
Real head-to-head · same prompt, one shot
Hermes MoA vs LongCat-2.0
A panel of frontier models, merged by a chair. The model doesn't matter — the system does. vs The open 1.6T MoE that builds — a frontier coder trained on non-Nvidia ASIC superpods.
Head-to-head verdict: LongCat-2.0 wins 3–1.
What I tested — same prompt, two models
I run the same fixed prompt set through every new model the day it drops — same string, one shot, single HTML file out — and I score the result 0–10 on whether it ran, how close it hit the brief, and how good it looked. Below is what came out when I gave the exact same prompts to Hermes MoA and LongCat-2.0, side by side, on 4 shared tasks inside the Agent Operating System.
Both models were given identical prompts inside the Agent Operating System — no help, no iteration, no "best of N" tricks. I run each prompt once, save the HTML file the model produces, and score it 0–10 on whether it ran, how close it hit the brief, and how good it looked. The scoring is mine. The verdicts below are pulled from my source comparison guides at agentos.guide where I publish every score and the reasoning behind it.
Hermes MoA · Run from the Mixture tab in the Hermes Agent OS. On this bench the panel built each demo and the aggregator merged the best of every draft.
LongCat-2.0 · Run through the free longcat.chat web chat (the API key had no token quota), driven with the local-model-tester GoldieBench prompts; every build render-verified + playtested (verify-move.js: walks + looks + zero errors) before scoring. Slots into the Agent OS as an open frontier coder via its OpenAI-compatible API or the Claude Code / OpenClaw / Hermes harnesses.
Side-by-side on 42 shared tasks
Click any cell to play that model's actual one-shot attempt. Medals are derived from my 0–10 scores per task (highest = 🥇, second = 🥈, third = 🥉).
Task ↓
Hermes MoA
LongCat-2.0
Game
Game


Game

Game
Game
— not attempted —
Game

— not attempted —
Game

— not attempted —
Game

— not attempted —
Game

— not attempted —
Game
— not attempted —
Game

— not attempted —
Game

— not attempted —
Game
— not attempted —
Game

— not attempted —
Game

— not attempted —
Game

— not attempted —
Game

— not attempted —
Game

— not attempted —
Game
— not attempted —
Page
— not attempted —
Page
— not attempted —
Sim

