Fugu Ultra
Sakana's multi-agent answer to Fusion — frontier ensemble without single-vendor risk.
Reference benchmarks for Fugu Ultra
These are external benchmarks I pulled from the source comparison guides on agentos.guide — SWE-bench Verified, DRACO, Kilo plan rubric, build-time measurements, vendor-reported coding scores. They are not goldiebench medal scores (those come only from same-prompt one-shot creative coding tasks in the matrix). I surface them here so the spec sheet for Fugu Ultra is honest about what's measured.
What is Fugu Ultra?
Fugu Ultra is the Sakana AI frontier model with a 272,000 tokens with the standard rate. Calls exceeding 272K context are billed at the higher 'long-context' rates. context window, released 2026-06-15. Tagline: Sakana's multi-agent answer to Fusion — frontier ensemble without single-vendor risk..
Pricing detail. Sakana's multi-agent orchestration: a single API call internally dispatches to multiple frontier models and synthesises the answer. Subscription plans run $20-$200/mo (Standard / Pro / Max); PAYG is $5/M input + $30/M output for Fugu Ultra. Direct competitor to OpenRouter Fusion's panel approach.
How I use it inside the Agent OS. Dispatched from Agent OS as the panel-ensemble alternative to OpenRouter Fusion. Bench scored by Claude judge against the same 42 prompts as every other model.
What I built with Fugu Ultra
Every model on Goldie Bench gets the same fixed prompt set — one shot, single HTML file out — and I score the result 0–10 inside the Agent Operating System. Here's what Fugu Ultra shipped on the bench: 5 one-shot demos across 272,000 tokens with the standard rate. Calls exceeding 272K context are billed at the higher 'long-context' rates. of context. Of those, 5 are scored against the field with my honest 0–10 from the source guides at agentos.guide.
Strengths
- SWE Bench Pro 73.7 · GPQA-D 95.5 · MRCRv2 93.6 — Sakana's published frontier-tier benchmark scores
- Vendor-agnostic ensemble — opt out of specific providers for compliance / export-control
- OpenAI-compatible API at api.sakana.ai — drop-in for existing tooling
Trade-offs
- Panel orchestration adds latency — even a 'pong' burns ~2k orchestration tokens
- Newer than Fusion; less community calibration on long-tail prompts
Best for
- Teams that want Fusion-class quality but need a different vendor risk profile
