Opus 4.8
The reasoning king — deepest thinking, premium price.
Reference benchmarks for Opus 4.8
These are external benchmarks I pulled from the source comparison guides on agentos.guide — SWE-bench Verified, DRACO, Kilo plan rubric, build-time measurements, vendor-reported coding scores. They are not goldiebench medal scores (those come only from same-prompt one-shot creative coding tasks in the matrix). I surface them here so the spec sheet for Opus 4.8 is honest about what's measured.
What is Opus 4.8?
Opus 4.8 is the Anthropic frontier model with a 200,000 tokens (1M with extended thinking) context window, released 2026-05. Tagline: The reasoning king — deepest thinking, premium price.. Official source: anthropic.com/claude.
Pricing detail. Premium pricing via the Anthropic API: $15 per million input tokens, $75 per million output tokens. Extended thinking is included but adds latency.
How I use it inside the Agent OS. The default when the build has to ship on the first prompt — Opus is the safety net inside Agent OS for hard one-shots.
What I built with Opus 4.8
Every model on Goldie Bench gets the same fixed prompt set — one shot, single HTML file out — and I score the result 0–10 inside the Agent Operating System. Here's what Opus 4.8 shipped on the bench: 47 one-shot demos across 200,000 tokens (1M with extended thinking) of context. Of those, 47 are scored against the field with my honest 0–10 from the source guides at agentos.guide.
Strengths
- Most consistent across the Goldie Bench bench — no weak build, 8.46/10 average
- Deepest one-shot reasoning, especially on game-feel and physics
- Extended thinking mode handles up to 1M tokens of context
Trade-offs
- 5–10× the per-token cost of every other model on the bench
- Less flair on cinematic visuals than GLM-5.2 — playing it safer wins on accuracy, costs you on showpiece moments
Best for
- Mission-critical one-shot builds where 'has to work the first time' matters
- Hard reasoning tasks (planning, multi-step) where you'll pay for the depth
- Anything where vendor reliability beats the per-token bill
Every benchmark — Opus 4.8's full scorecard
All 47 scored tasks, best first — the judge's 0–10 on the same rubric as the whole field. Click any bar for that task's cross-model page, or open this scorecard in the interactive graphs. Full editorial breakdown with judge quotes and sourced outside research: the Opus 4.8 deep dive →.
