Real head-to-head · same prompt, one shot
Hermes MoA vs Claude Sonnet 5
A panel of frontier models, merged by a chair. The model doesn't matter — the system does. vs The agentic SWE frontier — 82% SWE-bench Verified, Dev Team mode.
Head-to-head verdict: Hermes MoA wins 34–8.
What I tested — same prompt, two models
I run the same fixed prompt set through every new model the day it drops — same string, one shot, single HTML file out — and I score the result 0–10 on whether it ran, how close it hit the brief, and how good it looked. Below is what came out when I gave the exact same prompts to Hermes MoA and Claude Sonnet 5, side by side, on 42 shared tasks inside the Agent Operating System.
Both models were given identical prompts inside the Agent Operating System — no help, no iteration, no "best of N" tricks. I run each prompt once, save the HTML file the model produces, and score it 0–10 on whether it ran, how close it hit the brief, and how good it looked. The scoring is mine. The verdicts below are pulled from my source comparison guides at agentos.guide where I publish every score and the reasoning behind it.
Hermes MoA · Run from the Mixture tab in the Hermes Agent OS. On this bench the panel built each demo and the aggregator merged the best of every draft.
Claude Sonnet 5 · Reach for it in Agent OS when the job is iterative, tool-using software engineering. For one-shot visual builds, GLM 5.2 (free) beat it 4-1 here.
Side-by-side on 42 shared tasks
Click any cell to play that model's actual one-shot attempt. Medals are derived from my 0–10 scores per task (highest = 🥇, second = 🥈, third = 🥉).
Task ↓
Hermes MoA
Claude Sonnet 5
Game
Game


