Real head-to-head · same prompt, one shot
Opus 4.8 vs Claude Sonnet 5
The reasoning king — deepest thinking, premium price. vs The agentic SWE frontier — 82% SWE-bench Verified, Dev Team mode.
Head-to-head verdict: Claude Sonnet 5 wins 25–16 with 1 tie.
What I tested — same prompt, two models
I run the same fixed prompt set through every new model the day it drops — same string, one shot, single HTML file out — and I score the result 0–10 on whether it ran, how close it hit the brief, and how good it looked. Below is what came out when I gave the exact same prompts to Opus 4.8 and Claude Sonnet 5, side by side, on 42 shared tasks inside the Agent Operating System.
Both models were given identical prompts inside the Agent Operating System — no help, no iteration, no "best of N" tricks. I run each prompt once, save the HTML file the model produces, and score it 0–10 on whether it ran, how close it hit the brief, and how good it looked. The scoring is mine. The verdicts below are pulled from my source comparison guides at agentos.guide where I publish every score and the reasoning behind it.
Opus 4.8 · The default when the build has to ship on the first prompt — Opus is the safety net inside Agent OS for hard one-shots.
Claude Sonnet 5 · Reach for it in Agent OS when the job is iterative, tool-using software engineering. For one-shot visual builds, GLM 5.2 (free) beat it 4-1 here.
Side-by-side on 42 shared tasks
Click any cell to play that model's actual one-shot attempt. Medals are derived from my 0–10 scores per task (highest = 🥇, second = 🥈, third = 🥉).
Task ↓
Opus 4.8
Claude Sonnet 5
Game
Game


