
Real head-to-head · same prompt, one shot
Claude Fable 5 vs Fugu Mini
The newest Anthropic model — first Mythos-class made generally available. vs Fugu's fast mini variant — single model, no panel, ~3 min per build.
Head-to-head verdict: Claude Fable 5 wins 22–12 with 2 ties.
What I tested — same prompt, two models
I run the same fixed prompt set through every new model the day it drops — same string, one shot, single HTML file out — and I score the result 0–10 on whether it ran, how close it hit the brief, and how good it looked. Below is what came out when I gave the exact same prompts to Claude Fable 5 and Fugu Mini, side by side, on 37 shared tasks inside the Agent Operating System.
Both models were given identical prompts inside the Agent Operating System — no help, no iteration, no "best of N" tricks. I run each prompt once, save the HTML file the model produces, and score it 0–10 on whether it ran, how close it hit the brief, and how good it looked. The scoring is mine. The verdicts below are pulled from my source comparison guides at agentos.guide where I publish every score and the reasoning behind it.
Claude Fable 5 · Selected from Agent OS for the highest-stakes work — it replaced Opus 4.8 as the safety net on hard prompts. Its four core 3D games were rebuilt to showcase quality with the threejs-game-director skill, lifting the full 42-task bench to 8.14 avg — the #1 solo model, behind only the Fusion and MoA ensembles.
Fugu Mini · Dispatched from Agent OS as the fast Sakana lane. Bench scored by Claude judge against the same 42 prompts.
Side-by-side on 42 shared tasks
Click any cell to play that model's actual one-shot attempt. Medals are derived from my 0–10 scores per task (highest = 🥇, second = 🥈, third = 🥉).
Task ↓
Claude Fable 5
Fugu Mini
Game