— not attempted —
Sim
— not attempted —
Sim
— not attempted —
Where Hermes MoA beat LongCat-2.0
The tasks where I gave Hermes MoA a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
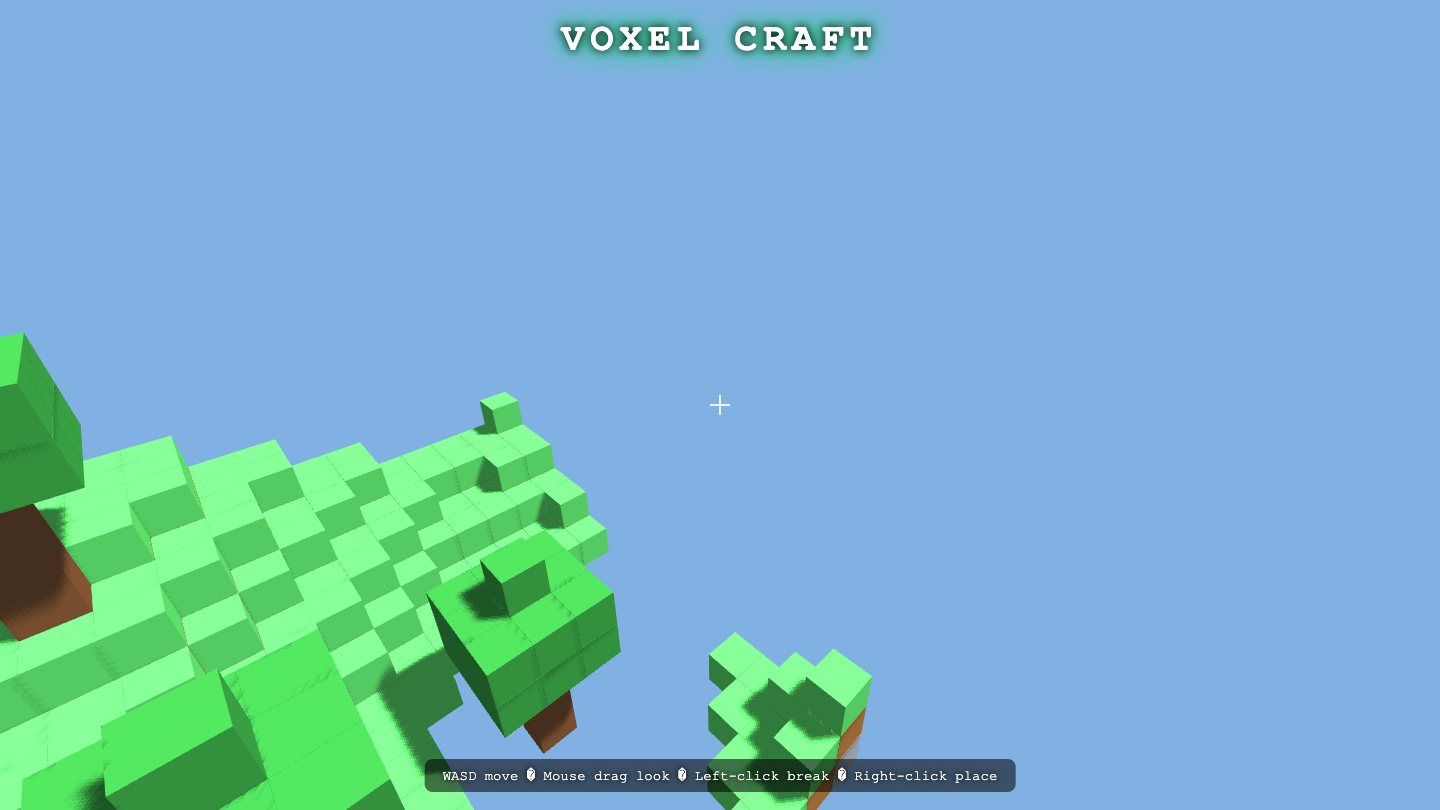
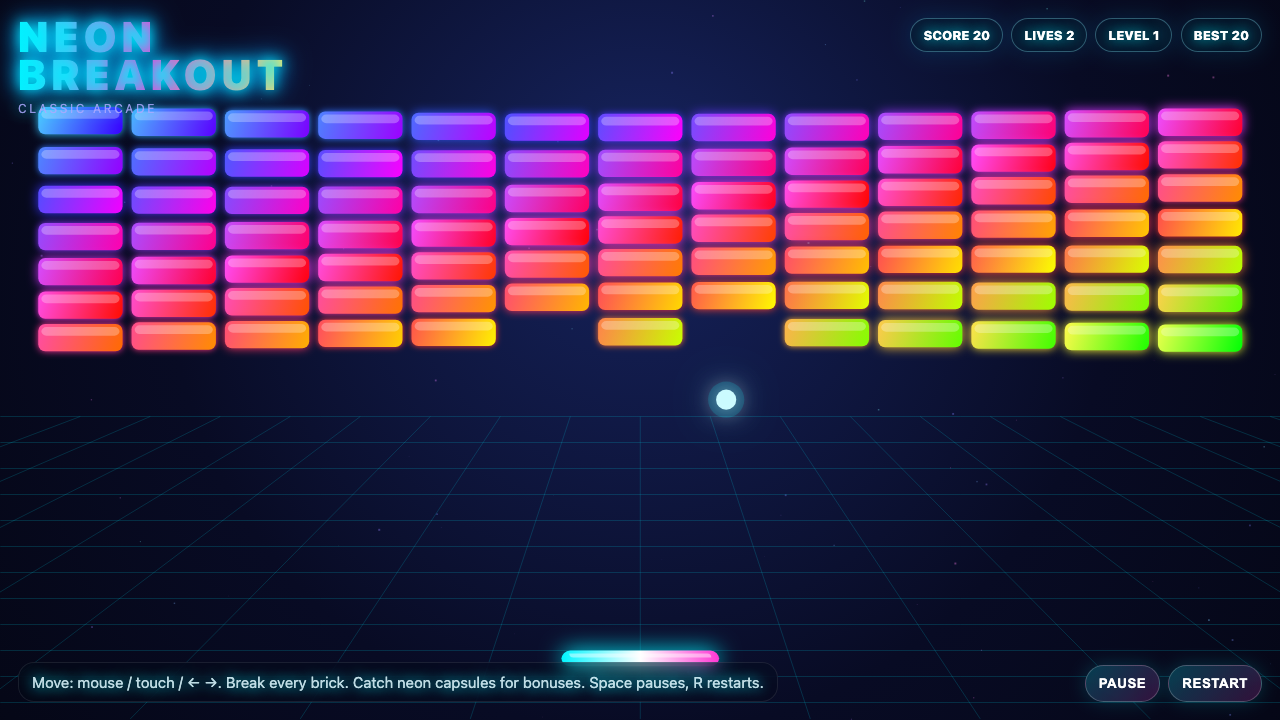
Voxelcraft
Game
Hermes MoA 8.4
·
LongCat-2.0 7.5
(+0.9)
What I saw: Strong, polished voxel sandbox with procedural textures, day/night cycle with sun/moon/stars, trees, water, and solid mobile touch controls — clearly beats SOLO Opus 4.8 (8.0) and edges near Fusion (9.0), but the collision section is truncated in the source so I can't fully verif…
Where LongCat-2.0 beat Hermes MoA
The tasks where I gave LongCat-2.0 a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
Dragonrealm
Game
LongCat-2.0 8.5
·
Hermes MoA 7.8
(+0.7)
What I saw: One-shot 15KB three.js snow open-world — snow-capped mountains + 30 low-poly pines, 3000-particle falling snow, first-person glowing sword, fog. Real WASD+mouse+sprint controls, terrain-follow. verify-move: walks+looks, canvas 1440x810, 0 errors. Flawless first try — no patch.
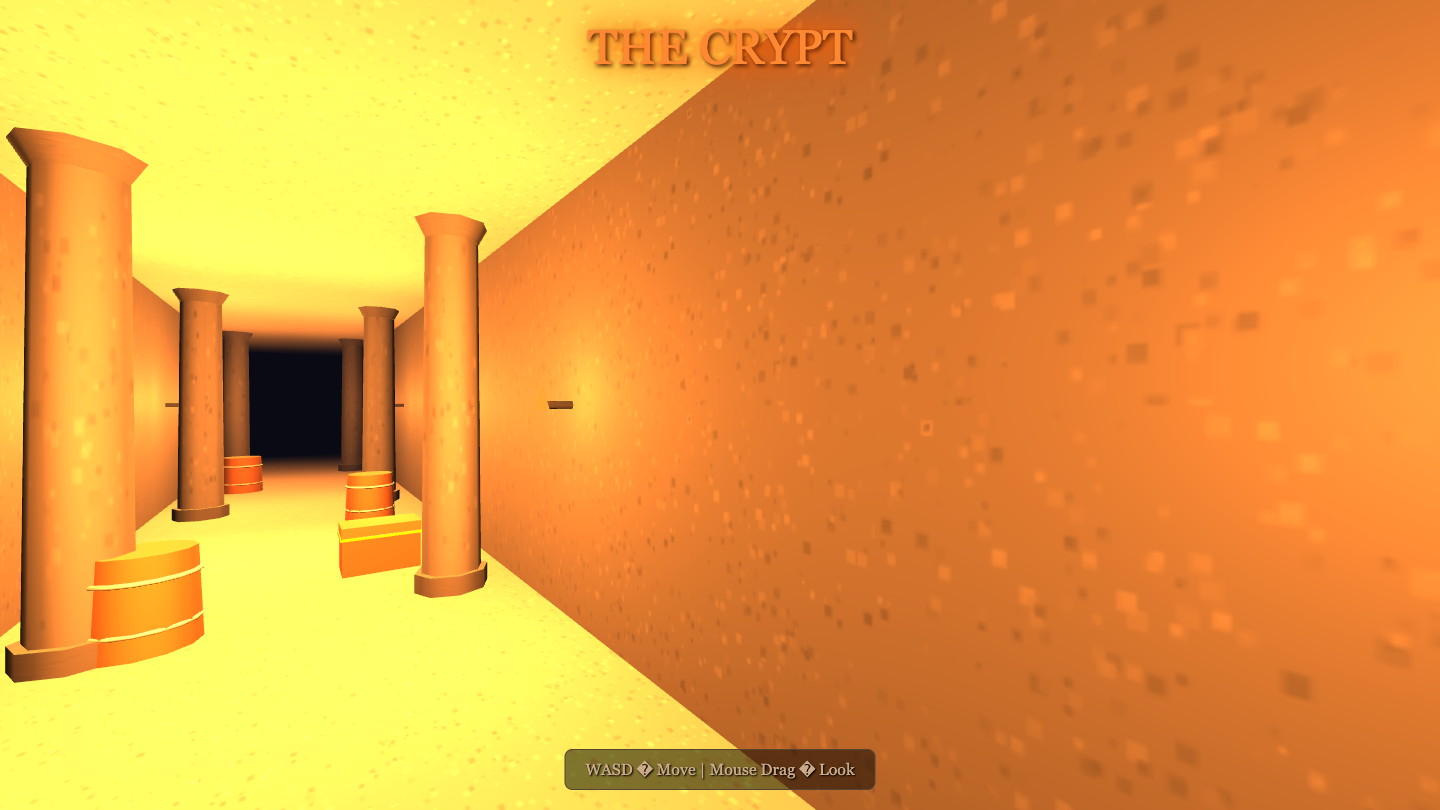
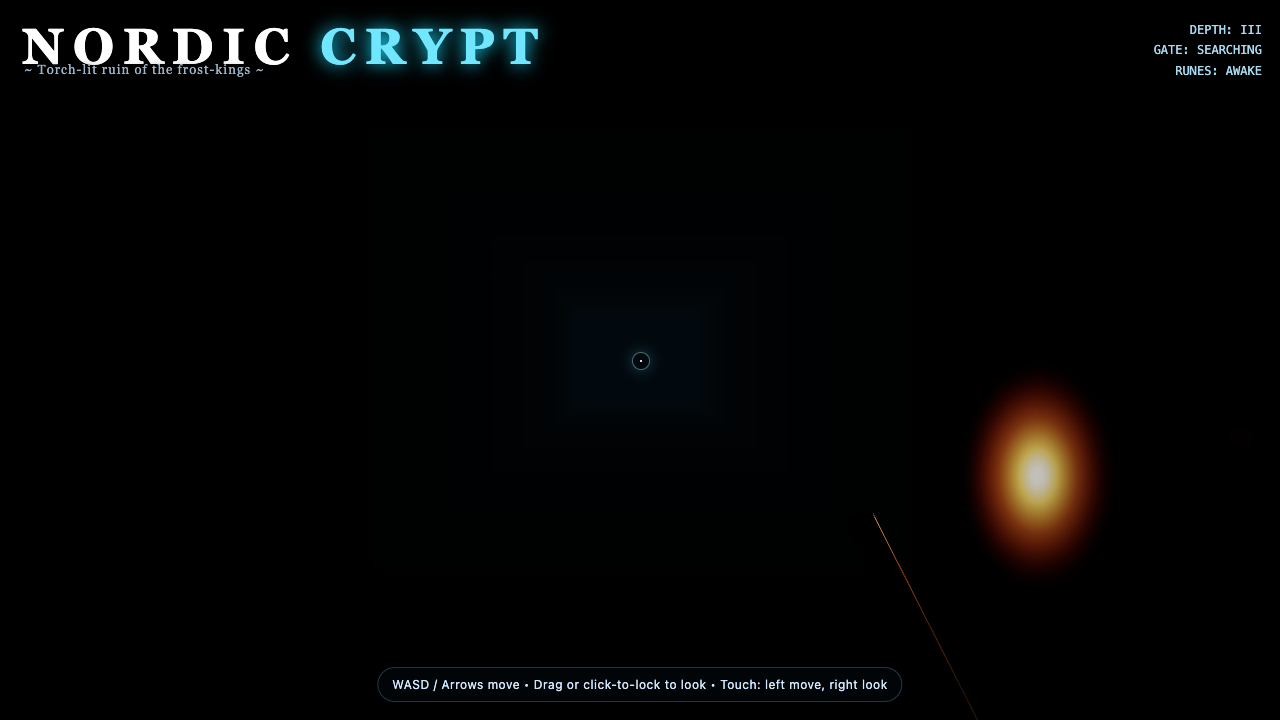
Crypt
Game
LongCat-2.0 8.0
·
Hermes MoA 7.8
(+0.2)
What I saw: One-shot 9KB torch-lit stone dungeon corridor — pillars, barrels, a chest, 6+ flickering torch PointLights, fog. Real WASD+mouse controls. verify-move: walks+looks, 0 errors. Lit + atmospheric (a touch over-bright orange).
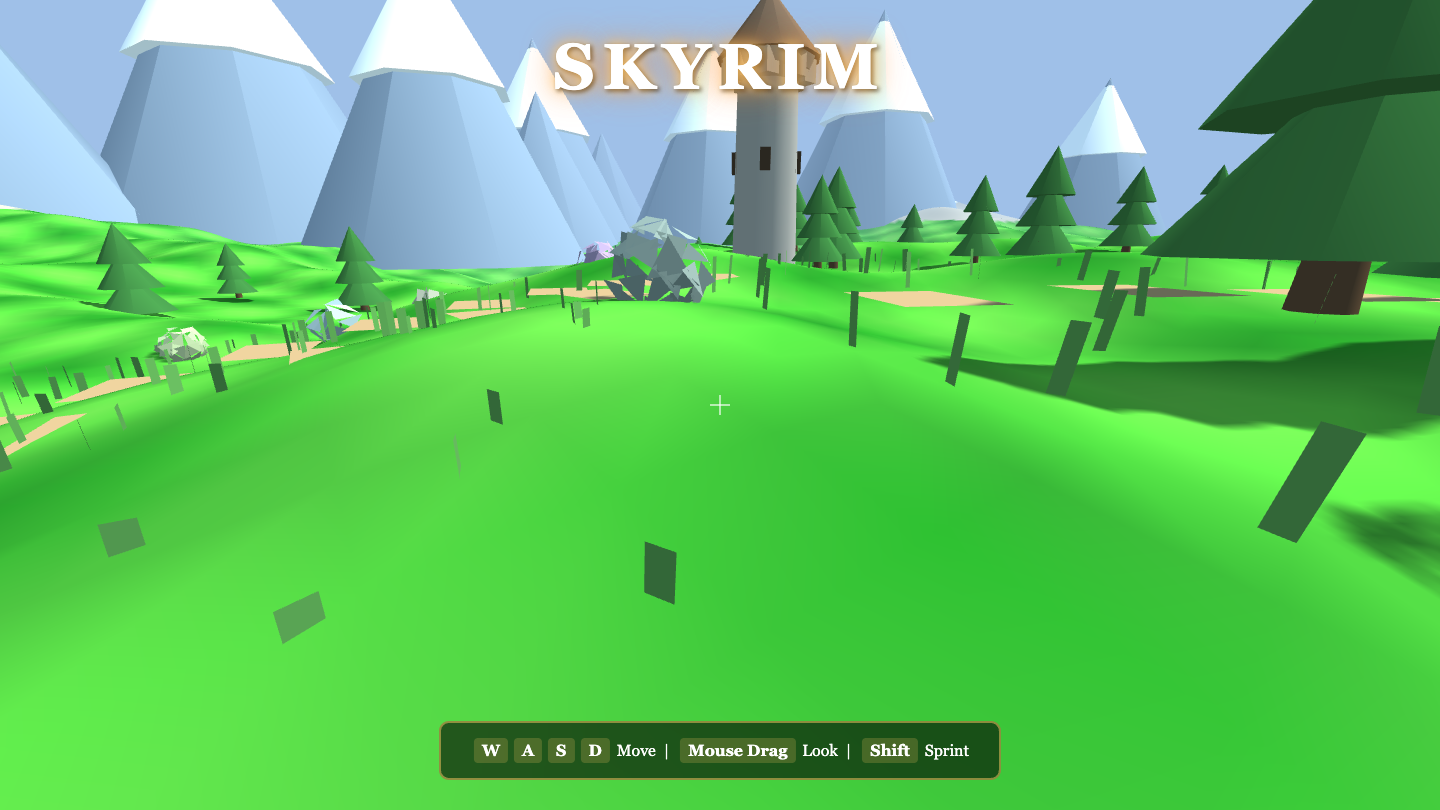
Skyrim
