Real head-to-head · same prompt, one shot
Hermes MoA vs Qwen 3.7
A panel of frontier models, merged by a chair. The model doesn't matter — the system does. vs Multilingual open-weights — strong on Chinese reasoning.
Head-to-head verdict: Hermes MoA wins 42–0.
What I tested — same prompt, two models
I run the same fixed prompt set through every new model the day it drops — same string, one shot, single HTML file out — and I score the result 0–10 on whether it ran, how close it hit the brief, and how good it looked. Below is what came out when I gave the exact same prompts to Hermes MoA and Qwen 3.7, side by side, on 42 shared tasks inside the Agent Operating System.
Both models were given identical prompts inside the Agent Operating System — no help, no iteration, no "best of N" tricks. I run each prompt once, save the HTML file the model produces, and score it 0–10 on whether it ran, how close it hit the brief, and how good it looked. The scoring is mine. The verdicts below are pulled from my source comparison guides at agentos.guide where I publish every score and the reasoning behind it.
Hermes MoA · Run from the Mixture tab in the Hermes Agent OS. On this bench the panel built each demo and the aggregator merged the best of every draft.
Qwen 3.7 · Wired alongside GLM-5.2 in Agent OS for open-weights agent loops where you want vendor diversity.
Side-by-side on 42 shared tasks
Click any cell to play that model's actual one-shot attempt. Medals are derived from my 0–10 scores per task (highest = 🥇, second = 🥈, third = 🥉).
Task ↓
Hermes MoA
Qwen 3.7
Game
Game