Game

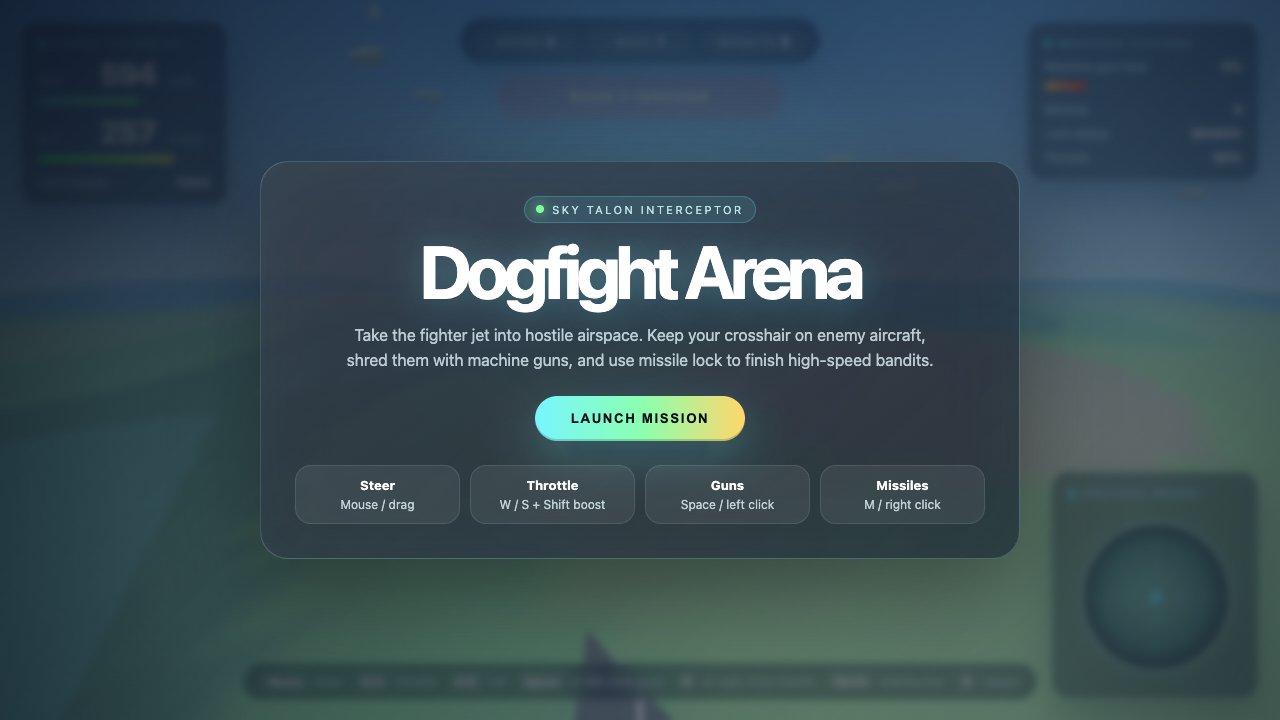
Game


Game

Game


Game


Game


Game


Game


Game


Game

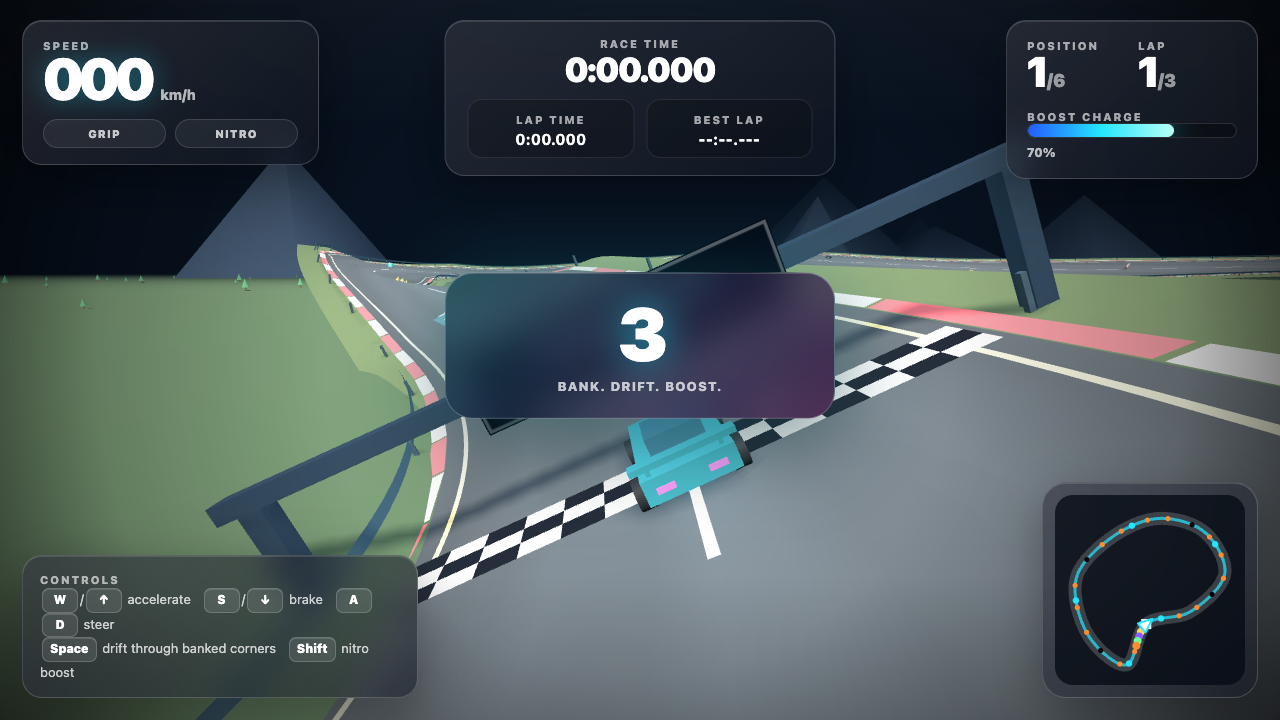
Game


Game
Game

Page
Page
Sim


Sim
Sim

Sim


Sim

Sim

Sim

Sim

Where Claude Fable 5 beat Fugu Mini
The tasks where I gave Claude Fable 5 a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
Aurora
Visual
Claude Fable 5 8.6
·
Fugu Mini 6.5
(+2.1)
· shader aurora curtains
What I saw: Beautiful WebGL fragment shader with layered green-blue aurora ribbons, twinkling starfield, snow-rimmed mountain silhouette, and elegant title typography — genuinely convincing northern lights. Interactive mouse sway and click surge plus the reflected glow push it to task-topping polish.
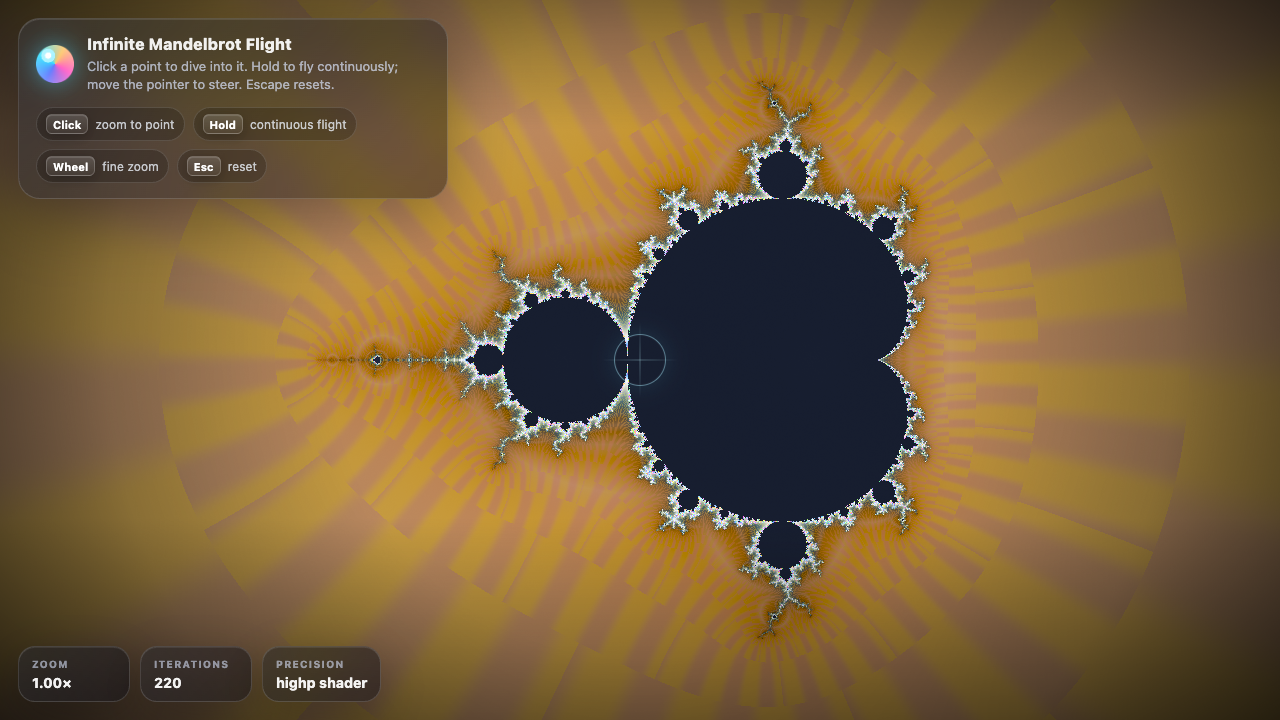
Fractal
Sim
Claude Fable 5 8.4
·
Fugu Mini 6.5
(+1.9)
· Crisp GPU Mandelbrot
What I saw: Renders a clean, high-iteration Mandelbrot with sharp filament detail and a rich red/blue gradient, plus full pan/zoom/pinch, Julia toggle, morphing constant, and autoplay zoom. Very strong and shippable; slightly generic palette and the deep-zoom float precision limit keep it ju…
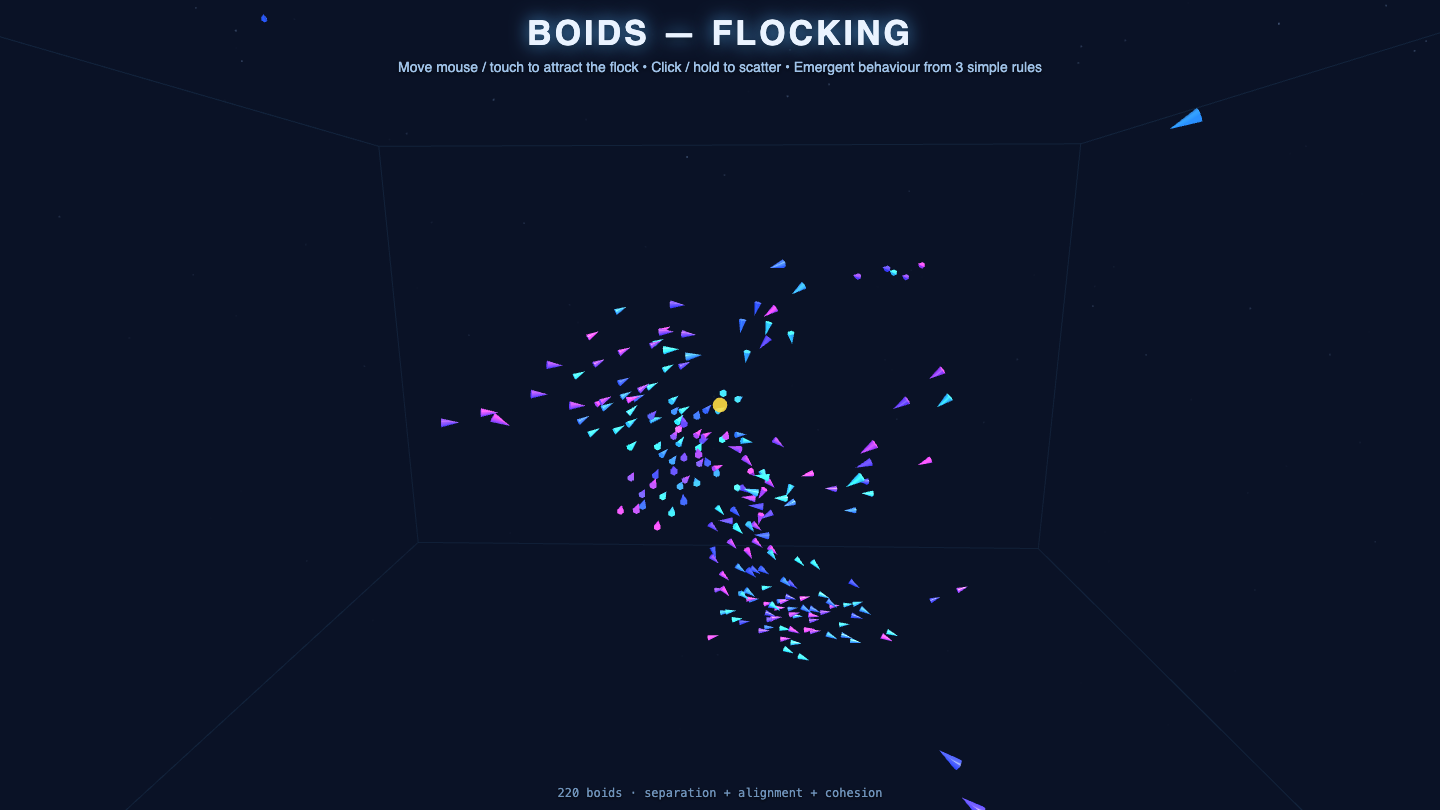
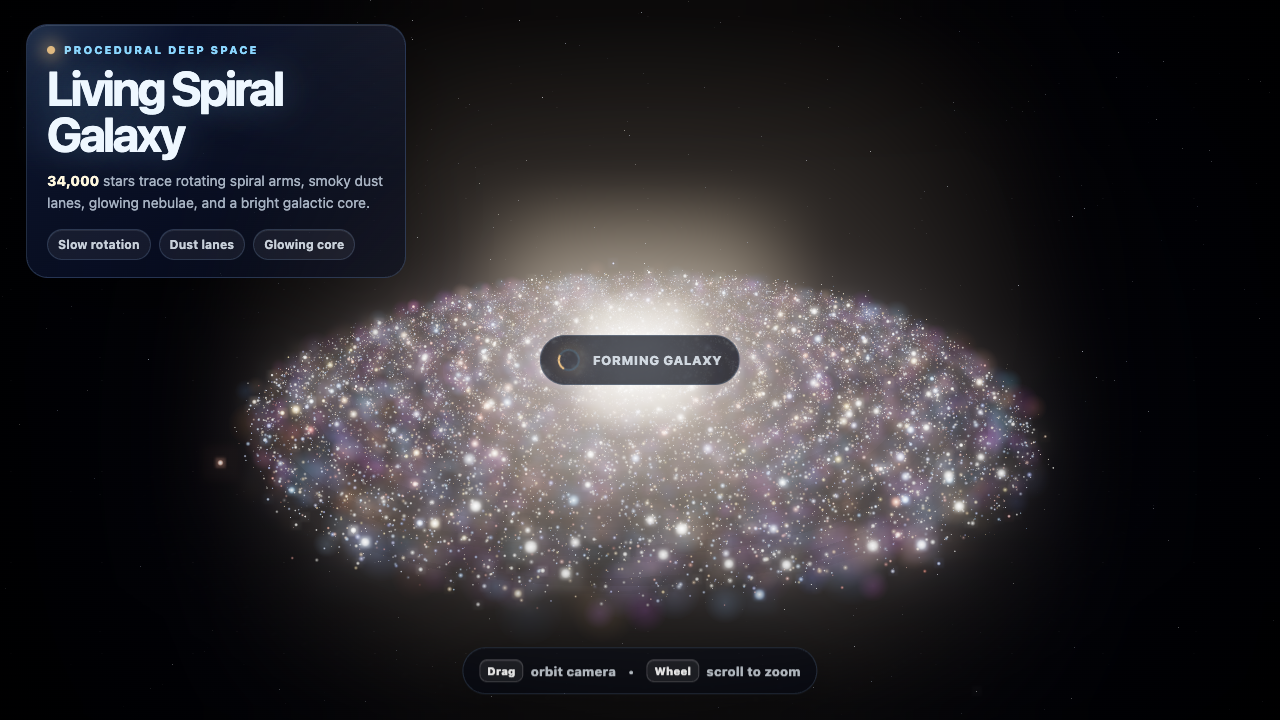
Galaxy
Sim
Claude Fable 5 8.4
·
Fugu Mini 6.5
(+1.9)