Game
LongCat-2.0 8.5
·
Hermes MoA 8.4
(+0.1)
What I saw: One-shot 23KB open-world explorer (the richest of the four) — rolling displaced terrain, snow mountains, a stone watchtower, 20+ conifers, boulders, grass, clouds, and terrain-height following. Real WASD+mouse. verify-move: walks+looks, 0 errors.
Strengths & weaknesses I logged
Hermes MoA
Strengths
- On GoldieBench, the MoA panel's galaxy edged solo Opus 4.8 — 8.6 vs 8.5 — with a denser 24k-particle spiral (the system beats the model)
- Two gold + one silver across its first three one-shot builds (galaxy, fireworks, arcade)
- Vendor-agnostic — swap any OpenRouter model into a panel or aggregator slot without touching the workflow
Trade-offs
- Latency is the panel's slowest draft plus the aggregator pass — ~110–140s per single-file build vs a solo model's one call
- Costs more per task than any single model (every panel slot + the aggregator are separate calls)
- Only 3 of 42 bench tasks run so far — a representative slice, not the full board
LongCat-2.0
Strengths
- One-shot GoldieBench: 3 of 4 flawless playable 3D builds (Dragon Realm 8.5, Skyrim 8.5, Crypt 8.0); Voxel Craft built one-shot but needed a 1-line camera fix (7.5) — avg 8.1
- 1.6T-param MoE (~48B active/token) with LongCat Sparse Attention + a 1M-token window — built for long-horizon agentic + coding tasks
- Open weights, deeply integrated with Claude Code, OpenClaw and Hermes — a free frontier-class coder to slot into the Agent OS
Trade-offs