- Operators avoiding export-controlled providers (Sakana emphasises this in their pitch)
- Deep-research workflows where ensemble verdicts beat single-model answers
Every demo by Fugu Ultra
5 live demos, sorted by category. Click any tile to play the actual one-shot result. Verdicts and 0–10 scores are pulled from the source guides where I posted them publicly.
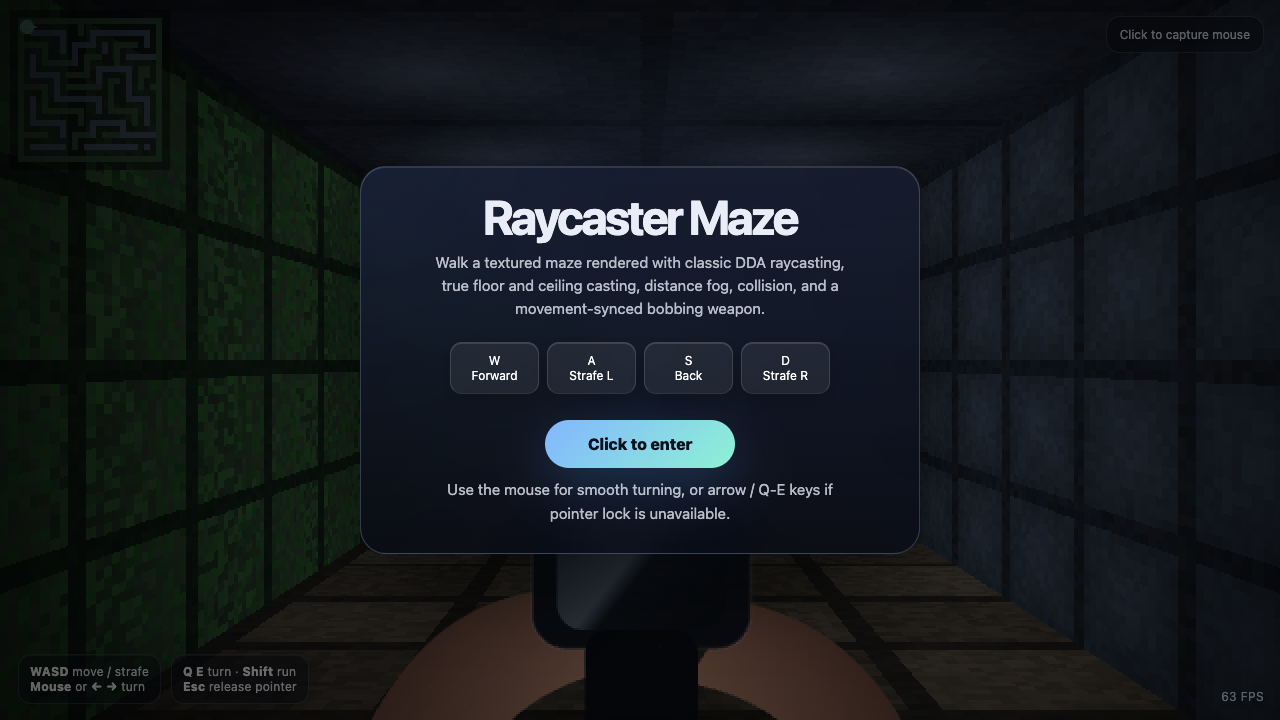 ▶ LIVE
▶ LIVE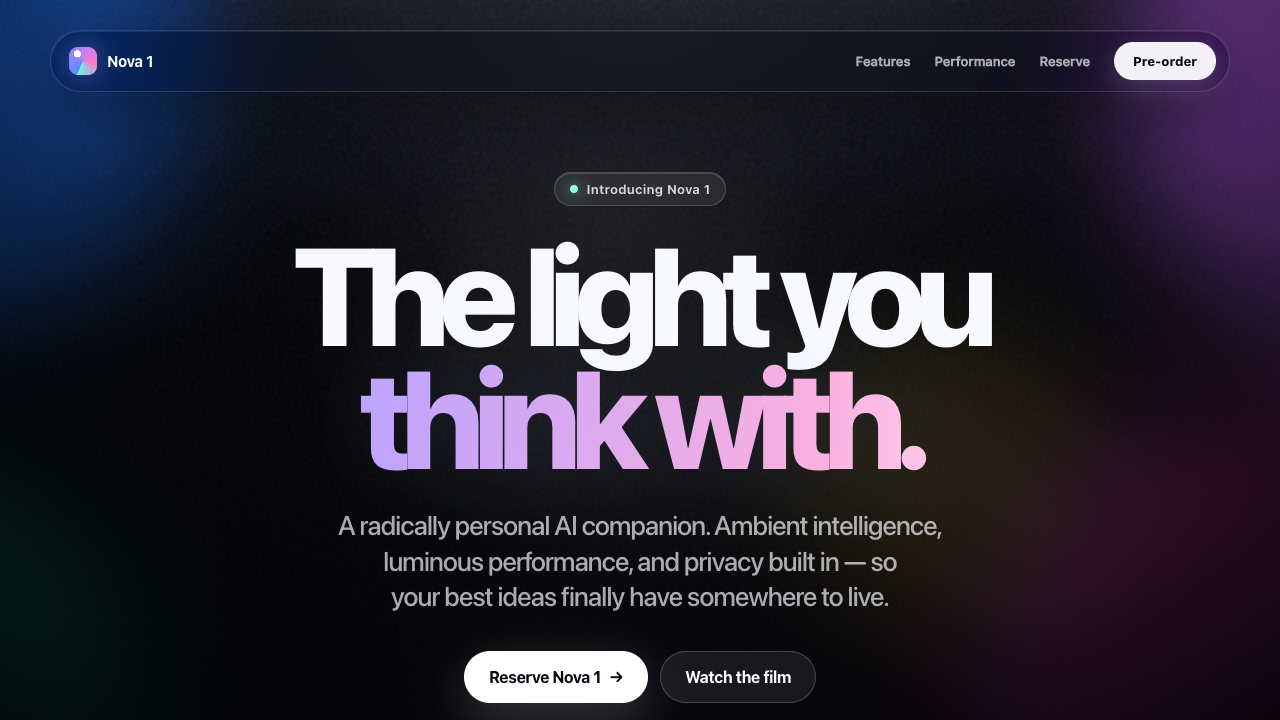 ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVE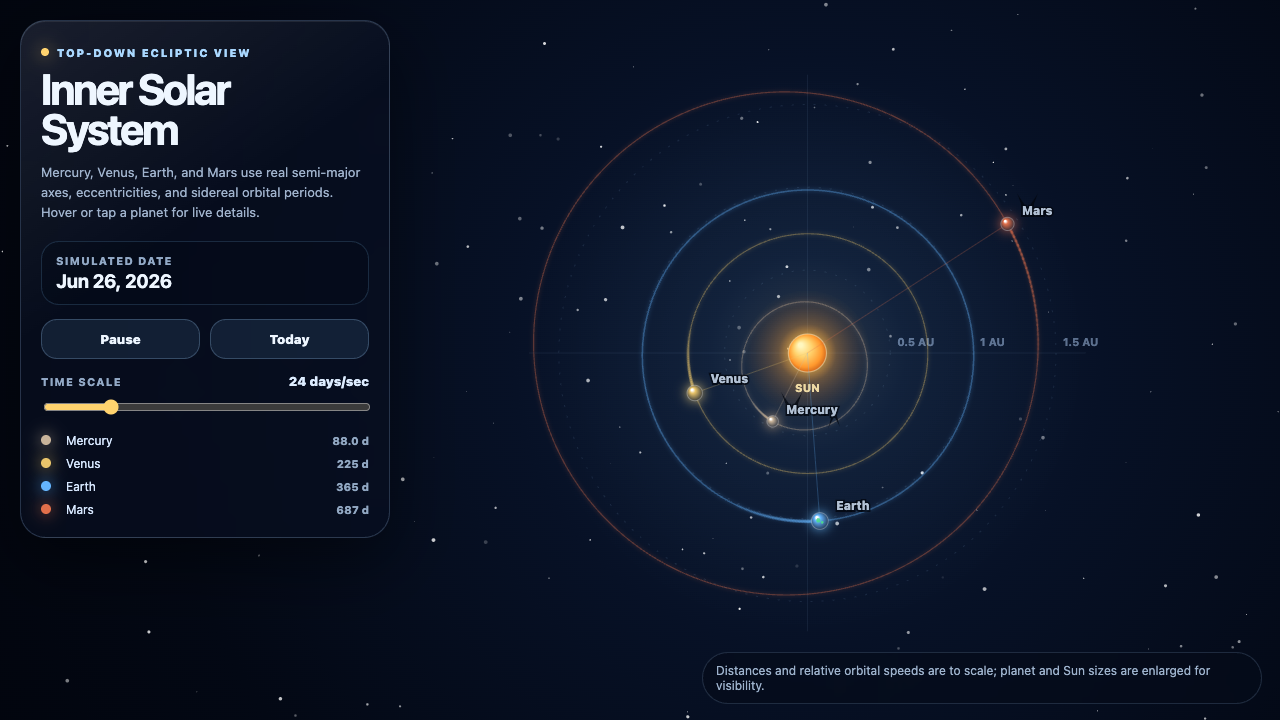 ▶ LIVE
▶ LIVE ▶ LIVE
▶ LIVECompare Fugu Ultra against every other model
Every head-to-head featuring Fugu Ultra. Verdicts shown for scored pairs.
See all 66 comparisons across every model →
Quick pill index
Direct comparisons against every other scored model on the bench:
Fugu Ultra vs Opus 4.8 Fugu Ultra vs GLM-5.2 Fugu Ultra vs Grok Fugu Ultra vs Fusion Fugu Ultra vs MiniMax M3 Fugu Ultra vs Qwen 3.7 Fugu Ultra vs Kimi K2.7 Fugu Ultra vs Fugu Mini Fugu Ultra vs Gemma-4 12B CoderRead more on agentos.guide: /sakana-fugu-vs-fusion
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.