Every demo by Opus 4.8
47 live demos, sorted by category. Click any tile to play the actual one-shot result. Verdicts and 0–10 scores are pulled from the source guides where I posted them publicly.
 ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE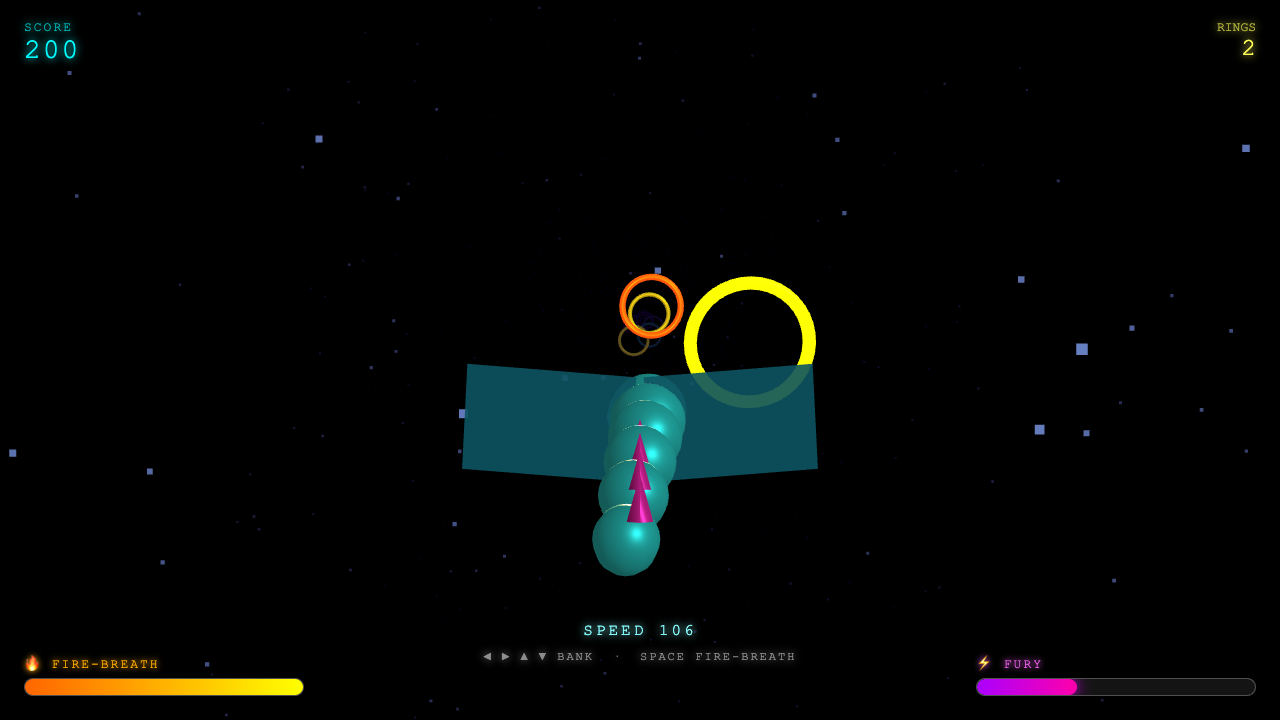 ▶ LIVE
▶ LIVE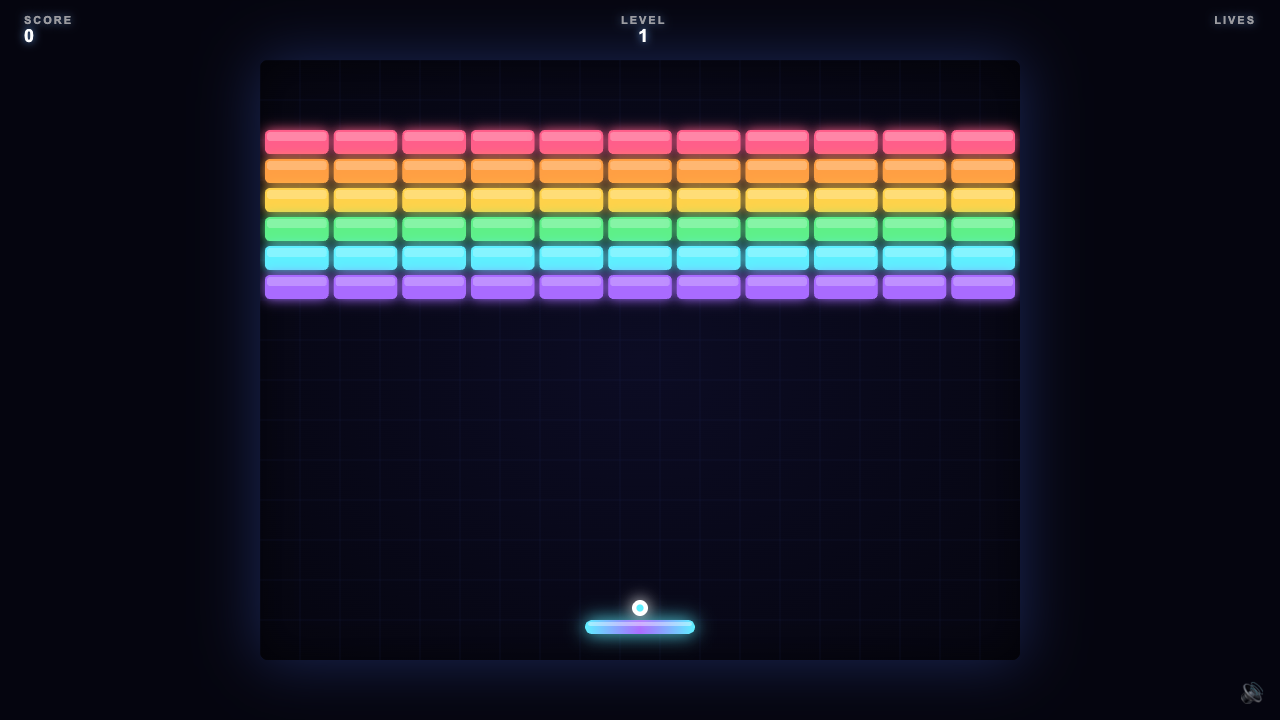 ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE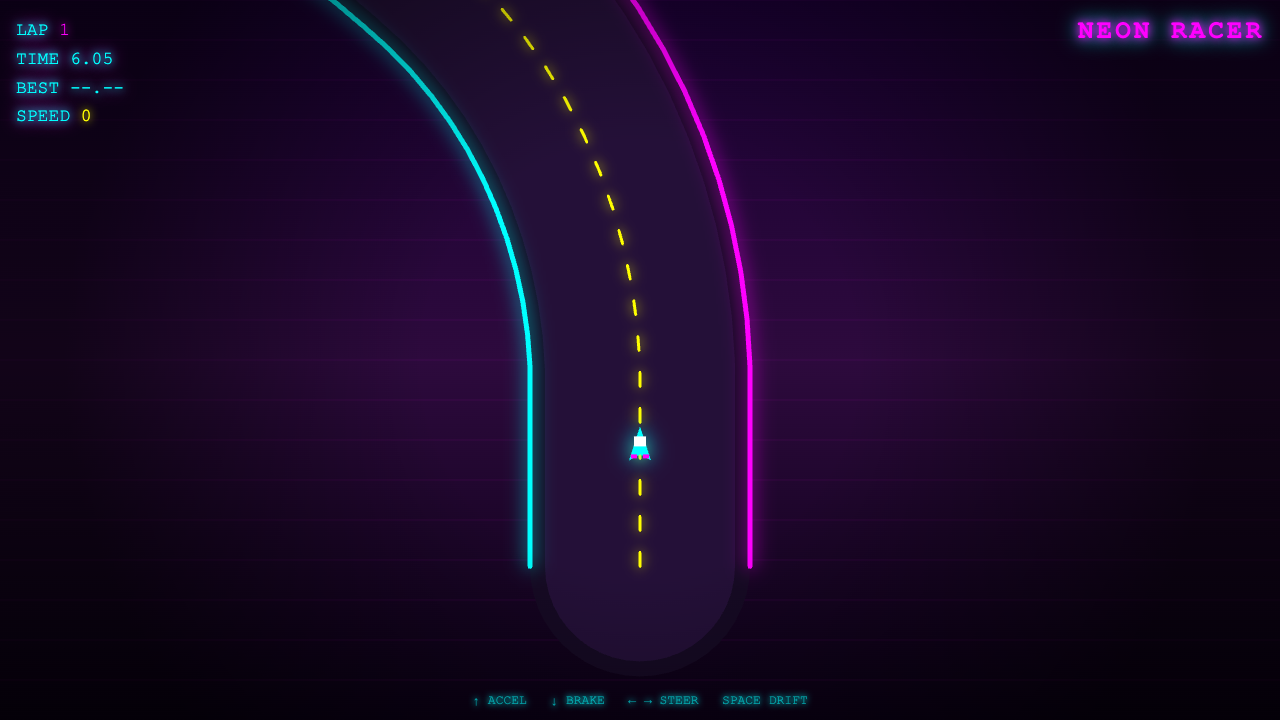 ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE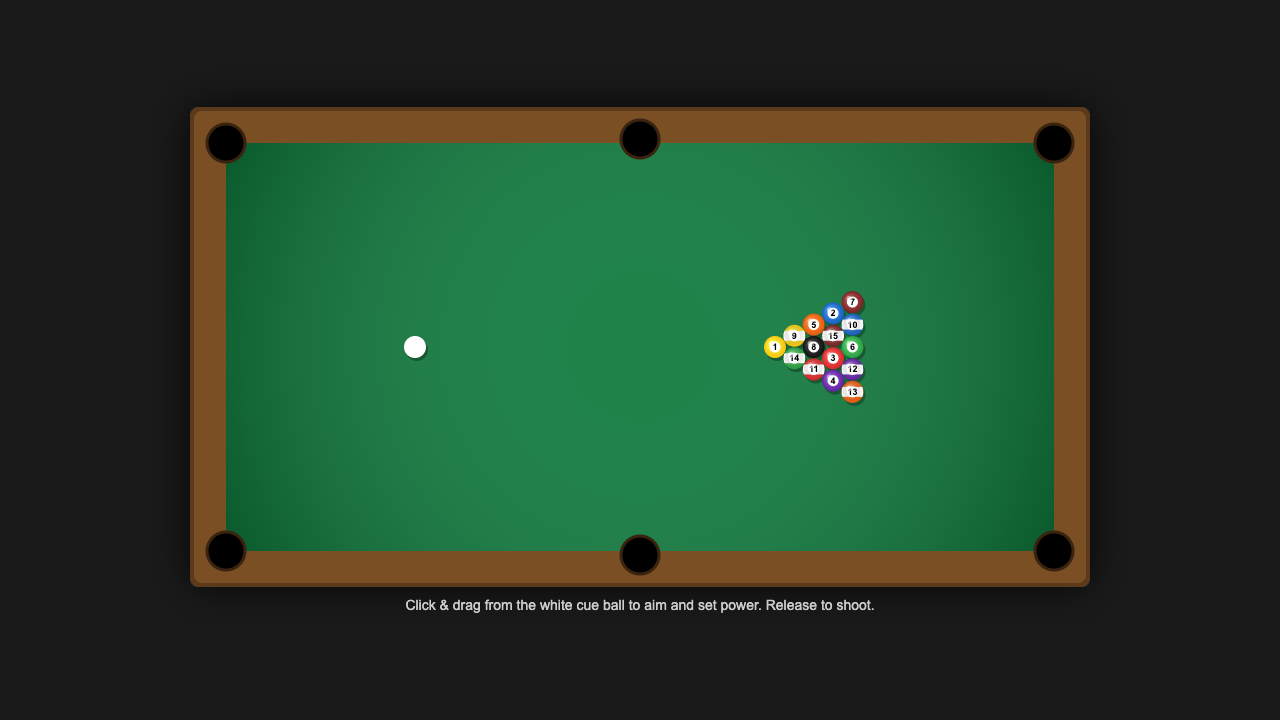 ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVECompare Opus 4.8 against every other model
Every head-to-head featuring Opus 4.8. Verdicts shown for scored pairs.
See all 66 comparisons across every model →
Quick pill index
Direct comparisons against every other scored model on the bench:
Opus 4.8 vs Fusion Opus 4.8 vs Claude Opus 5 Opus 4.8 vs Hermes MoA Opus 4.8 vs GPT-5.6 Sol Opus 4.8 vs Claude Fable 5 Opus 4.8 vs Qwen 3.8 Opus 4.8 vs Grok Opus 4.8 vs MiniMax M3 Opus 4.8 vs Fugu Ultra Opus 4.8 vs Kimi K3 Opus 4.8 vs GLM-5.2 Opus 4.8 vs Fugu Mini Opus 4.8 vs Kimi K2.7 Opus 4.8 vs Qwable 5 27B Coder Opus 4.8 vs Gemini 3.6 Flash Opus 4.8 vs Claude Sonnet 5 Opus 4.8 vs Qwen 