What I saw: Strong render with a convincing spiral disk, warm-core-to-blue-outer color gradient, glowing core, background starfield, and inertia-based swirl/zoom controls. Spiral arms read as slightly diffuse rather than crisp tight lanes, keeping it just shy of the top-of-field best.
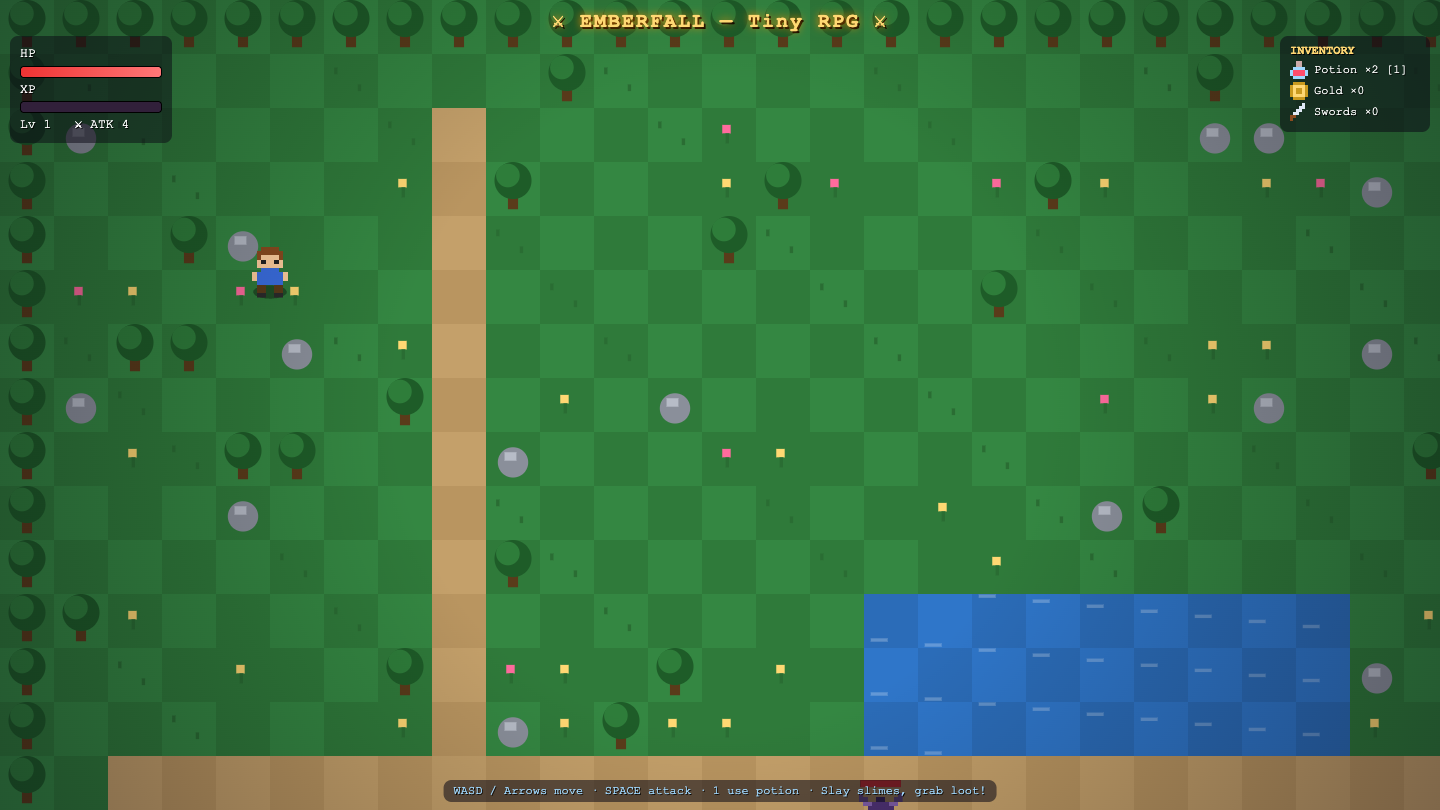
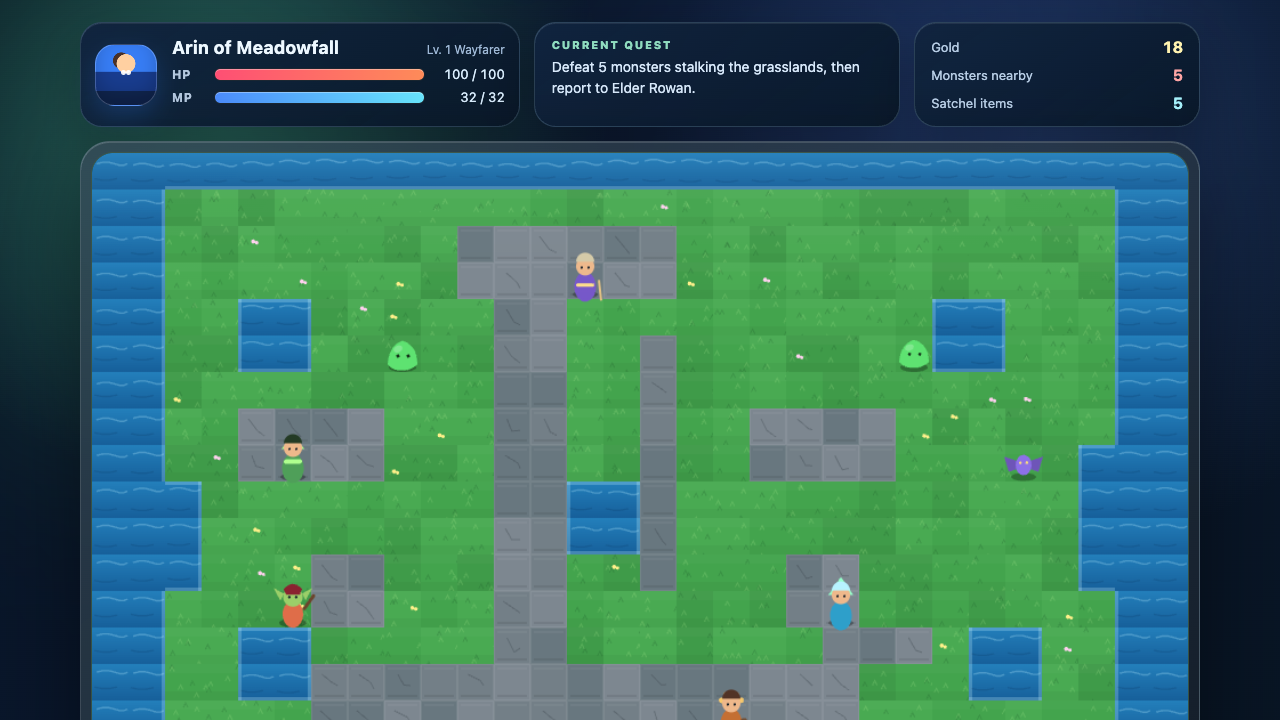
Rpg
Game
Claude Fable 5 8.4
·
Fugu Mini 6.5
(+1.9)
What I saw: Iterated rebuild renders a polished top-down Emberfall RPG: a checkerboard overworld with trees, a dirt path, a lake, scattered loot, a readable pixel hero and a green slime enemy with an HP bar, plus HP/XP/level/ATK and an inventory panel. Move and attack respond (verified) — st…
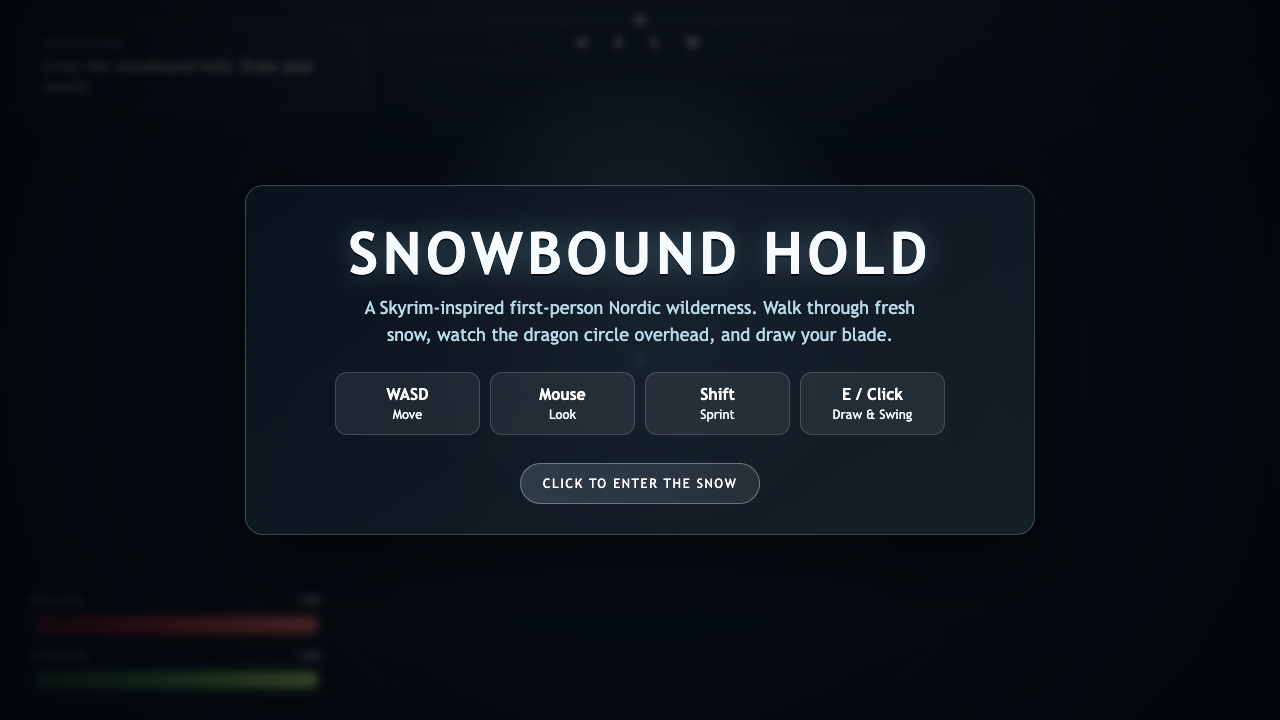
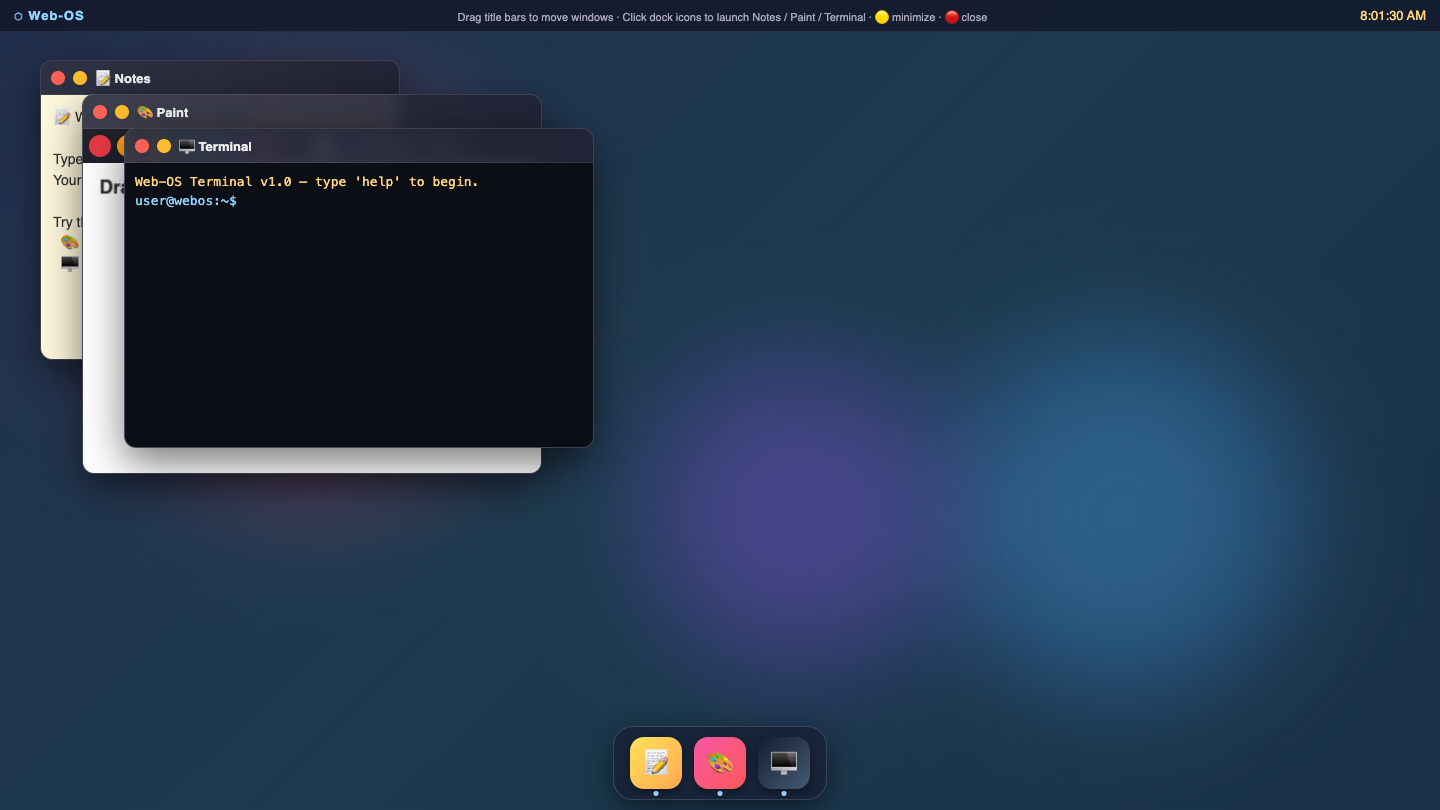
Webos
Page
Claude Fable 5 8.0
·
Fugu Mini 6.5
(+1.5)
What I saw: Renders cleanly with a polished menubar, blurred glass dock with hover labels and running-app dots, and all three apps (Notes, Paint, Terminal) launched and cascading correctly with working traffic-light controls. Strong and shippable, but lacks a maximize/restore and the visuals…
Where Fugu Mini beat Claude Fable 5
The tasks where I gave Fugu Mini a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
Wormhole
Sim
Fugu Mini 8.0
·
Claude Fable 5 6.5
(+1.5)
What I saw: 3D wormhole tunnel with distorted starfield. Smoke-test PASS.
Game
Game
Fugu Mini 9.0
·
Claude Fable 5 7.8
(+1.2)
· winner · biggest visual change
What I saw: Juicy browser game. Smoke-test PASS with 55% pixel diff — most reactive build in the sweep.
