Real head-to-head · same prompt, one shot
Fugu Ultra vs Opus 4.8
Sakana's multi-agent answer to Fusion — frontier ensemble without single-vendor risk. vs The reasoning king — deepest thinking, premium price.
Head-to-head verdict: tied 1–1.
What I tested — same prompt, two models
I run the same fixed prompt set through every new model the day it drops — same string, one shot, single HTML file out — and I score the result 0–10 on whether it ran, how close it hit the brief, and how good it looked. Below is what came out when I gave the exact same prompts to Fugu Ultra and Opus 4.8, side by side, on 4 shared tasks inside the Agent Operating System.
Both models were given identical prompts inside the Agent Operating System — no help, no iteration, no "best of N" tricks. I run each prompt once, save the HTML file the model produces, and score it 0–10 on whether it ran, how close it hit the brief, and how good it looked. The scoring is mine. The verdicts below are pulled from my source comparison guides at agentos.guide where I publish every score and the reasoning behind it.
Fugu Ultra · Dispatched from Agent OS as the panel-ensemble alternative to OpenRouter Fusion. Bench scored by Claude judge against the same 42 prompts as every other model.
Opus 4.8 · The default when the build has to ship on the first prompt — Opus is the safety net inside Agent OS for hard one-shots.
Side-by-side on 17 shared tasks
Click any cell to play that model's actual one-shot attempt. Medals are derived from my 0–10 scores per task (highest = 🥇, second = 🥈, third = 🥉).
Task ↓
Fugu Ultra
Opus 4.8
Game
Page
Sim