- The direct API key we were given had near-zero token quota, so we ran it through the free web chat rather than the API
- One camera-framing miss: Voxel Craft loaded facing away from the world (sky-only) until a one-line yaw/pitch patch pointed it at the terrain
Pricing & context — the spec sheet
| Spec | Hermes MoA | LongCat-2.0 |
|---|---|---|
| Vendor | Hermes · Mixture of Agents | Meituan |
| Context window | Varies — the sum of the panel models' contexts (Opus 4.8 + GPT-5.5) | 1,000,000 tokens (LongCat Sparse Attention) |
| Price | Panel + aggregator calls (via OpenRouter) | Open weights · free web chat · API |
| Pricing detail | Hermes Mixture of Agents dispatches one prompt to a configurable panel of frontier models in parallel, then a named aggregator reads every draft and writes one better final answer. Default panel: Claude Opus 4.8 + GPT-5.5, aggregated by Opus 4.8 — all via the OpenRouter key. Unlike a black-box ensemble, every slot is yours to swap from the Mixture tab in the Agent OS. | LongCat-2.0 is open-sourced (weights on Hugging Face + GitHub) and served via the longcat.chat web chat plus an OpenAI-compatible API (model id 'LongCat-2.0' at api.longcat.chat/openai/v1). It's a 1.6T-parameter MoE with ~48B activated per token, trained entirely on AI ASIC superpods (>50K accelerators, 35T+ tokens, no rollbacks). Note: the direct API key we were handed shipped with zero token quota ('Token 额度不足'), so every build here was run through the free web chat. Vendor: Meituan. |
| Release | 2026-06-28 | 2026-06 |