Terrain
Visual
Fugu Mini 8.5
·
Claude Fable 5 7.8
(+0.7)
What I saw: Mini gap-fill (round 2) — Tron procedural terrain. Smoke-test PASS (8.6% diff — strong motion).
Waves
Visual
Fugu Mini 8.5
·
Claude Fable 5 7.8
(+0.7)
What I saw: Gerstner ocean waves with sun reflection. Smoke-test PASS (9.6% pixel diff — strong wave motion).
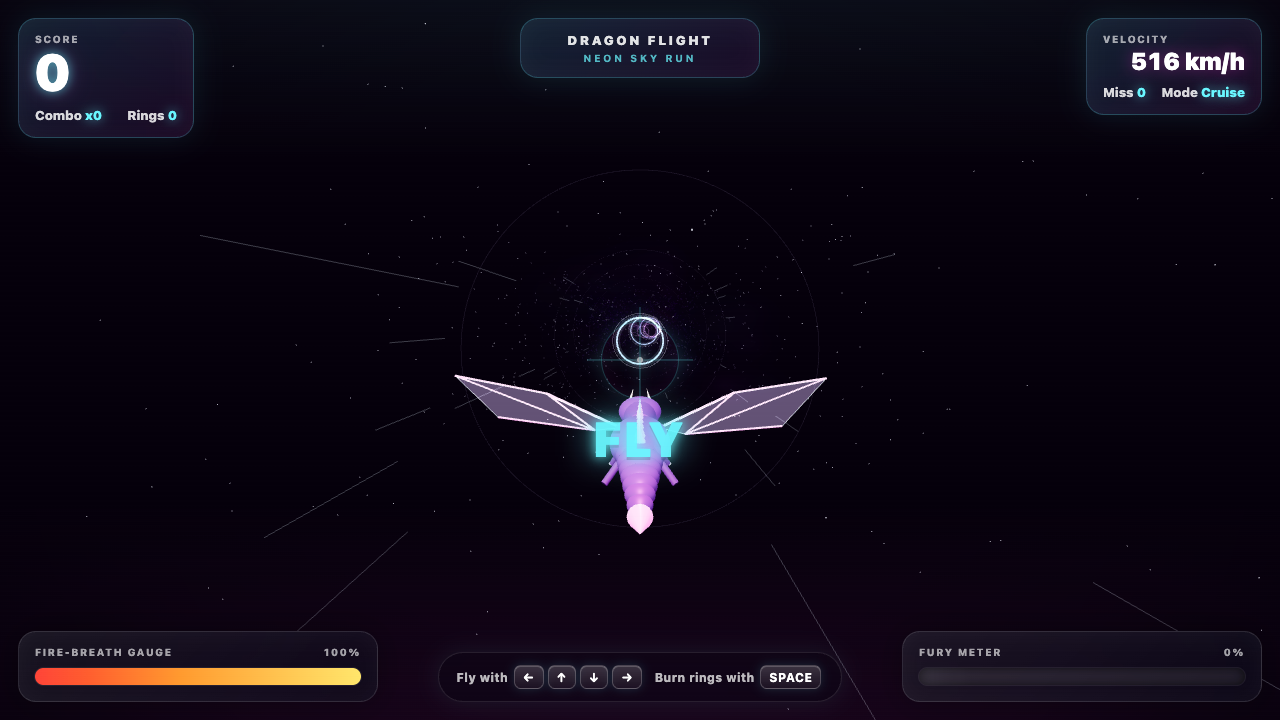
Dragonflight
Game
Fugu Mini 8.0
·
Claude Fable 5 7.4
(+0.6)
What I saw: Dragon flight through neon rings with HUD. Smoke-test PASS.
Strengths & weaknesses I logged
Claude Fable 5
Strengths
- Now the top SOLO model on this bench — 8.14 avg, #3 overall, edging Grok (8.13); only the Fusion (8.60) and Hermes MoA (8.38) ensembles rank higher
- 15 medals across 42 tasks (5 gold, 2 silver, 8 bronze) — shader/GPU physics is its superpower (Cornell-box path tracer 8.7, black-hole lensing 8.7, synthwave outrun 8.7)
- Its four core 3D games (crypt, skyrim, twilightvale, voxelcraft) rebuilt to showcase quality with the threejs-game-director skill — authored heroes, layered worlds, PBR materials, cohesive HUDs, all 8.8–9.0
- Beats Opus 4.8 head-to-head on the majority of tasks; tops external SWE-bench Verified at 95.0% in Julian's three-dragons writeup
Trade-offs
- Its hardest one-shots (crypt, twilightvale) black-screened on three.js r128 API drift — the scored builds are agentic rebuilds, not the raw first pass, and crypt's AAA rebuild needed a one-line emissive patch