3.7 Opus 4.8 vs Fugu Ultra 1.1 Opus 4.8 vs Inkling Opus 4.8 vs Agents-A1 Opus 4.8 vs Gemma 4 12B · MLX Opus 4.8 vs Laguna XS 2.1 Opus 4.8 vs Qwythos 9B Opus 4.8 vs LongCat-2.0 Opus 4.8 vs Hy3 Opus 4.8 vs Gemma-4 12B CoderRead more on agentos.guide: /opus-ultracode, /claude-fable-5, /glm-vs-kimi-vs-opus, /glm-vs-qwen-vs-opus
Opus 4.8 — frequently asked
What is Opus 4.8?
Opus 4.8 is Anthropic's AI model — The reasoning king — deepest thinking, premium price. It has a 200K tokens context window and was released 2026-05.
How good is Opus 4.8 at coding and one-shot builds?
On the GoldieBench one-shot build benchmark it averages 7.51/10 across 47 scored tasks, with 3 gold, 1 silver and 1 bronze medals.
How much does Opus 4.8 cost?
$15 / $75 per M tokens. Premium pricing via the Anthropic API: $15 per million input tokens, $75 per million output tokens. Extended thinking is included but adds latency.
Where can I see Opus 4.8 demos?
Every one-shot build is live and playable on this page and on the GoldieBench compare matrix — same prompt as every other model, no retries.
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 4,000+ founders shipping with it every day all live inside the AI Profit Boardroom.