| Bench coverage | 42/42 scored · avg 8.38/10 | 4/4 scored · avg 8.12/10 |
The verdict — which should you pick?
Across 4 scored shared tasks, the averages are essentially tied — Hermes MoA 8.10 vs LongCat-2.0 8.12. This isn't the comparison where one wins; it's the comparison where you pick based on context, pricing, and what you're actually trying to ship.
If you only run one of these inside your stack, the head-to-head average above is the call. If you can run both, my honest play is to wire Hermes MoA and LongCat-2.0 both into the Agent Operating System and dispatch each from the kanban by task type — high-stakes single prompts where ensemble quality beats single-model speed → Hermes MoA, one-shot single-file 3d / html / game builds inside the agent os → LongCat-2.0. That's the same setup I run for the 3,600+ founders inside the AI Profit Boardroom.
FAQ — Hermes MoA vs LongCat-2.0
Which is better, Hermes MoA or LongCat-2.0?
On Goldie Bench, Hermes MoA averages 8.10/10 across the shared tasks, with 12 gold, 7 silver, 4 bronze overall. LongCat-2.0 averages 8.12/10, with 0 gold, 1 silver, 2 bronze. LongCat-2.0 wins the head-to-head 3–1.
How much does Hermes MoA cost vs LongCat-2.0?
Hermes MoA: Hermes Mixture of Agents dispatches one prompt to a configurable panel of frontier models in parallel, then a named aggregator reads every draft and writes one better final answer. Default panel: Claude Opus 4.8 + GPT-5.5, aggregated by Opus 4.8 — all via the OpenRouter key. Unlike