- The showcase ceiling shown here needs the threejs-game-director scaffolding baked into the prompt — a bare one-shot lands lower (7.72 avg)
- Premium $10/$50 per-M pricing — you're paying for reasoning depth; cheaper models stay competitive on pure one-shot visuals
Fugu Mini
Strengths
- Zero panel orchestration — much lower latency than Ultra
- Same Sakana subscription, no extra cost
- Doesn't time out on heavy game/3D prompts where Ultra stalls
Trade-offs
- Single model only — no ensemble verdict
- Newer than Ultra — less calibration / verification
Pricing & context — the spec sheet
| Spec | Claude Fable 5 | Fugu Mini |
|---|---|---|
| Vendor | Anthropic | Sakana AI |
| Context window | 200,000 tokens (1M with extended thinking) | Single-model variant of Sakana's Fugu — no panel orchestration. Same API endpoint, much faster per call. |
| Price | $10 / $50 per M tokens | Same Sakana subscription pool as Fugu Ultra |
| Pricing detail | Released alongside Mythos 5 on June 9, 2026 as the publicly-available member of the new Mythos class. Premium per-token pricing on the Anthropic API; available everywhere Opus 4.8 ships. | The non-Ultra `fugu` model on Sakana's API. Sakana describes it as 'Fast mini model optimized for low latency yet high quality responses.' Crucially: zero orchestration tokens per call (vs Ultra's panel of thousands). Returns in ~3 min instead of 6-15 min and doesn't time out on heavy prompts. |