Sim
Game
— not attempted —
Game
— not attempted —

Game
— not attempted —

Game
— not attempted —

Sim
— not attempted —

Sim
— not attempted —
Sim
— not attempted —

Sim
— not attempted —

Sim
— not attempted —

Sim
— not attempted —

Sim
— not attempted —
Visual
— not attempted —
Visual
— not attempted —

Where Fugu Ultra beat Opus 4.8
The tasks where I gave Fugu Ultra a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
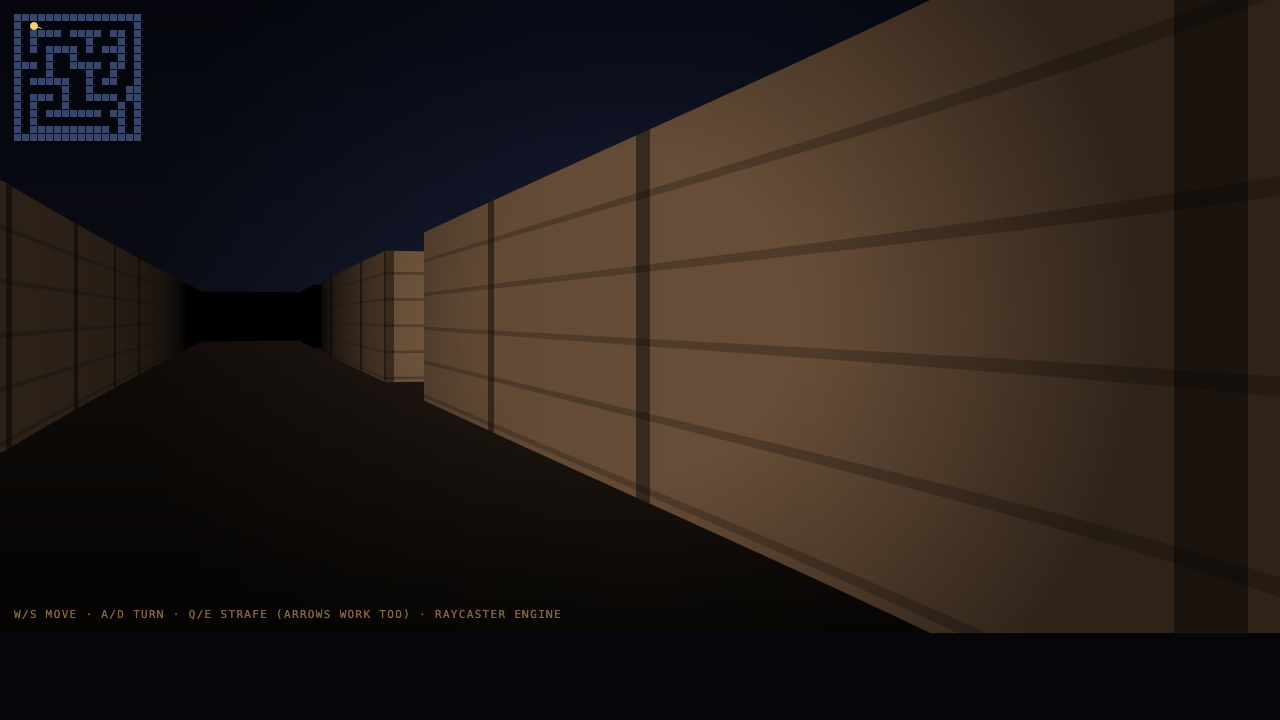
Raycaster
Game
Fugu Ultra 8.5
·
Opus 4.8 8.0
(+0.5)
What I saw: 26KB canvas raycaster with WASD + mouse-look + distance fog + weapon bob. Clean implementation, comparable to Fusion's 17KB on the same prompt. ~$0.35 per call — roughly 1/4 the cost of Fusion.
Where Opus 4.8 beat Fugu Ultra
The tasks where I gave Opus 4.8 a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
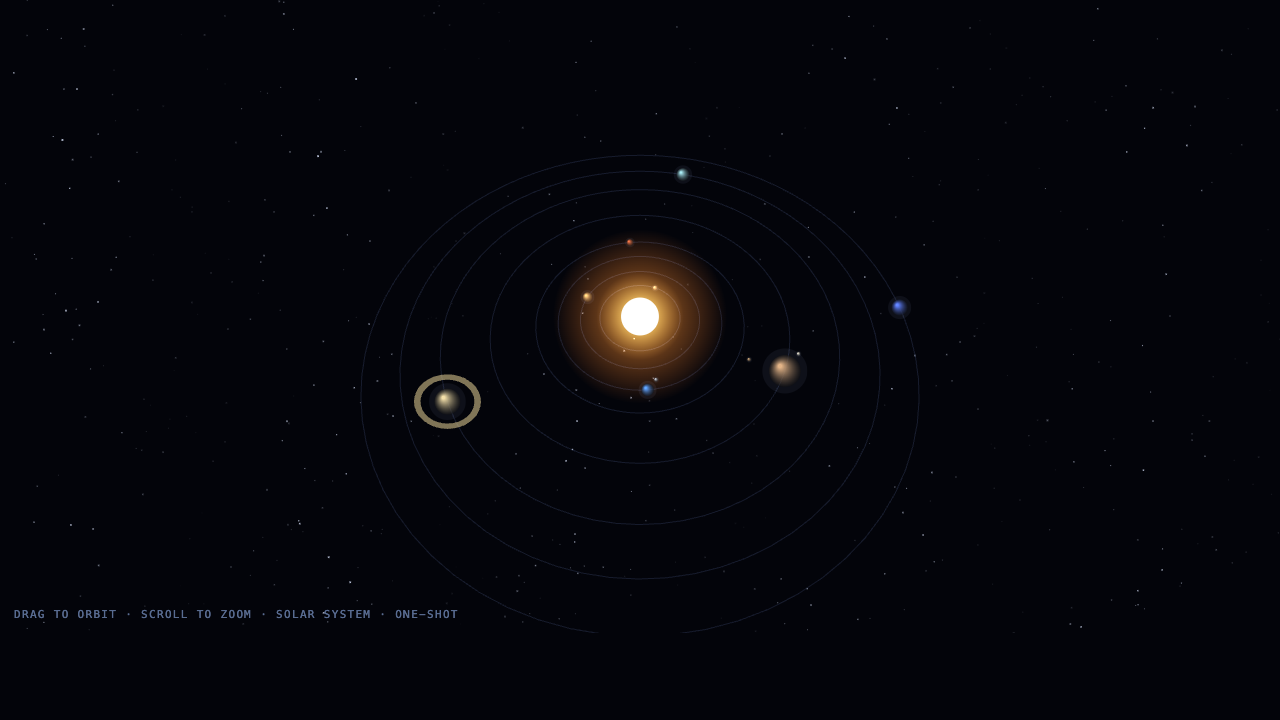
Orbit
Sim
Opus 4.8 9.0
·
Fugu Ultra 8.5
(+0.5)
· winner · accuracy
What I saw: Opus nailed the brief — labelled planet orbits, a real NEO / close-pass panel, a sim clock. GLM went for drama: a glowing nebula swirl that's gorgeous but reads more galaxy than orbit map. Kimi's is accurate but dim and sparse.
Strengths & weaknesses I logged
Fugu Ultra
Strengths
- SWE Bench Pro 73.7 · GPQA-D 95.5 · MRCRv2 93.6 — Sakana's published frontier-tier benchmark scores
- Vendor-agnostic ensemble — opt out of specific providers for compliance / export-control
- OpenAI-compatible API at api.sakana.ai — drop-in for existing tooling
Trade-offs
- Panel orchestration adds latency — even a 'pong' burns ~2k orchestration tokens
- Newer than Fusion; less community calibration on long-tail prompts
Opus 4.8
Strengths
- Most consistent across the Goldie Bench bench — no weak build, 8.46/10 average
- Deepest one-shot reasoning, especially on game-feel and physics
- Extended thinking mode handles up to 1M tokens of context
Trade-offs
- 5–10× the per-token cost of every other model on the bench
- Less flair on cinematic visuals than GLM-5.2 — playing it safer wins on accuracy, costs you on showpiece moments
Pricing & context — the spec sheet
| Spec | Fugu Ultra | Opus 4.8 |
|---|---|---|
| Vendor | Sakana AI | Anthropic |
| Context window | 272,000 tokens with the standard rate. Calls exceeding 272K context are billed at the higher 'long-context' rates. | 200,000 tokens (1M with extended thinking) |
| Price | $5 / 1M input · $30 / 1M output (Fugu Ultra) | $15 / $75 per M tokens |
| Pricing detail | Sakana's multi-agent orchestration: a single API call internally dispatches to multiple frontier models and synthesises the answer. Subscription plans run $20-$200/mo (Standard / Pro / Max); PAYG is $5/M input + $30/M output for Fugu Ultra. Direct competitor to OpenRouter Fusion's panel approach. | Premium pricing via the Anthropic API: $15 per million input tokens, $75 per million output tokens. Extended thinking is included but adds latency. |
| Release | 2026-06-15 | 2026-05 |
| Bench coverage | 4/4 scored · avg 8.62/10 | 13/17 scored · avg 8.46/10 |
The verdict — which should you pick?
Across 4 scored shared tasks, the averages are essentially tied — Fugu Ultra 8.62 vs Opus 4.8 8.62. This isn't the comparison where one wins; it's the comparison where you pick based on context, pricing, and what you're actually trying to ship.