Game

Game

Game

Game


Game

Game

Game


Game

Game


Game


Game

Game

Game

Game
Game


Game


Game
Page
Page
Sim


Sim

Sim

Where Opus 4.8 beat Claude Sonnet 5
The tasks where I gave Opus 4.8 a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
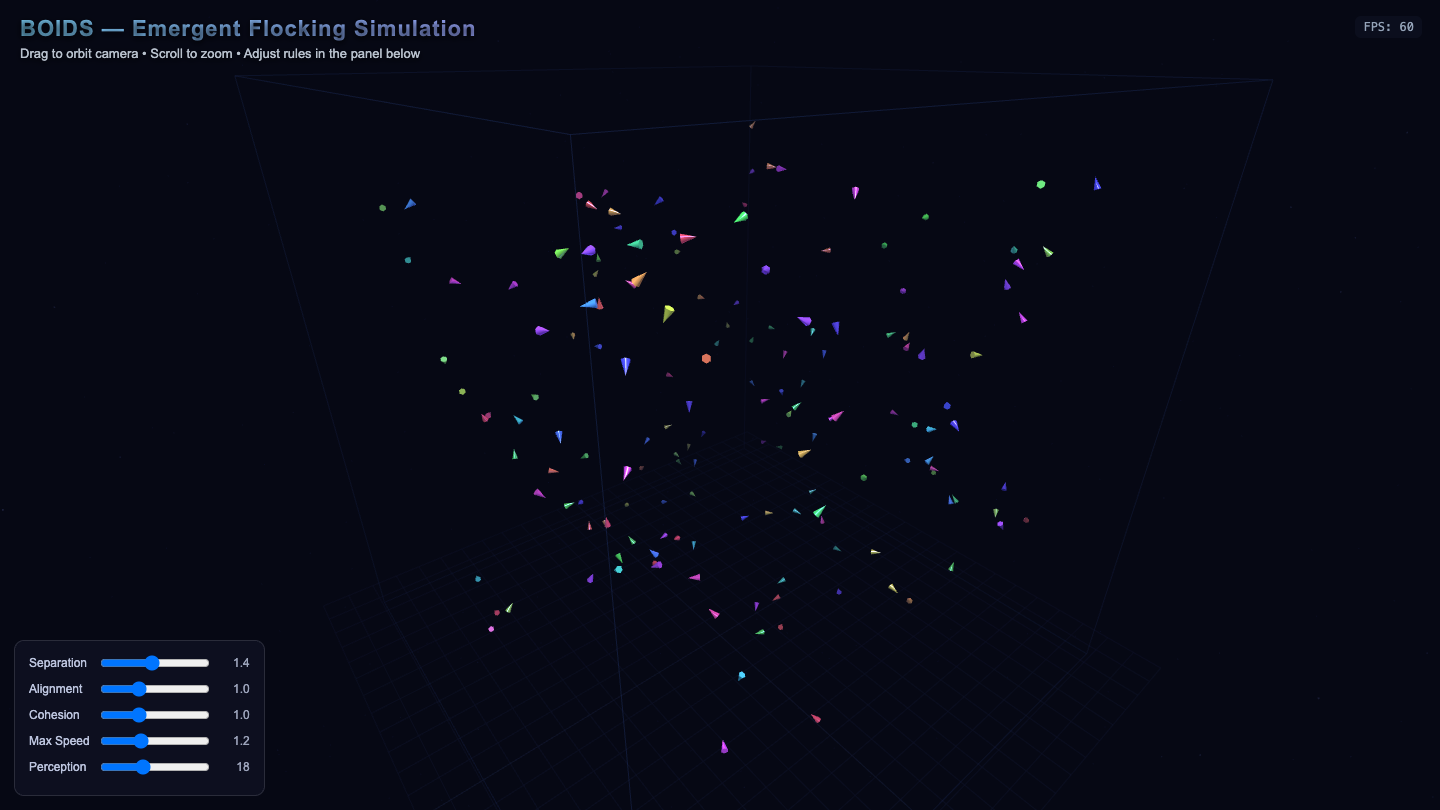
Solar
Sim
Opus 4.8 8.5
·
Claude Sonnet 5 2.5
(+6.0)
· winner · 3D depth
What I saw: Three genuinely good space sims. Opus tilts the orbits into real 3D with a bloom-heavy sun and Saturn's rings. GLM's is the most product-like — labelled planets, orbit and label toggles, a clean HUD. Kimi's is a tidy tilted-orbit system with rings and a deep starfield. Opus and G…
Orbit
Sim
Opus 4.8 9.0
·
Claude Sonnet 5 3.5
(+5.5)
· winner · accuracy
What I saw: Opus nailed the brief — labelled planet orbits, a real NEO / close-pass panel, a sim clock. GLM went for drama: a glowing nebula swirl that's gorgeous but reads more galaxy than orbit map. Kimi's is accurate but dim and sparse.
Twilightvale
Game
Opus 4.8 7.5
·
Claude Sonnet 5 3.0
(+4.5)
What I saw: 22KB · plays clean · webgl
Wormhole
Sim
Opus 4.8 7.5
·
Claude Sonnet 5 3.0
(+4.5)
What I saw: 11KB · plays clean · webgl, input
Blackhole
Sim
Opus 4.8 9.0
·
Claude Sonnet 5 5.0
(+4.0)
· winner · hit the brief
What I saw: Opus nailed it — a pure-black event horizon, a bright photon ring, and the disk bent up and over the top exactly like the film's lensing. GLM came in strong with a clean ring and a starfield warping past the hole. Kimi's disk is fine, but the background is a soft grey blur instea…