a black-box ensemble, every slot is yours to swap from the Mixture tab in the Agent OS. LongCat-2.0: LongCat-2.0 is open-sourced (weights on Hugging Face + GitHub) and served via the longcat.chat web chat plus an OpenAI-compatible API (model id 'LongCat-2.0' at api.longcat.chat/openai/v1). It's a 1.6T-parameter MoE with ~48B activated per token, trained entirely on AI ASIC superpods (>50K accelerators, 35T+ tokens, no rollbacks). Note: the direct API key we were handed shipped with zero token quota ('Token 额度不足'), so every build here was run through the free web chat. Vendor: Meituan.
What's the context window for Hermes MoA vs LongCat-2.0?
Hermes MoA has a Varies — the sum of the panel models' contexts (Opus 4.8 + GPT-5.5) context window. LongCat-2.0 has a 1,000,000 tokens (LongCat Sparse Attention) context window.
When should I pick Hermes MoA over LongCat-2.0?
Pick Hermes MoA for: High-stakes single prompts where ensemble quality beats single-model speed; Squeezing frontier-plus output from models you already have while Fable 5 / GPT-5.6 are still in preview; Production agents that want a configurable panel + vendor-redundancy on every call. The trade-off is the weaknesses we logged on the bench: Latency is the panel's slowest draft plus the aggregator pass — ~110–140s per single-file build vs a solo model's one call; Costs more per task than any single model (every panel slot + the aggregator are separate calls); Only 3 of 42 bench tasks run so far — a representative slice, not the full board.