If you only run one of these inside your stack, the head-to-head average above is the call. If you can run both, my honest play is to wire Fugu Ultra and Opus 4.8 both into the Agent Operating System and dispatch each from the kanban by task type — teams that want fusion-class quality but need a different vendor risk profile → Fugu Ultra, mission-critical one-shot builds where 'has to work the first time' matters → Opus 4.8. That's the same setup I run for the 3,600+ founders inside the AI Profit Boardroom.
FAQ — Fugu Ultra vs Opus 4.8
Which is better, Fugu Ultra or Opus 4.8?
On Goldie Bench, Fugu Ultra averages 8.62/10 across the shared tasks, with 3 gold, 1 silver, 0 bronze overall. Opus 4.8 averages 8.62/10, with 7 gold, 3 silver, 1 bronze. It's a curated tie on the head-to-head.
How much does Fugu Ultra cost vs Opus 4.8?
Fugu Ultra: Sakana's multi-agent orchestration: a single API call internally dispatches to multiple frontier models and synthesises the answer. Subscription plans run $20-$200/mo (Standard / Pro / Max); PAYG is $5/M input + $30/M output for Fugu Ultra. Direct competitor to OpenRouter Fusion's panel approach. Opus 4.8: Premium pricing via the Anthropic API: $15 per million input tokens, $75 per million output tokens. Extended thinking is included but adds latency.
What's the context window for Fugu Ultra vs Opus 4.8?
Fugu Ultra has a 272,000 tokens with the standard rate. Calls exceeding 272K context are billed at the higher 'long-context' rates. context window. Opus 4.8 has a 200,000 tokens (1M with extended thinking) context window.
When should I pick Fugu Ultra over Opus 4.8?
Pick Fugu Ultra for: Teams that want Fusion-class quality but need a different vendor risk profile; Operators avoiding export-controlled providers (Sakana emphasises this in their pitch); Deep-research workflows where ensemble verdicts beat single-model answers. The trade-off is the weaknesses we logged on the bench: Panel orchestration adds latency — even a 'pong' burns ~2k orchestration tokens; Newer than Fusion; less community calibration on long-tail prompts.
When should I pick Opus 4.8 over Fugu Ultra?
Pick Opus 4.8 for: Mission-critical one-shot builds where 'has to work the first time' matters; Hard reasoning tasks (planning, multi-step) where you'll pay for the depth; Anything where vendor reliability beats the per-token bill. The trade-off is the weaknesses we logged on the bench: 5–10× the per-token cost of every other model on the bench; Less flair on cinematic visuals than GLM-5.2 — playing it safer wins on accuracy, costs you on showpiece moments.
How does Goldie Bench score Fugu Ultra vs Opus 4.8?
Every demo on this page was built by Julian Goldie inside the Agent Operating System — same fixed prompt for both models, one shot, single HTML file out. Each result gets a 0–10 score on whether it ran, how close it hit the brief, and how good it looked. The highest score on each task gets gold; second gets silver; third gets bronze. See methodology for full provenance.
Related comparisons
Other head-to-heads using the same scoring system:
Fugu Ultra vs Fusion Opus 4.8 vs Fusion Fugu Ultra vs Fugu Mini Opus 4.8 vs Fugu Mini Fugu Ultra vs GLM-5.2 Opus 4.8 vs GLM-5.2 Fugu Ultra vs Grok Opus 4.8 vs GrokFull model pages: Fugu Ultra · Opus 4.8 · back to the leaderboard
The same stack Julian uses
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.
3,600+founders
258documented wins
38countries
$100k+/mocommunity MRR