Gtadrive
GTA Drive — open-city driving sandbox: steal cars, outrun cops, traffic, wanted level, minimap.
What I asked each model — the Gtadrive prompt
Every model on this page got this exact prompt inside the Agent Operating System: GTA Drive — open-city driving sandbox: steal cars, outrun cops, traffic, wanted level, minimap.
Single HTML file out. No iteration. No examples in the system prompt. Whatever each model produced on the first run is what's on this page. 7 frontier models have attempted it so far: Fusion, GLM-5.2, Grok, Kimi K2.7, MiniMax M3, Opus 4.8, Qwen 3.7.
Why this task matters. Gtadrive is a textbook test of game-class capability — the kind of build that exposes whether a model is doing pattern-matching or actual reasoning. A model that ships this in one shot is usually safe to wire into your agent loop for harder tasks of the same shape.
How each model handled Gtadrive
Ranked by my 0–10 score from the source comparison guides on agentos.guide. Click any to play the actual one-shot HTML the model produced.
What I saw: 47KB · plays clean · three, webgl
What I saw: 23KB · plays clean · three, webgl
What I saw: 33KB · plays clean · three, webgl
What I saw: 22KB · plays clean · three, webgl (re-rolled)
The winner on Gtadrive
GLM-5.2 took gold on this task.
What I saw: 47KB · plays clean · three, webgl
See GLM-5.2's full model card: /models/glm.
Every attempt — live, playable
Side by side. Click any tile to run that model's actual one-shot HTML in a new tab.
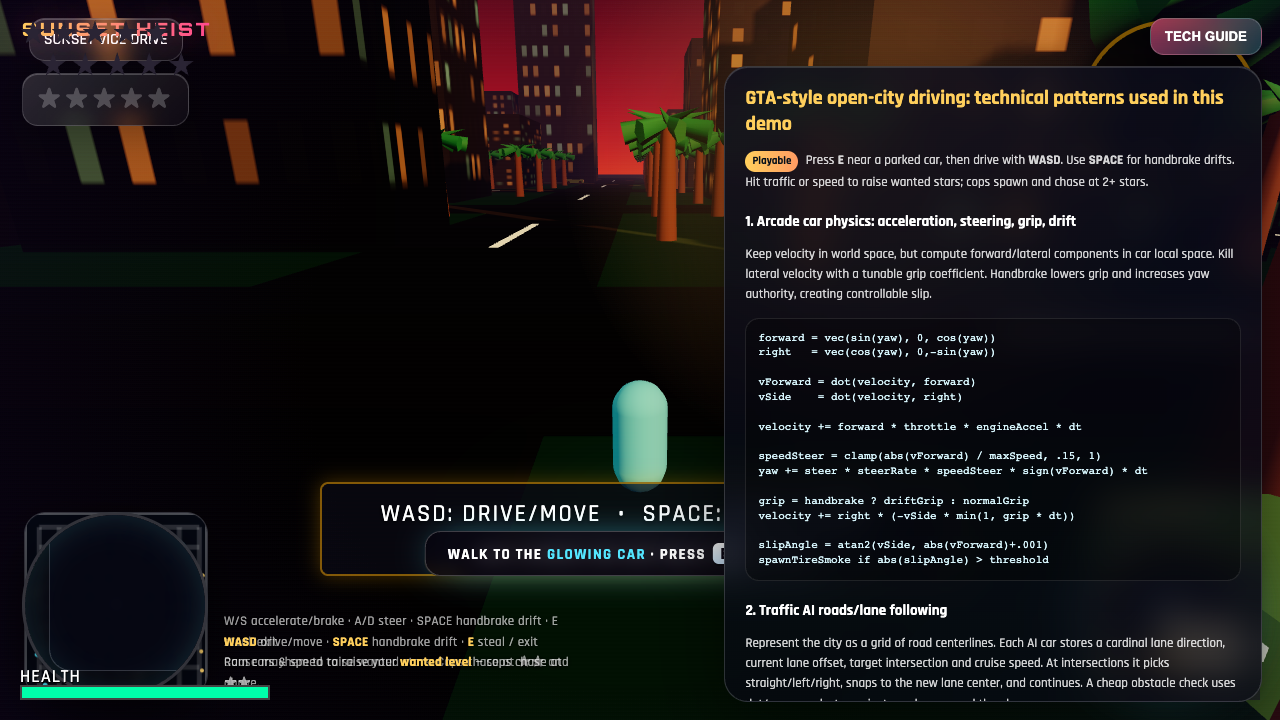 ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVEHow I scored Gtadrive — methodology
Three axes, 0–10 each, averaged. Runs: drop the .html in a browser; if it opens to a broken page, it scores zero. Hits the brief: did the model ship the thing the prompt asked for, or a different thing it found easier. Looks good: visual polish, motion, interactivity — where most of the gap between gold and silver lives.
My scores trace back to the source comparison guides on agentos.guide. See the full methodology page for data provenance, including which source guide each cell's score came from.
Related
More game benchmarks: all tasks in the Game category · See the best AI model for Gtadrive · Back to the leaderboard
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.