| Release | 2026-06-09 | 2026-06-15 |
| Bench coverage | 42/42 scored · avg 8.14/10 | 36/37 scored · avg 7.75/10 |
The verdict — which should you pick?
Across 36 scored shared tasks, Claude Fable 5 averaged 8.10/10, beating Fugu Mini's 7.75/10 by 0.35 points. Pick Claude Fable 5 when the build has to ship on the first prompt and you can afford the trade-offs in the comparison below.
If you only run one of these inside your stack, the head-to-head average above is the call. If you can run both, my honest play is to wire Claude Fable 5 and Fugu Mini both into the Agent Operating System and dispatch each from the kanban by task type — mission-critical one-shot builds where you want anthropic's newest reasoning → Claude Fable 5, agent loops where latency matters more than panel consensus → Fugu Mini. That's the same setup I run for the 3,600+ founders inside the AI Profit Boardroom.
FAQ — Claude Fable 5 vs Fugu Mini
Which is better, Claude Fable 5 or Fugu Mini?
On Goldie Bench, Claude Fable 5 averages 8.10/10 across the shared tasks, with 5 gold, 2 silver, 8 bronze overall. Fugu Mini averages 7.75/10, with 2 gold, 4 silver, 2 bronze. Claude Fable 5 wins the head-to-head 22–12.
How much does Claude Fable 5 cost vs Fugu Mini?