Game

Game


Game


Game

Game


Game
Game


Game


Game

Game


Game


Game


Game


Game


Game


Game
Game
Page
Page
Sim


Sim

Sim
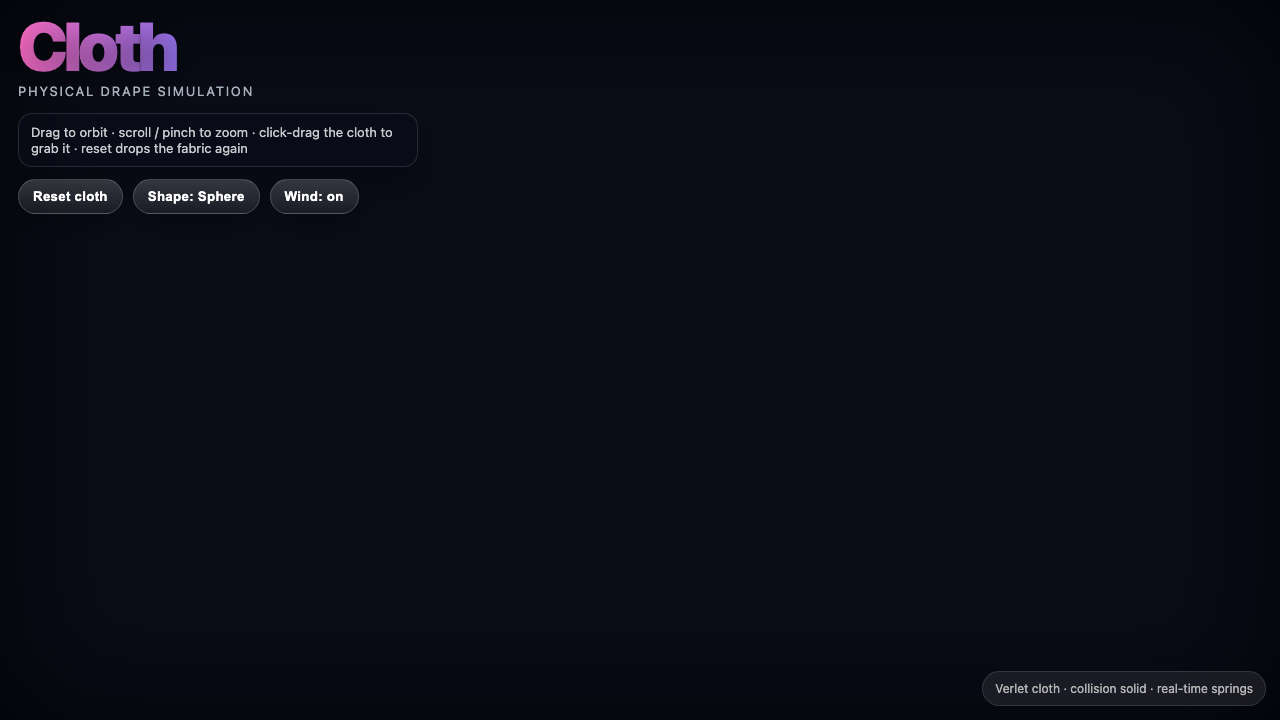

Where Hermes MoA beat Qwen 3.7
The tasks where I gave Hermes MoA a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
Raycaster
Game
Hermes MoA 8.4
·
Qwen 3.7 4.0
(+4.4)
What I saw: Polished neon raycaster with recursive-backtracker maze gen, DDA casting, distance fog + edge shading, animated exit beacon, regenerating mazes, full mobile touch joystick, and an auto-tour idle mode — more feature-complete than SOLO Opus 4.8 (8.0) and edges close to Fusion/Kimi …
Reactiondiff
Sim
Hermes MoA 8.6
·
Qwen 3.7 5.0
(+3.6)
What I saw: A polished, correct Gray-Scott implementation with ping-pong FBOs, drag-to-paint, 5 presets, feed/kill/speed/brush sliders, 4 palettes, and pause/reseed shortcuts — a noticeably richer feature set than SOLO Opus 4.8's bare 5KB version and edging past Fusion/MiniMax via the preset…
Lavalamp
Visual
Hermes MoA 8.4
·
Qwen 3.7 5.0
(+3.4)
What I saw: Polished, complete metaball lava lamp with a real lamp-shaped vessel (caps, rounded glass, vignette), interactive pointer-stir physics that displace blobs, and click-to-shift palette via cosine gradient — clearly more finished and interactive than Opus 4.8's bare 3KB shader and F…
Outrun
Game
Hermes MoA 8.4
·
Qwen 3.7 5.5
(+2.9)
What I saw: Polished pseudo-3D OutRun with curving/cresting road, layered synthwave horizon (sun with scanlines, parallax mountains, skyline, perspective grid), plus gem/traffic gameplay with collision, shake, flash, scoring, and mobile drag — more complete and arcade-rich than Fusion/Grok a…
Fractal
Sim
Hermes MoA 8.7
·
Qwen 3.7 6.0
(+2.7)
What I saw: Polished WebGL Mandelbrot+Julia explorer with drag-pan, wheel/pinch zoom, double-tap, autopilot flight to curated seahorse targets, orbit-trap filaments/rings, live coordinate readout, and iteration/palette controls — a more complete feature set than Fusion/Opus 4.8 and rivals Ki…
Strengths & weaknesses I logged
Hermes MoA
Strengths
- On GoldieBench, the MoA panel's galaxy edged solo Opus 4.8 — 8.6 vs 8.5 — with a denser 24k-particle spiral (the system beats the model)
- Two gold + one silver across its first three one-shot builds (galaxy, fireworks, arcade)
- Vendor-agnostic — swap any OpenRouter model into a panel or aggregator slot without touching the workflow
Trade-offs
- Latency is the panel's slowest draft plus the aggregator pass — ~110–140s per single-file build vs a solo model's one call
- Costs more per task than any single model (every panel slot + the aggregator are separate calls)
- Only 3 of 42 bench tasks run so far — a representative slice, not the full board
Qwen 3.7
Strengths
- Open weights, free for individuals — same model class as GLM-5.2
- Best-of-three on fluid simulation in the Goldie Bench bench
- Multilingual depth — Chinese reasoning especially strong
Trade-offs
- Only 5 tasks scored on the bench so far — small sample size
- Trails GLM-5.2 on cinematic visual builds at similar pricing
Pricing & context — the spec sheet
| Spec | Hermes MoA | Qwen 3.7 |
|---|---|---|
| Vendor | Hermes · Mixture of Agents | Alibaba |
| Context window | Varies — the sum of the panel models' contexts (Opus 4.8 + GPT-5.5) | 256,000 tokens |
| Price | Panel + aggregator calls (via OpenRouter) | Open weights · free for individuals |
| Pricing detail | Hermes Mixture of Agents dispatches one prompt to a configurable panel of frontier models in parallel, then a named aggregator reads every draft and writes one better final answer. Default panel: Claude Opus 4.8 + GPT-5.5, aggregated by Opus 4.8 — all via the OpenRouter key. Unlike a black-box ensemble, every slot is yours to swap from the Mixture tab in the Agent OS. | Alibaba's open-weights release — downloadable from Hugging Face, runnable locally or via Alibaba Cloud's free tier for individuals. |