Where Claude Sonnet 5 beat Opus 4.8
The tasks where I gave Claude Sonnet 5 a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
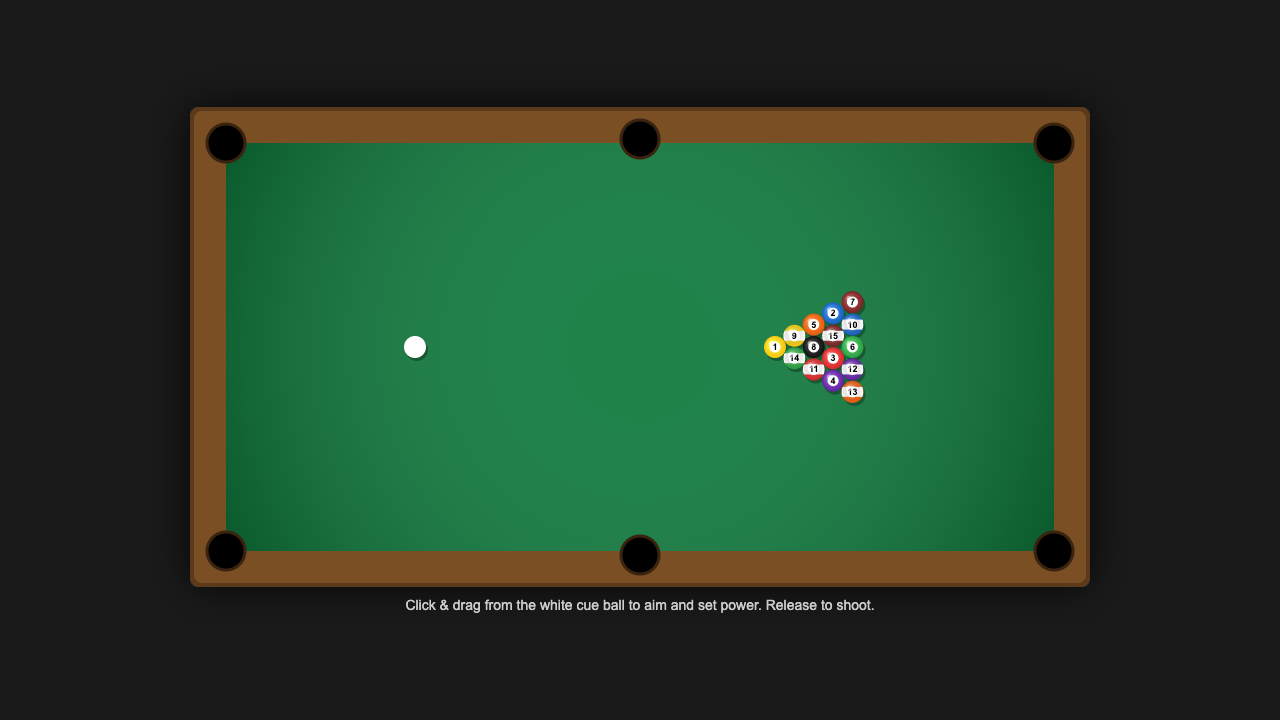
Pool
Game
Claude Sonnet 5 8.2
·
Opus 4.8 5.5
(+2.7)
What I saw: Clean 3D render with proper racked triangle, numbered/striped ball textures, cue stick aiming, pockets and power bar—clearly on-brief and polished. Solid physics-oriented setup but visually generic versus a task winner, and the shadowing under the rack looks a bit off.
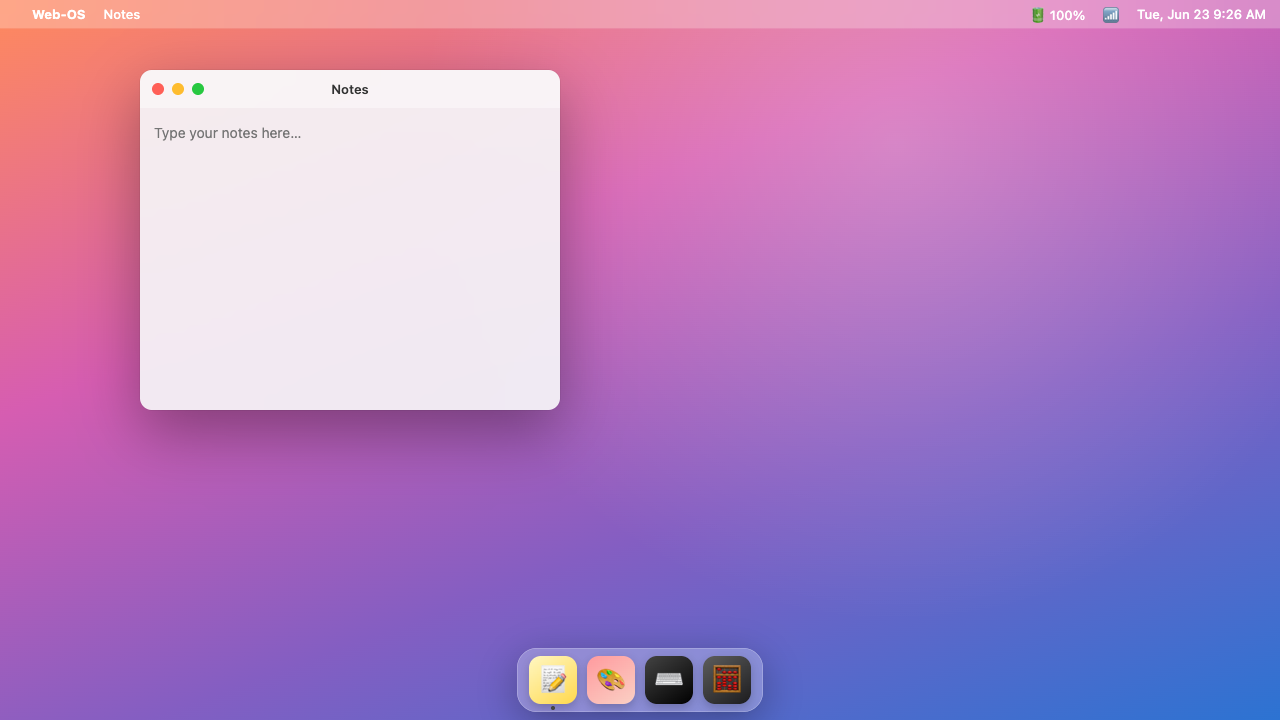
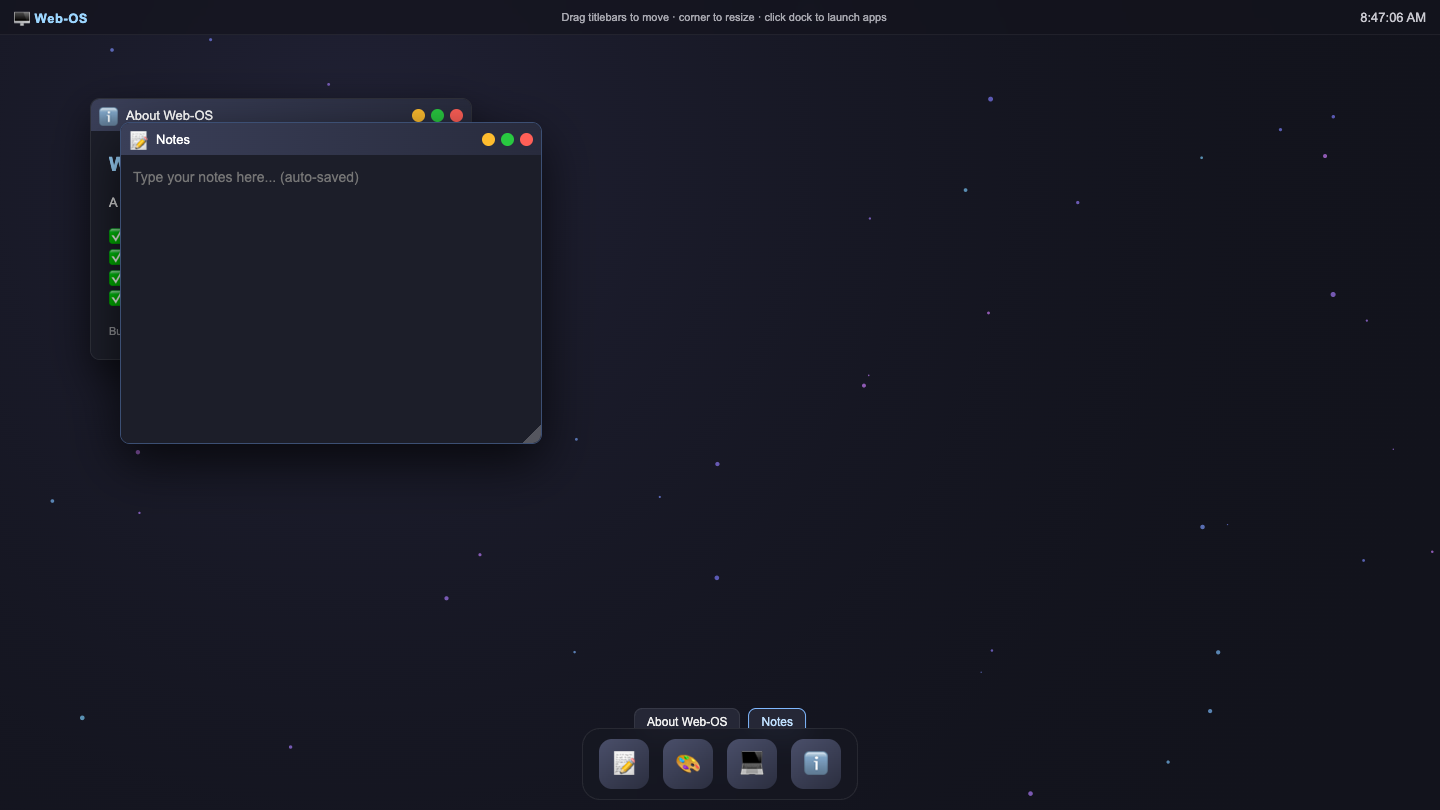
Webos
Page
Claude Sonnet 5 8.0
·
Opus 4.8 5.5
(+2.5)
What I saw: Renders a polished dark desktop with animated starfield bg, working dock, taskbar pills, mac-style window controls, drag/resize, and functional apps (Notes/Paint/Terminal/About visible). Strong and shippable but visually generic and only shows two overlapping windows—doesn't quit…
Fluid
Sim
Claude Sonnet 5 8.6
·
Opus 4.8 7.0
(+1.6)
· gorgeous flow field
What I saw: Stunning rendered flow-field with rich swirling particle streaks, a clear vortex focal point, and vivid rainbow color mapping over additive-blended trails — genuinely beautiful and clearly on-brief. Only knock is the low 22fps and it's a flow-field trail sim rather than true flui…
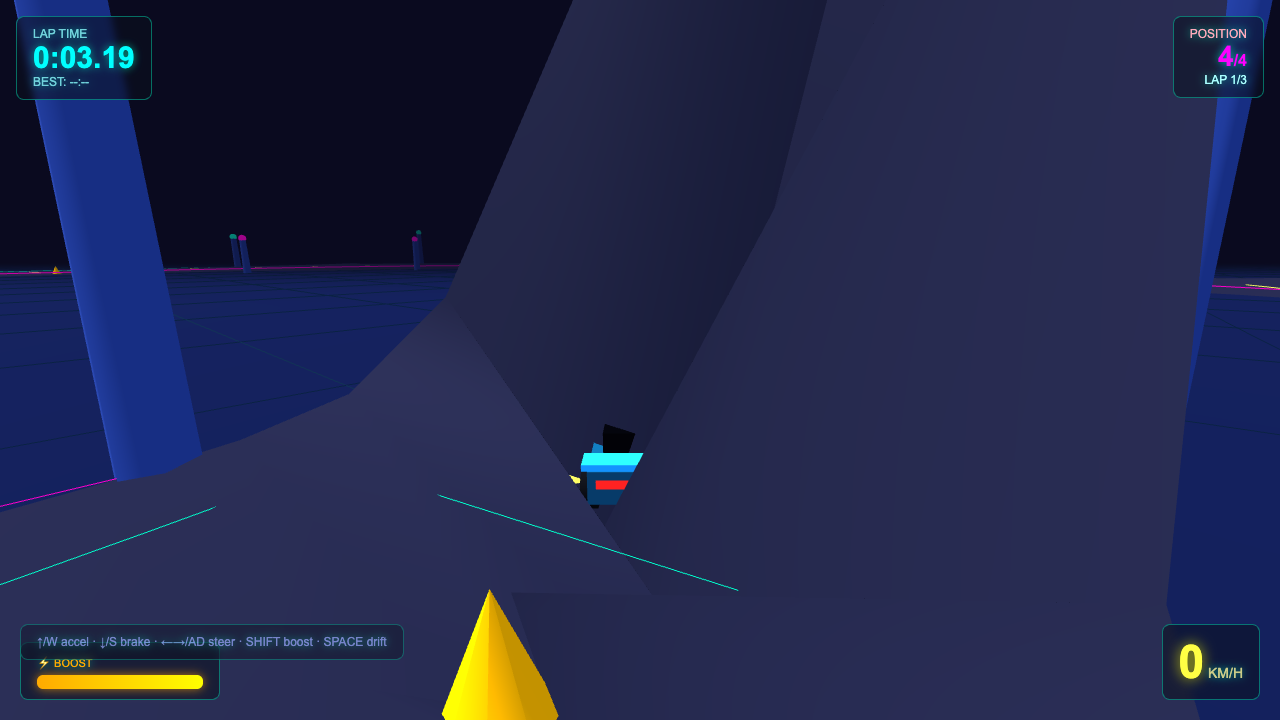
Neonracer