Game

Game

Game


Game


Game


Game
Game


Game


Game

Game


Game


Game


Game


Game

Game


Game

Game
Page
Page
Sim


Sim
Sim

Where Hermes MoA beat Claude Sonnet 5
The tasks where I gave Hermes MoA a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
Aurora
Visual
Hermes MoA 8.6
·
Claude Sonnet 5 2.5
(+6.1)
· most_detailed
What I saw: The richest aurora build in the field: layered ribbons with composite-lit gradients, vertical light rays, twinkling stars, a lake reflection (mirrored aurora + ripple shimmer), layered mountain silhouettes, occasional meteors, and smooth pointer-steering with color-shift on click…
Solar
Sim
Hermes MoA 8.6
·
Claude Sonnet 5 2.5
(+6.1)
What I saw: Genuinely the most astronomically accurate solar attempt on the bench — real J2000 Keplerian elements with eccentricity/inclination, √AU compression, proper orbit solving, banded gas-giant textures, dual rings, asteroid belt, and a polished glass UI with focus/info cards; edges o…
Wormhole
Sim
Hermes MoA 8.7
·
Claude Sonnet 5 3.0
(+5.7)
· hermes-moa
What I saw: A genuinely polished Three.js wormhole: curved spline tunnel path (not just a straight tube), additive wireframe rings, particles, speed streaks, glow sprites, FOV-warp on boost, and clean pointer-steer + wheel-speed + hold-to-boost controls with HSL color cycling and a vignette.…
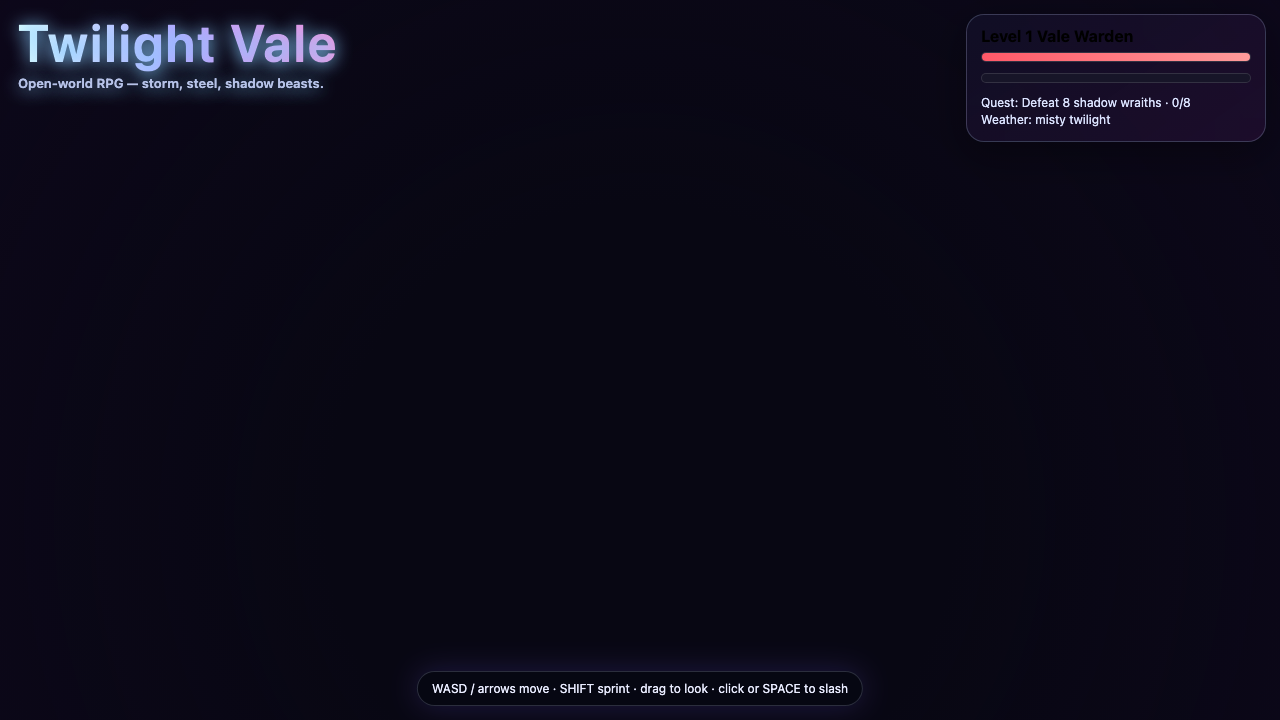
Twilightvale
Game
Hermes MoA 8.4
·
Claude Sonnet 5 3.0
(+5.4)
What I saw: Polished single-file three.js RPG with instanced trees/rocks, procedural terrain+river, weather/day-night, enemies with health bars, slash combat, and mobile controls — clearly beats SOLO Opus 4.8 (7.5) and is shippable. But it's lighter on open-world density than the leaders (Gr…
Orbit
Sim
Hermes MoA 8.4
·
Claude Sonnet 5 3.5
(+4.9)
What I saw: A genuinely well-crafted live N-body gravity sandbox — spiral-arm seeding, momentum-zeroed COM, softening, sub-stepping, drag-to-launch and a center-of-mass camera all work, with polished glassmorphic UI and trails that read beautifully. It interprets 'orbit' as emergent chaos ra…
Where Claude Sonnet 5 beat Hermes MoA
The tasks where I gave Claude Sonnet 5 a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
Fluid
Sim
Claude Sonnet 5 8.6
·
Hermes MoA 7.8
(+0.8)
· gorgeous flow field
What I saw: Stunning rendered flow-field with rich swirling particle streaks, a clear vortex focal point, and vivid rainbow color mapping over additive-blended trails — genuinely beautiful and clearly on-brief. Only knock is the low 22fps and it's a flow-field trail sim rather than true flui…