When should I pick LongCat-2.0 over Hermes MoA?
Pick LongCat-2.0 for: One-shot single-file 3D / HTML / game builds inside the Agent OS; Long-context, repo-level edits + automated agentic task execution; A free, open, frontier-class coder to drop into the Model-Proof System. The trade-off is the weaknesses we logged on the bench: The direct API key we were given had near-zero token quota, so we ran it through the free web chat rather than the API; One camera-framing miss: Voxel Craft loaded facing away from the world (sky-only) until a one-line yaw/pitch patch pointed it at the terrain.
How does Goldie Bench score Hermes MoA vs LongCat-2.0?
Every demo on this page was built by Julian Goldie inside the Agent Operating System — same fixed prompt for both models, one shot, single HTML file out. Each result gets a 0–10 score on whether it ran, how close it hit the brief, and how good it looked. The highest score on each task gets gold; second gets silver; third gets bronze. See methodology for full provenance.
Related comparisons
Other head-to-heads using the same scoring system:
Hermes MoA vs Fusion LongCat-2.0 vs Fusion Hermes MoA vs Grok LongCat-2.0 vs Grok Hermes MoA vs MiniMax M3 LongCat-2.0 vs MiniMax M3 Hermes MoA vs Fugu Ultra LongCat-2.0 vs Fugu UltraFull model pages: Hermes MoA · LongCat-2.0 · back to the leaderboard
The same stack Julian uses
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.
3,600+founders
258documented wins
38countries
$59/momonthly