Game
Claude Sonnet 5 8.4
·
Opus 4.8 7.0
(+1.4)
· neon vapor trails
What I saw: Strong synthwave aesthetic with clean cyan/magenta neon edges, glowing grid floor, and vivid dual-color vapor trails behind the car — the particle effects are the standout. Slightly generic car model and empty upper sky hold it just below the top mark.
Fireworks
Visual
Claude Sonnet 5 8.3
·
Opus 4.8 7.0
(+1.3)
What I saw: Strong 3D scene with starfield, skyline silhouette, additive-blended particle bursts and a polished shimmering title—clearly on-brief and shippable. Particles read slightly blocky/square rather than glowing sparks, and the depth composition feels a touch flat, keeping it just shy…
Strengths & weaknesses I logged
Opus 4.8
Strengths
- Most consistent across the Goldie Bench bench — no weak build, 8.46/10 average
- Deepest one-shot reasoning, especially on game-feel and physics
- Extended thinking mode handles up to 1M tokens of context
Trade-offs
- 5–10× the per-token cost of every other model on the bench
- Less flair on cinematic visuals than GLM-5.2 — playing it safer wins on accuracy, costs you on showpiece moments
Claude Sonnet 5
Strengths
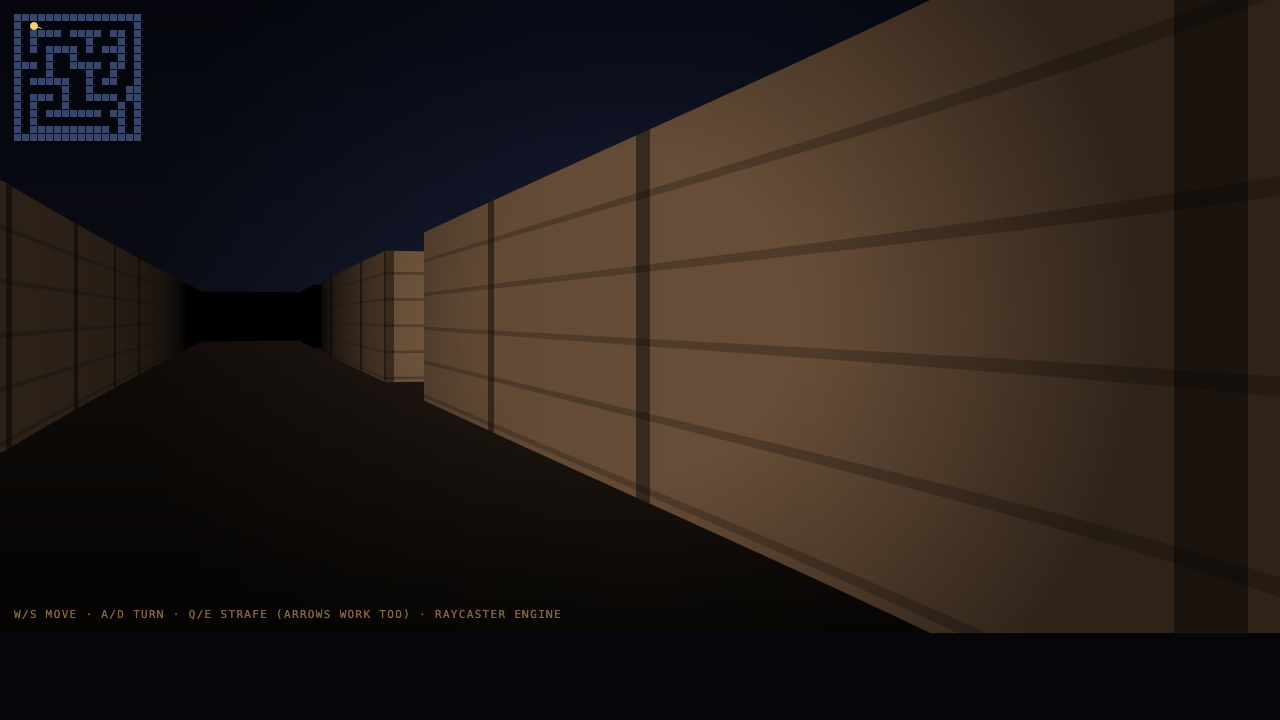
- 82.1% SWE-bench Verified — first model past 80% on real GitHub-issue repair
- Dev Team multi-agent mode + 1M context for repo-level agentic work
- Precision on hard logic — won the raycaster the open-weight field kept botching
Trade-offs