Neonracer
Game
Claude Sonnet 5 8.4
·
Hermes MoA 7.8
(+0.6)
· neon vapor trails
What I saw: Strong synthwave aesthetic with clean cyan/magenta neon edges, glowing grid floor, and vivid dual-color vapor trails behind the car — the particle effects are the standout. Slightly generic car model and empty upper sky hold it just below the top mark.
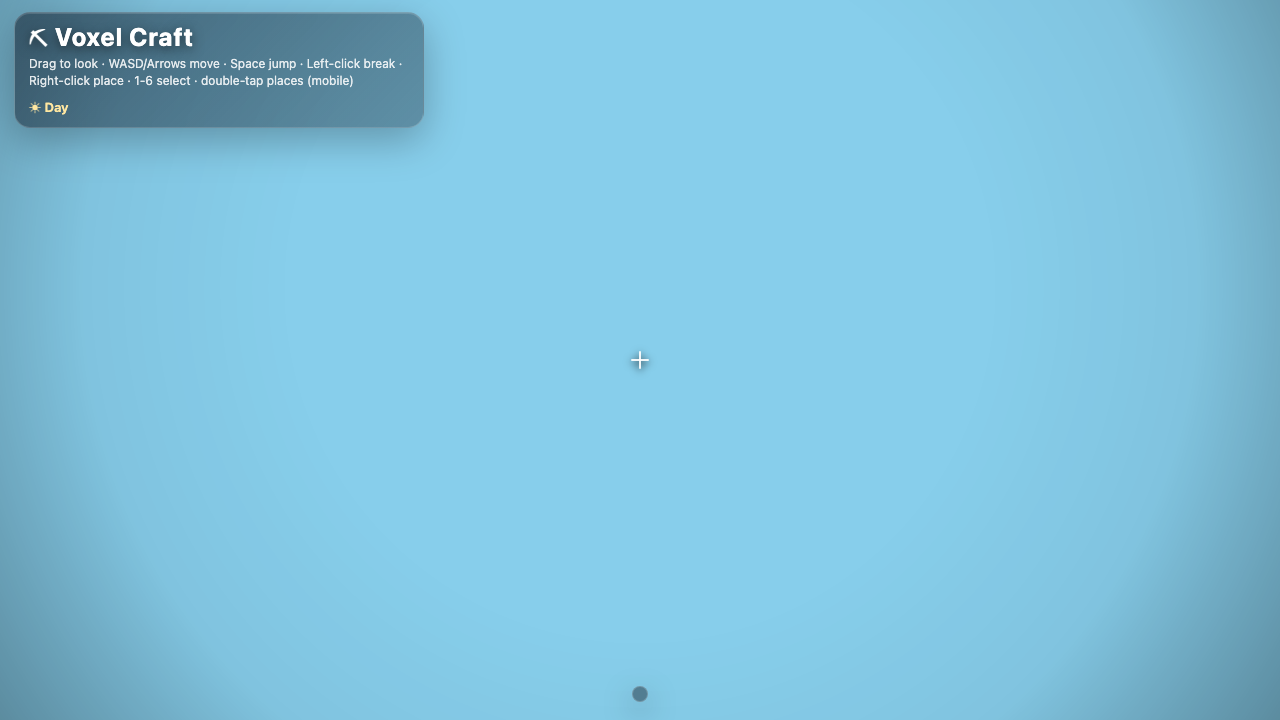
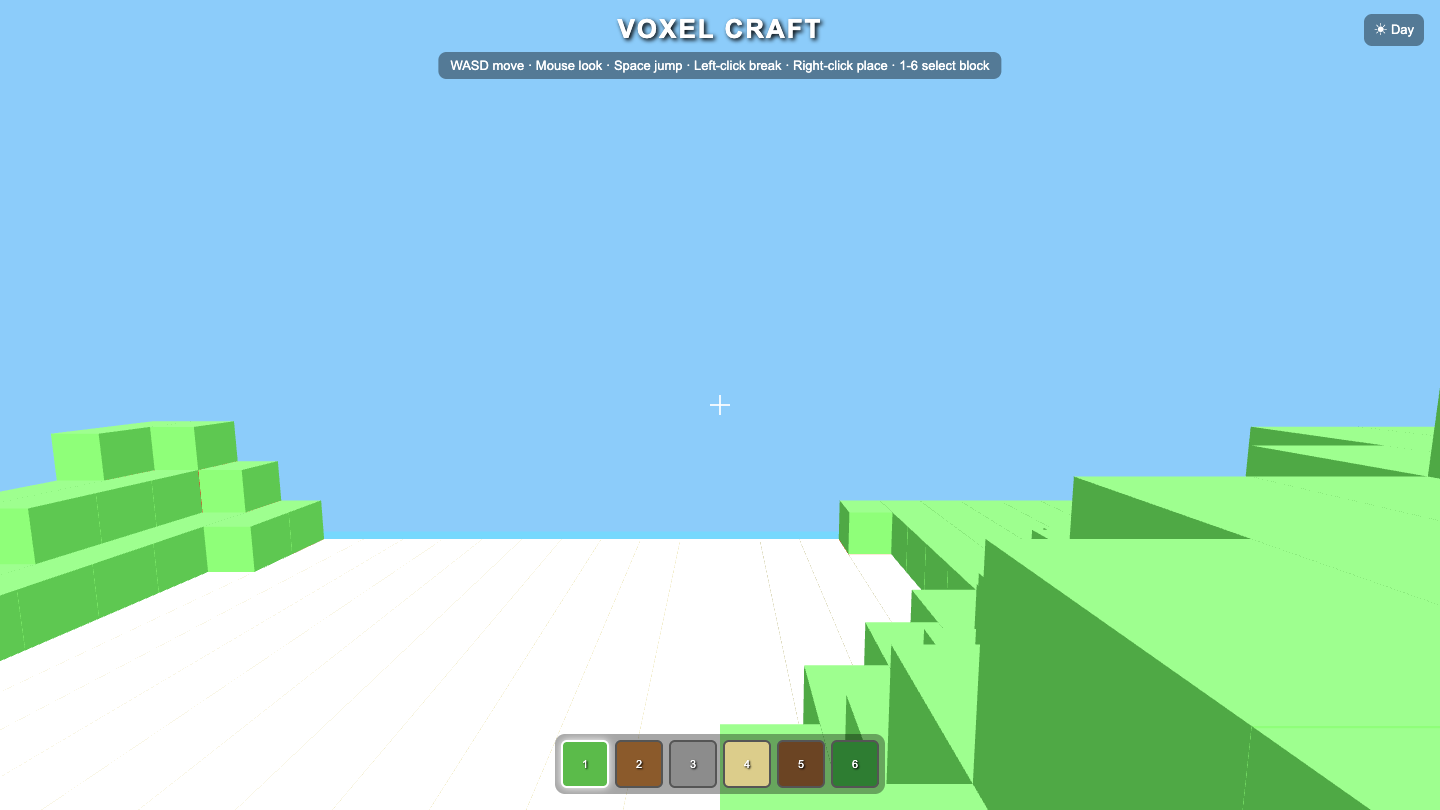
Voxel
Visual
Claude Sonnet 5 8.4
·
Hermes MoA 7.8
(+0.6)
What I saw: Strong, polished voxel island with clean biome layering (sand/grass/stone/snow), soft shadows, trees, translucent water and clear orbit/zoom/WASD controls — very on-brief. Falls just short of the top: the terrain reads a bit flat/small and the stone plateau looks like a slightly …
Pathtracer
Sim
Claude Sonnet 5 8.6
·
Hermes MoA 8.0
(+0.6)
· Converged Cornell box
What I saw: Renders a genuine progressively-converged Cornell box with correct red/green colored-wall bleed, a diffuse yellow sphere, and convincing glass and metal spheres showing refraction/reflection at 163 samples — physically-plausible and clearly on-brief. Minor grain and the truncated…
Racing
Game
Claude Sonnet 5 8.2
·
Hermes MoA 7.8
(+0.4)
What I saw: Strong, clean third-person render with proper checkered finish line, striped curbs, low-poly trees, HUD, and a functioning minimap showing scattered obstacles; polished and shippable but the ring track and generic box-car keep it just short of the field's best.
Strengths & weaknesses I logged
Hermes MoA
Strengths
- On GoldieBench, the MoA panel's galaxy edged solo Opus 4.8 — 8.6 vs 8.5 — with a denser 24k-particle spiral (the system beats the model)
- Two gold + one silver across its first three one-shot builds (galaxy, fireworks, arcade)
- Vendor-agnostic — swap any OpenRouter model into a panel or aggregator slot without touching the workflow
Trade-offs
- Latency is the panel's slowest draft plus the aggregator pass — ~110–140s per single-file build vs a solo model's one call
- Costs more per task than any single model (every panel slot + the aggregator are separate calls)
- Only 3 of 42 bench tasks run so far — a representative slice, not the full board
Claude Sonnet 5
Strengths
- 82.1% SWE-bench Verified — first model past 80% on real GitHub-issue repair
- Dev Team multi-agent mode + 1M context for repo-level agentic work
- Precision on hard logic — won the raycaster the open-weight field kept botching
Trade-offs
