Real head-to-head · same prompt, one shot
Kimi K2.7 vs Claude Sonnet 5
The heavy lifter — frontier coder at flat-rate. vs The agentic SWE frontier — 82% SWE-bench Verified, Dev Team mode.
Head-to-head verdict: Claude Sonnet 5 wins 11–7 with 2 ties.
What I tested — same prompt, two models
I run the same fixed prompt set through every new model the day it drops — same string, one shot, single HTML file out — and I score the result 0–10 on whether it ran, how close it hit the brief, and how good it looked. Below is what came out when I gave the exact same prompts to Kimi K2.7 and Claude Sonnet 5, side by side, on 42 shared tasks inside the Agent Operating System.
Both models were given identical prompts inside the Agent Operating System — no help, no iteration, no "best of N" tricks. I run each prompt once, save the HTML file the model produces, and score it 0–10 on whether it ran, how close it hit the brief, and how good it looked. The scoring is mine. The verdicts below are pulled from my source comparison guides at agentos.guide where I publish every score and the reasoning behind it.
Kimi K2.7 · Wired into the Agent OS as the heavy-lifter for game/sim prototypes and Kanban-dispatched code work. Mode toggled per task: Quality for one-shot games, Fast for short bursts.
Claude Sonnet 5 · Reach for it in Agent OS when the job is iterative, tool-using software engineering. For one-shot visual builds, GLM 5.2 (free) beat it 4-1 here.
Side-by-side on 42 shared tasks
Click any cell to play that model's actual one-shot attempt. Medals are derived from my 0–10 scores per task (highest = 🥇, second = 🥈, third = 🥉).
Task ↓
Kimi K2.7
Claude Sonnet 5
Game
Game