- One-shot creative-visual builds trail GLM 5.2 here (lost 4 of 5) — no iteration to catch its own bugs
- A temporal-dead-zone bug blanked its N-body orbit sim on the first shot
Pricing & context — the spec sheet
| Spec | Opus 4.8 | Claude Sonnet 5 |
|---|---|---|
| Vendor | Anthropic | Anthropic |
| Context window | 200,000 tokens (1M with extended thinking) | 1,000,000 tokens |
| Price | $15 / $75 per M tokens | $3 / $15 per M ($2/$10 intro) |
| Pricing detail | Premium pricing via the Anthropic API: $15 per million input tokens, $75 per million output tokens. Extended thinking is included but adds latency. | $3.00 input / $15.00 output per million tokens; introductory $2.00/$10.00 through 2026-08-31. |
| Release | 2026-05 | 2026-06-30 |
| Bench coverage | 42/42 scored · avg 7.49/10 | 42/42 scored · avg 7.18/10 |
The verdict — which should you pick?
Across 42 scored shared tasks, Opus 4.8 averaged 7.49/10, beating Claude Sonnet 5's 7.18/10 by 0.30 points. Pick Opus 4.8 when the build has to ship on the first prompt and you can afford the trade-offs in the comparison below.
If you only run one of these inside your stack, the head-to-head average above is the call. If you can run both, my honest play is to wire Opus 4.8 and Claude Sonnet 5 both into the Agent Operating System and dispatch each from the kanban by task type — mission-critical one-shot builds where 'has to work the first time' matters → Opus 4.8, agentic software engineering — write / run / test / fix loops on real repos → Claude Sonnet 5. That's the same setup I run for the 3,600+ founders inside the AI Profit Boardroom.