- One-shot creative-visual builds trail GLM 5.2 here (lost 4 of 5) — no iteration to catch its own bugs
- A temporal-dead-zone bug blanked its N-body orbit sim on the first shot
Pricing & context — the spec sheet
| Spec | Hermes MoA | Claude Sonnet 5 |
|---|---|---|
| Vendor | Hermes · Mixture of Agents | Anthropic |
| Context window | Varies — the sum of the panel models' contexts (Opus 4.8 + GPT-5.5) | 1,000,000 tokens |
| Price | Panel + aggregator calls (via OpenRouter) | $3 / $15 per M ($2/$10 intro) |
| Pricing detail | Hermes Mixture of Agents dispatches one prompt to a configurable panel of frontier models in parallel, then a named aggregator reads every draft and writes one better final answer. Default panel: Claude Opus 4.8 + GPT-5.5, aggregated by Opus 4.8 — all via the OpenRouter key. Unlike a black-box ensemble, every slot is yours to swap from the Mixture tab in the Agent OS. | $3.00 input / $15.00 output per million tokens; introductory $2.00/$10.00 through 2026-08-31. |
| Release | 2026-06-28 | 2026-06-30 |
| Bench coverage | 42/42 scored · avg 8.38/10 | 42/42 scored · avg 7.18/10 |
The verdict — which should you pick?
Across 42 scored shared tasks, Hermes MoA averaged 8.38/10, beating Claude Sonnet 5's 7.18/10 by 1.20 points. Pick Hermes MoA when the build has to ship on the first prompt and you can afford the trade-offs in the comparison below.
If you only run one of these inside your stack, the head-to-head average above is the call. If you can run both, my honest play is to wire Hermes MoA and Claude Sonnet 5 both into the Agent Operating System and dispatch each from the kanban by task type — high-stakes single prompts where ensemble quality beats single-model speed → Hermes MoA, agentic software engineering — write / run / test / fix loops on real repos → Claude Sonnet 5. That's the same setup I run for the 3,600+ founders inside the AI Profit Boardroom.
FAQ — Hermes MoA vs Claude Sonnet 5
Which is better, Hermes MoA or Claude Sonnet 5?
On Goldie Bench, Hermes MoA averages 8.38/10 across the shared tasks, with 12 gold, 7 silver, 4 bronze overall. Claude Sonnet 5 averages 7.18/10, with 3 gold, 3 silver, 3 bronze. Hermes MoA wins the head-to-head 34–8.
How much does Hermes MoA cost vs Claude Sonnet 5?
Hermes MoA: Hermes Mixture of Agents dispatches one prompt to a configurable panel of frontier models in parallel, then a named aggregator reads every draft and writes one better final answer. Default panel: Claude Opus 4.8 + GPT-5.5, aggregated by Opus 4.8 — all via the OpenRouter key. Unlike a black-box ensemble, every slot is yours to swap from the Mixture tab in the Agent OS. Claude Sonnet 5: $3.00 input / $15.00 output per million tokens; introductory $2.00/$10.00 through 2026-08-31.
