 7.72/10 across the shared tasks, with 3 gold, 1 silver, 7 bronze overall. Claude Sonnet 5 averages 7.18/10, with 1 gold, 5 silver, 2 bronze. Claude Fable 5 wins the head-to-head 22–15.
How much does Claude Fable 5 cost vs Claude Sonnet 5?
Claude Fable 5: Released alongside Mythos 5 on June 9, 2026 as the publicly-available member of the new Mythos class. Premium per-token pricing on the Anthropic API; available everywhere Opus 4.8 ships. Claude Sonnet 5: $3.00 input / $15.00 output per million tokens; introductory $2.00/$10.00 through 2026-08-31.
What's the context window for Claude Fable 5 vs Claude Sonnet 5?
Claude Fable 5 has a 200,000 tokens (1M with extended thinking) context window. Claude Sonnet 5 has a 1,000,000 tokens context window.
When should I pick Claude Fable 5 over Claude Sonnet 5?
Pick Claude Fable 5 for: Mission-critical one-shot builds where you want Anthropic's newest reasoning; Long-context work using extended thinking up to 1M tokens; Plan-heavy multi-step tasks where intelligence in the plan matters more than the build. The trade-off is the weaknesses we logged on the bench: Two one-shot black-screens (crypt, twilightvale) from three.js r128 API drift — called THREE.Geometry / CapsuleGeometry, which the pinned CDN doesn't have; Free GLM-5.2 still edges it on creative one-shots (7.77 vs 7.72) at $0 — the $10/$50 premium buys agentic depth, not one-shot visuals.
When should I pick Claude Sonnet 5 over Claude Fable 5?
Pick Claude Sonnet 5 for: Agentic software engineering — write / run / test / fix loops on real repos; Repo-level reasoning across a 1M-token context (Dev Team multi-agent mode); Precise logic — raycasters, physics — where one-shot open models slip. The trade-off is the weaknesses we logged on the bench: One-shot creative-visual builds trail GLM 5.2 here (lost 4 of 5) — no iteration to catch its own bugs; A temporal-dead-zone bug blanked its N-body orbit sim on the first shot.
How does Goldie Bench score Claude Fable 5 vs Claude Sonnet 5?
Every demo on this page was built by Julian Goldie inside the Agent Operating System — same fixed prompt for both models, one shot, single HTML file out. Each result gets a 0–10 score on whether it ran, how close it hit the brief, and how good it looked. The highest score on each task gets gold; second gets silver; third gets bronze. See methodology for full provenance.
Related comparisons
Other head-to-heads using the same scoring system:
Claude Fable 5 vs Fusion Claude Sonnet 5 vs Fusion Claude Fable 5 vs Hermes MoA Claude Sonnet 5 vs Hermes MoA Claude Fable 5 vs Grok Claude Sonnet 5 vs Grok Claude Fable 5 vs MiniMax M3 Claude Sonnet 5 vs MiniMax M3Full model pages: Claude Fable 5 · Claude Sonnet 5 · back to the leaderboard
The same stack Julian uses
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.
3,600+founders
258documented wins
38countries
$59/momonthly