FAQ — Opus 4.8 vs Claude Sonnet 5
Which is better, Opus 4.8 or Claude Sonnet 5?
On Goldie Bench, Opus 4.8 averages 7.49/10 across the shared tasks, with 3 gold, 5 silver, 1 bronze overall. Claude Sonnet 5 averages 7.18/10, with 3 gold, 3 silver, 3 bronze. Claude Sonnet 5 wins the head-to-head 25–16.
How much does Opus 4.8 cost vs Claude Sonnet 5?
Opus 4.8: Premium pricing via the Anthropic API: $15 per million input tokens, $75 per million output tokens. Extended thinking is included but adds latency. Claude Sonnet 5: $3.00 input / $15.00 output per million tokens; introductory $2.00/$10.00 through 2026-08-31.
What's the context window for Opus 4.8 vs Claude Sonnet 5?
Opus 4.8 has a 200,000 tokens (1M with extended thinking) context window. Claude Sonnet 5 has a 1,000,000 tokens context window.
When should I pick Opus 4.8 over Claude Sonnet 5?
Pick Opus 4.8 for: Mission-critical one-shot builds where 'has to work the first time' matters; Hard reasoning tasks (planning, multi-step) where you'll pay for the depth; Anything where vendor reliability beats the per-token bill. The trade-off is the weaknesses we logged on the bench: 5–10× the per-token cost of every other model on the bench; Less flair on cinematic visuals than GLM-5.2 — playing it safer wins on accuracy, costs you on showpiece moments.