What's the context window for Hermes MoA vs Claude Sonnet 5?
Hermes MoA has a Varies — the sum of the panel models' contexts (Opus 4.8 + GPT-5.5) context window. Claude Sonnet 5 has a 1,000,000 tokens context window.
When should I pick Hermes MoA over Claude Sonnet 5?
Pick Hermes MoA for: High-stakes single prompts where ensemble quality beats single-model speed; Squeezing frontier-plus output from models you already have while Fable 5 / GPT-5.6 are still in preview; Production agents that want a configurable panel + vendor-redundancy on every call. The trade-off is the weaknesses we logged on the bench: Latency is the panel's slowest draft plus the aggregator pass — ~110–140s per single-file build vs a solo model's one call; Costs more per task than any single model (every panel slot + the aggregator are separate calls); Only 3 of 42 bench tasks run so far — a representative slice, not the full board.
When should I pick Claude Sonnet 5 over Hermes MoA?
Pick Claude Sonnet 5 for: Agentic software engineering — write / run / test / fix loops on real repos; Repo-level reasoning across a 1M-token context (Dev Team multi-agent mode); Precise logic — raycasters, physics — where one-shot open models slip. The trade-off is the weaknesses we logged on the bench: One-shot creative-visual builds trail GLM 5.2 here (lost 4 of 5) — no iteration to catch its own bugs; A temporal-dead-zone bug blanked its N-body orbit sim on the first shot.
How does Goldie Bench score Hermes MoA vs Claude Sonnet 5?
Every demo on this page was built by Julian Goldie inside the Agent Operating System — same fixed prompt for both models, one shot, single HTML file out. Each result gets a 0–10 score on whether it ran, how close it hit the brief, and how good it looked. The highest score on each task gets gold; second gets silver; third gets bronze. See methodology for full provenance.
Related comparisons
Other head-to-heads using the same scoring system:
Hermes MoA vs Fusion Claude Sonnet 5 vs Fusion Hermes MoA vs Grok Claude Sonnet 5 vs Grok Hermes MoA vs MiniMax M3 Claude Sonnet 5 vs MiniMax M3 Hermes MoA vs Fugu Ultra Claude Sonnet 5 vs Fugu UltraFull model pages: Hermes MoA · Claude Sonnet 5 · back to the leaderboard
The same stack Julian uses
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.
3,600+founders
258documented wins
38countries
$59/momonthly