| Release | 2026-06-28 | 2026-06 |
| Bench coverage | 42/42 scored · avg 8.38/10 | 42/42 scored · avg 6.93/10 |
The verdict — which should you pick?
Across 42 scored shared tasks, Hermes MoA averaged 8.38/10, beating Qwen 3.7's 6.93/10 by 1.45 points. Pick Hermes MoA when the build has to ship on the first prompt and you can afford the trade-offs in the comparison below.
If you only run one of these inside your stack, the head-to-head average above is the call. If you can run both, my honest play is to wire Hermes MoA and Qwen 3.7 both into the Agent Operating System and dispatch each from the kanban by task type — high-stakes single prompts where ensemble quality beats single-model speed → Hermes MoA, open-weights alternative to glm-5.2 when you want a different model family → Qwen 3.7. That's the same setup I run for the 3,600+ founders inside the AI Profit Boardroom.
FAQ — Hermes MoA vs Qwen 3.7
Which is better, Hermes MoA or Qwen 3.7?
On Goldie Bench, Hermes MoA averages 8.38/10 across the shared tasks, with 12 gold, 8 silver, 4 bronze overall. Qwen 3.7 averages 6.93/10, with 0 gold, 0 silver, 1 bronze. Hermes MoA wins the head-to-head 42–0.
How much does Hermes MoA cost vs Qwen 3.7?
Hermes MoA: Hermes Mixture of Agents dispatches one prompt to a configurable panel of frontier models in parallel, then a named aggregator reads every draft and writes one better final answer. Default panel: Claude Opus 4.8 + GPT-5.5, aggregated by Opus 4.8 — all via the OpenRouter key. Unlike a black-box ensemble, every slot is yours to swap from the Mixture tab in the Agent OS. Qwen 3.7: Alibaba's open-weights release — downloadable from Hugging Face, runnable locally or via Alibaba Cloud's free tier for individuals.
What's the context window for Hermes MoA vs Qwen 3.7?
Hermes MoA has a Varies — the sum of the panel models' contexts (Opus 4.8 + GPT-5.5) context window. Qwen 3.7 has a 256,000 tokens context window.
When should I pick Hermes MoA over Qwen 3.7?
Pick Hermes MoA for: High-stakes single prompts where ensemble quality beats single-model speed; Squeezing frontier-plus output from models you already have while Fable 5 / GPT-5.6 are still in preview; Production agents that want a configurable panel + vendor-redundancy on every call. The trade-off is the weaknesses we logged on the bench: Latency is the panel's slowest draft plus the aggregator pass — ~110–140s per single-file build vs a solo model's one call; Costs more per task than any single model (every panel slot + the aggregator are separate calls); Only 3 of 42 bench tasks run so far — a representative slice, not the full board.
When should I pick Qwen 3.7 over Hermes MoA?
Pick Qwen 3.7 for: Open-weights alternative to GLM-5.2 when you want a different model family; Multilingual workloads (Chinese, multi-script content); Fluid and particle simulations. The trade-off is the weaknesses we logged on the bench: Only 5 tasks scored on the bench so far — small sample size; Trails GLM-5.2 on cinematic visual builds at similar pricing.
How does Goldie Bench score Hermes MoA vs Qwen 3.7?
Every demo on this page was built by Julian Goldie inside the Agent Operating System — same fixed prompt for both models, one shot, single HTML file out. Each result gets a 0–10 score on whether it ran, how close it hit the brief, and how good it looked. The highest score on each task gets gold; second gets silver; third gets bronze. See methodology for full provenance.
Related comparisons
Other head-to-heads using the same scoring system:
Hermes MoA vs Fusion Qwen 3.7 vs Fusion Hermes MoA vs Grok Qwen 3.7 vs Grok Hermes MoA vs MiniMax M3 Qwen 3.7 vs MiniMax M3 Hermes MoA vs Fugu Ultra Qwen 3.7 vs Fugu UltraFull model pages: Hermes MoA · Qwen 3.7 · back to the leaderboard
The same stack Julian uses
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.
3,600+founders
258documented wins
38countries
$59/momonthly