Game
Game
Game


Game


Game


Game

Game


Game


Game


Game


Game

Game

Game

Game

Game

Game


Game
Page

Page
Sim


Sim

Sim


Where Kimi K2.7 beat Claude Sonnet 5
The tasks where I gave Kimi K2.7 a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
Solar
Sim
Kimi K2.7 8.0
·
Claude Sonnet 5 2.5
(+5.5)
What I saw: Three genuinely good space sims. Opus tilts the orbits into real 3D with a bloom-heavy sun and Saturn's rings. GLM's is the most product-like — labelled planets, orbit and label toggles, a clean HUD. Kimi's is a tidy tilted-orbit system with rings and a deep starfield. Opus and G…
Twilightvale
Game
Kimi K2.7 8.5
·
Claude Sonnet 5 3.0
(+5.5)
What I saw: 64KB open-world RPG with village, NPCs, combat, day/night cycle. Densest Kimi build.
Orbit
Sim
Kimi K2.7 6.0
·
Claude Sonnet 5 3.5
(+2.5)
What I saw: Opus nailed the brief — labelled planet orbits, a real NEO / close-pass panel, a sim clock. GLM went for drama: a glowing nebula swirl that's gorgeous but reads more galaxy than orbit map. Kimi's is accurate but dim and sparse.
Fractal
Sim
Kimi K2.7 9.0
·
Claude Sonnet 5 7.2
(+1.8)
· winner · pure wow
What I saw: All three are genuinely good. Kimi's is the jaw-dropper — a deep rainbow plunge into a seahorse spiral, dense with self-similar detail. Opus zooms smoothly into the seahorse valley with a tasteful cycling palette. GLM frames the whole iconic set in a fire palette with a live coor…
Blackhole
Sim
Kimi K2.7 6.0
·
Claude Sonnet 5 5.0
(+1.0)
What I saw: Opus nailed it — a pure-black event horizon, a bright photon ring, and the disk bent up and over the top exactly like the film's lensing. GLM came in strong with a clean ring and a starfield warping past the hole. Kimi's disk is fine, but the background is a soft grey blur instea…
Where Claude Sonnet 5 beat Kimi K2.7
The tasks where I gave Claude Sonnet 5 a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
Fluid
Sim
Claude Sonnet 5 8.6
·
Kimi K2.7 5.0
(+3.6)
· gorgeous flow field
What I saw: Stunning rendered flow-field with rich swirling particle streaks, a clear vortex focal point, and vivid rainbow color mapping over additive-blended trails — genuinely beautiful and clearly on-brief. Only knock is the low 22fps and it's a flow-field trail sim rather than true flui…
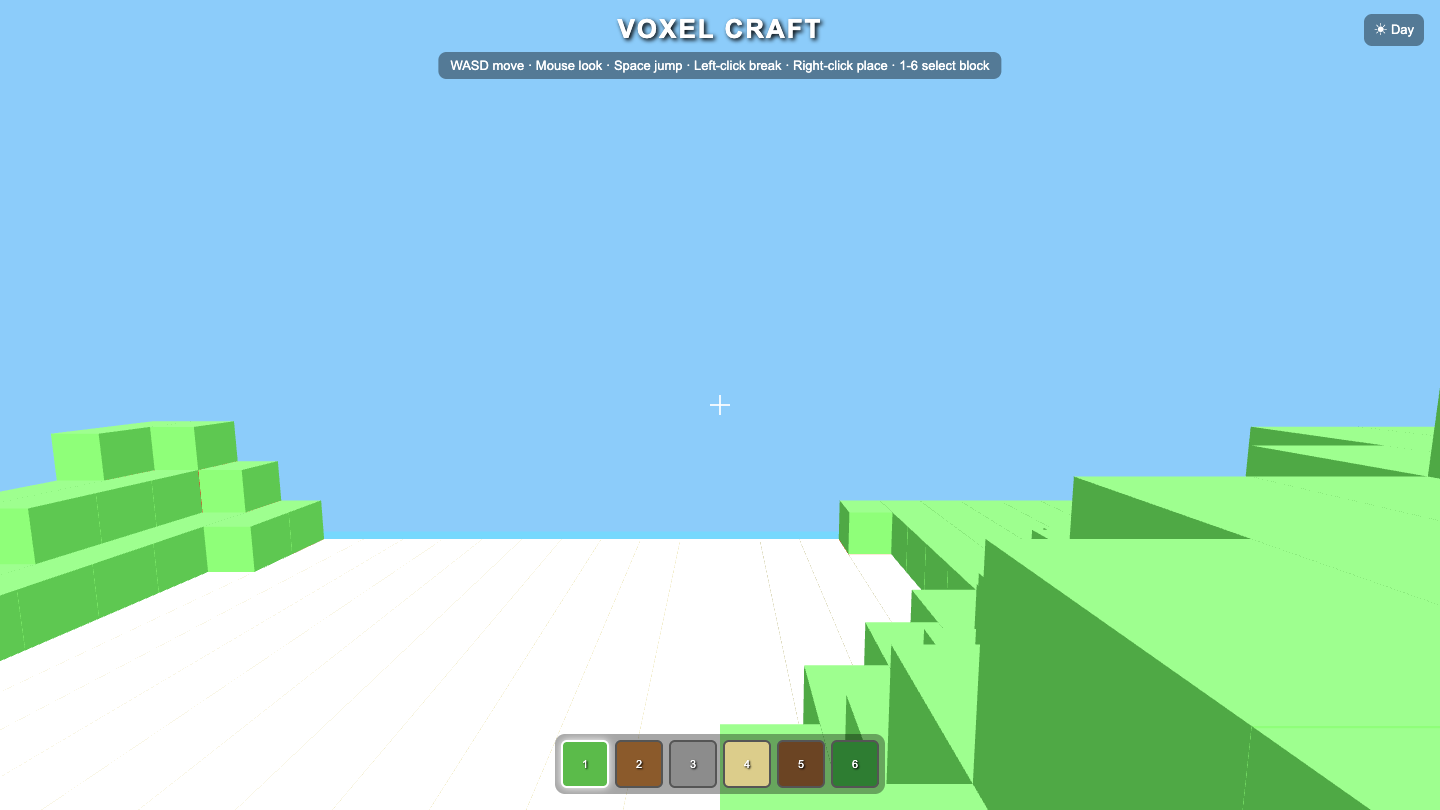
Voxel
Visual
Claude Sonnet 5 8.4
·
Kimi K2.7 6.0
(+2.4)
What I saw: Strong, polished voxel island with clean biome layering (sand/grass/stone/snow), soft shadows, trees, translucent water and clear orbit/zoom/WASD controls — very on-brief. Falls just short of the top: the terrain reads a bit flat/small and the stone plateau looks like a slightly …
Synthwave
Visual
Claude Sonnet 5 8.4
·
Kimi K2.7 6.5
(+1.9)
What I saw: Gorgeous, on-brief synthwave scene with striped sun, layered mountains, glowing neon title and a warm-to-purple gradient grid that reads beautifully; only knock is a visible rectangular artifact around the sun (the sky plane/glow seam) that slightly breaks the polish.
Plasma
Visual
Claude Sonnet 5 8.4
·
Kimi K2.7 7.5
(+0.9)
What I saw: Gorgeous smooth GLSL plasma with rich rainbow blobs, clean glowing title, and five well-styled palette swatches with clear active state; ripples aren't visible in the still but the code is solid, though the effect reads slightly generic against the very best field entry.
Neonblaster
Game
Claude Sonnet 5 8.3
·
Kimi K2.7 7.5
(+0.8)
What I saw: Strong neon aesthetic with glowing nebulae, layered starfield, polished ship and auto-fire bullets, plus a full feature set (waves, bosses, power-ups, synth sequencer, screen-shake); the screenshot looks clean and on-brief but reads a touch sparse/quiet early on versus the flashi…
Strengths & weaknesses I logged
Kimi K2.7
Strengths
- Best-of-three on interactive games — raycaster, DOOM, monster AI
- Three speed modes (Fast / No-Think / Quality) you can swap per task
- Flat-rate plan eliminates the per-token meter, so iteration is free
Trade-offs
- Plays plainest on abstract visual prompts — synthwave grids, fluid sims, aurora — where GLM and Opus add more flair
- Bronze average on the Goldie Bench bench despite the gold-medal games — its visual builds are accurate but understated
Claude Sonnet 5
Strengths
- 82.1% SWE-bench Verified — first model past 80% on real GitHub-issue repair
- Dev Team multi-agent mode + 1M context for repo-level agentic work
- Precision on hard logic — won the raycaster the open-weight field kept botching
Trade-offs