Claude Fable 5: Released alongside Mythos 5 on June 9, 2026 as the publicly-available member of the new Mythos class. Premium per-token pricing on the Anthropic API; available everywhere Opus 4.8 ships. Fugu Mini: The non-Ultra `fugu` model on Sakana's API. Sakana describes it as 'Fast mini model optimized for low latency yet high quality responses.' Crucially: zero orchestration tokens per call (vs Ultra's panel of thousands). Returns in ~3 min instead of 6-15 min and doesn't time out on heavy prompts.
What's the context window for Claude Fable 5 vs Fugu Mini?
Claude Fable 5 has a 200,000 tokens (1M with extended thinking) context window. Fugu Mini has a Single-model variant of Sakana's Fugu — no panel orchestration. Same API endpoint, much faster per call. context window.
When should I pick Claude Fable 5 over Fugu Mini?
Pick Claude Fable 5 for: Mission-critical one-shot builds where you want Anthropic's newest reasoning; Long-context work using extended thinking up to 1M tokens; Plan-heavy multi-step tasks where intelligence in the plan matters more than the build. The trade-off is the weaknesses we logged on the bench: Its hardest one-shots (crypt, twilightvale) black-screened on three.js r128 API drift — the scored builds are agentic rebuilds, not the raw first pass, and crypt's AAA rebuild needed a one-line emissive patch; The showcase ceiling shown here needs the threejs-game-director scaffolding baked into the prompt — a bare one-shot lands lower (7.72 avg); Premium $10/$50 per-M pricing — you're paying for reasoning depth; cheaper models stay competitive on pure one-shot visuals.
When should I pick Fugu Mini over Claude Fable 5?
Pick Fugu Mini for: Agent loops where latency matters more than panel consensus; Quick first-drafts you'll refine downstream; Filling out a bench when Ultra is timing out. The trade-off is the weaknesses we logged on the bench: Single model only — no ensemble verdict; Newer than Ultra — less calibration / verification.
How does Goldie Bench score Claude Fable 5 vs Fugu Mini?
Every demo on this page was built by Julian Goldie inside the Agent Operating System — same fixed prompt for both models, one shot, single HTML file out. Each result gets a 0–10 score on whether it ran, how close it hit the brief, and how good it looked. The highest score on each task gets gold; second gets silver; third gets bronze. See methodology for full provenance.
Related comparisons
Other head-to-heads using the same scoring system:
Claude Fable 5 vs Fusion Fugu Mini vs Fusion Claude Fable 5 vs Hermes MoA Fugu Mini vs Hermes MoA Claude Fable 5 vs Grok Fugu Mini vs Grok Claude Fable 5 vs MiniMax M3 Fugu Mini vs MiniMax M3Full model pages: Claude Fable 5 · Fugu Mini · back to the leaderboard
The same stack Julian uses
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.
3,600+founders
258documented wins
38countries
$59/momonthly