When should I pick Claude Sonnet 5 over Opus 4.8?
Pick Claude Sonnet 5 for: Agentic software engineering — write / run / test / fix loops on real repos; Repo-level reasoning across a 1M-token context (Dev Team multi-agent mode); Precise logic — raycasters, physics — where one-shot open models slip. The trade-off is the weaknesses we logged on the bench: One-shot creative-visual builds trail GLM 5.2 here (lost 4 of 5) — no iteration to catch its own bugs; A temporal-dead-zone bug blanked its N-body orbit sim on the first shot.
How does Goldie Bench score Opus 4.8 vs Claude Sonnet 5?
Every demo on this page was built by Julian Goldie inside the Agent Operating System — same fixed prompt for both models, one shot, single HTML file out. Each result gets a 0–10 score on whether it ran, how close it hit the brief, and how good it looked. The highest score on each task gets gold; second gets silver; third gets bronze. See methodology for full provenance.
Related comparisons
Other head-to-heads using the same scoring system:
Opus 4.8 vs Fusion Claude Sonnet 5 vs Fusion Opus 4.8 vs Hermes MoA Claude Sonnet 5 vs Hermes MoA Opus 4.8 vs Grok Claude Sonnet 5 vs Grok Opus 4.8 vs MiniMax M3 Claude Sonnet 5 vs MiniMax M3Full model pages: Opus 4.8 · Claude Sonnet 5 · back to the leaderboard
The same stack Julian uses
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.
3,600+founders
258documented wins
38countries
$59/momonthly