- One-shot creative-visual builds trail GLM 5.2 here (lost 4 of 5) — no iteration to catch its own bugs
- A temporal-dead-zone bug blanked its N-body orbit sim on the first shot
Pricing & context — the spec sheet
| Spec | Kimi K2.7 | Claude Sonnet 5 |
|---|---|---|
| Vendor | Moonshot AI | Anthropic |
| Context window | 256,000 tokens | 1,000,000 tokens |
| Price | Flat plan (no per-token bill) | $3 / $15 per M ($2/$10 intro) |
| Pricing detail | Available on Moonshot's flat-rate subscription plan — no per-token billing for individual builders. The plan covers all three speed modes (Fast, No-Think, Quality). Vendor: Moonshot AI (moonshot.ai), based in Beijing. | $3.00 input / $15.00 output per million tokens; introductory $2.00/$10.00 through 2026-08-31. |
| Release | 2026-06 | 2026-06-30 |
| Bench coverage | 20/42 scored · avg 7.42/10 | 42/42 scored · avg 7.18/10 |
The verdict — which should you pick?
Across 20 scored shared tasks, the averages are essentially tied — Kimi K2.7 7.42 vs Claude Sonnet 5 7.18. This isn't the comparison where one wins; it's the comparison where you pick based on context, pricing, and what you're actually trying to ship.
If you only run one of these inside your stack, the head-to-head average above is the call. If you can run both, my honest play is to wire Kimi K2.7 and Claude Sonnet 5 both into the Agent Operating System and dispatch each from the kanban by task type — interactive game prototypes you want shippable on the first prompt → Kimi K2.7, agentic software engineering — write / run / test / fix loops on real repos → Claude Sonnet 5. That's the same setup I run for the 3,600+ founders inside the AI Profit Boardroom.
FAQ — Kimi K2.7 vs Claude Sonnet 5
Which is better, Kimi K2.7 or Claude Sonnet 5?
On Goldie Bench, Kimi K2.7 averages 7.42/10 across the shared tasks, with 2 gold, 1 silver, 1 bronze overall. Claude Sonnet 5 averages 7.18/10, with 3 gold, 3 silver, 3 bronze. Claude Sonnet 5 wins the head-to-head 11–7.
How much does Kimi K2.7 cost vs Claude Sonnet 5?
Kimi K2.7: Available on Moonshot's flat-rate subscription plan — no per-token billing for individual builders. The plan covers all three speed modes (Fast, No-Think, Quality). Vendor: Moonshot AI (moonshot.ai), based in Beijing. Claude Sonnet 5: $3.00 input / $15.00 output per million tokens; introductory $2.00/$10.00 through 2026-08-31.
What's the context window for Kimi K2.7 vs Claude Sonnet 5?
Kimi K2.7 has a 256,000 tokens context window. Claude Sonnet 5 has a 1,000,000 tokens context window.
When should I pick Kimi K2.7 over Claude Sonnet 5?
Pick Kimi K2.7 for: Interactive game prototypes you want shippable on the first prompt; High-iteration agent loops where per-token cost would dominate; Long-context refactors using the 256K window inside Agent OS. The trade-off is the weaknesses we logged on the bench: Plays plainest on abstract visual prompts — synthwave grids, fluid sims, aurora — where GLM and Opus add more flair; Bronze average on the {{SITE_NAME}} bench despite the gold-medal games — its visual builds are accurate but understated.
When should I pick Claude Sonnet 5 over Kimi K2.7?
Pick Claude Sonnet 5 for: Agentic software engineering — write / run / test / fix loops on real repos; Repo-level reasoning across a 1M-token context (Dev Team multi-agent mode); Precise logic — raycasters, physics — where one-shot open models slip. The trade-off is the weaknesses we logged on the bench: One-shot creative-visual builds trail GLM 5.2 here (lost 4 of 5) — no iteration to catch its own bugs; A temporal-dead-zone bug blanked its N-body orbit sim on the first shot.
How does Goldie Bench score Kimi K2.7 vs Claude Sonnet 5?
Every demo on this page was built by Julian Goldie inside the Agent Operating System — same fixed prompt for both models, one shot, single HTML file out. Each result gets a 0–10 score on whether it ran, how close it hit the brief, and how good it looked. The highest score on each task gets gold; second gets silver; third gets bronze. See methodology for full provenance.
Related comparisons
Other head-to-heads using the same scoring system:
Kimi K2.7 vs Fusion Claude Sonnet 5 vs Fusion Kimi K2.7 vs Hermes MoA Claude Sonnet 5 vs Hermes MoA Kimi K2.7 vs Grok Claude Sonnet 5 vs Grok Kimi K2.7 vs MiniMax M3 Claude Sonnet 5 vs MiniMax M3Full model pages: Kimi K2.7 · Claude Sonnet 5 · back to the leaderboard
The same stack Julian uses
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.
3,600+founders
258documented wins
38countries
$59/momonthly