
Real head-to-head · same prompt, one shot
Fusion vs MiniMax M3
Multi-model panel — Fable 5 + GPT-5.5, ensembled. Beats Fable 5 at half the price. vs 1M-context frontier model at $0.30/M tokens — cheapest big-context model on the bench.
Head-to-head verdict: Fusion wins 26–8 with 8 ties.
What I tested — same prompt, two models
I run the same fixed prompt set through every new model the day it drops — same string, one shot, single HTML file out — and I score the result 0–10 on whether it ran, how close it hit the brief, and how good it looked. Below is what came out when I gave the exact same prompts to Fusion and MiniMax M3, side by side, on 42 shared tasks inside the Agent Operating System.
Both models were given identical prompts inside the Agent Operating System — no help, no iteration, no "best of N" tricks. I run each prompt once, save the HTML file the model produces, and score it 0–10 on whether it ran, how close it hit the brief, and how good it looked. The scoring is mine. The verdicts below are pulled from my source comparison guides at agentos.guide where I publish every score and the reasoning behind it.
Fusion · Dispatched from Agent OS for research-heavy prompts where ensemble accuracy outweighs single-model speed.
MiniMax M3 · Bench prompts dispatched via OpenRouter. Scored by Claude judge against the same 42 prompts every other model ran.
Side-by-side on 42 shared tasks
Click any cell to play that model's actual one-shot attempt. Medals are derived from my 0–10 scores per task (highest = 🥇, second = 🥈, third = 🥉).
Task ↓
Fusion
MiniMax M3
Game

Game

Game


Game

Game

Game


Game


Game

Game


Game


Game

Game


Game

Game

Game
Game
Game

Game


Game
Page
Page
Sim


Sim


Sim

Where Fusion beat MiniMax M3
The tasks where I gave Fusion a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
Plasma
Visual
Fusion 8.5
·
MiniMax M3 6.0
(+2.5)
What I saw: Hypnotic full-screen plasma effect with 5 palettes, click anywhere to create a ripple. Smooth slow motion. 13KB but the brief is fully met.
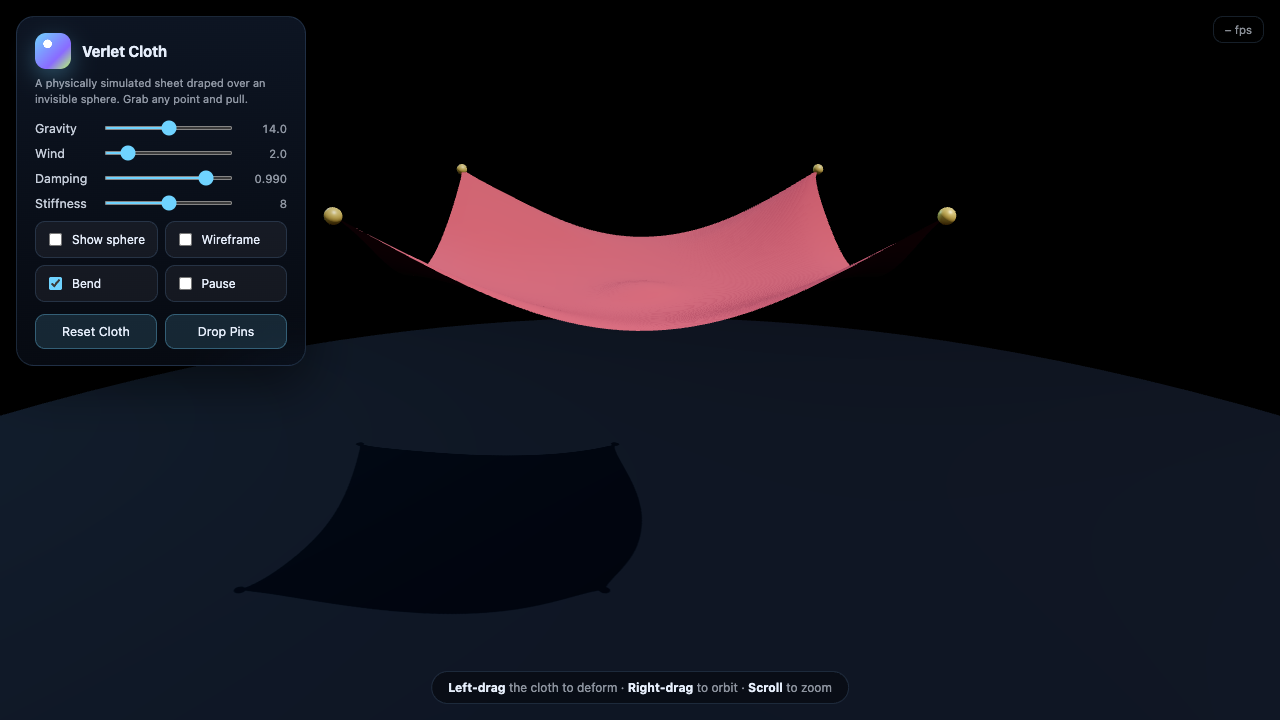
Blackhole
Sim
Fusion 9.0
·
MiniMax M3 7.0
(+2.0)
· winner · physically motivated
What I saw: Photon back-tracing through a curved-space metric (claims as much in the code) for actual gravitational lensing — disk's far side lifted over and under the shadow. Loading screen says "computing space-time metric…" Range-slider parameter panel for spin/disk tilt/exposure. Most am…
Fireworks
Visual
Fusion 9.0
·
MiniMax M3 7.5
(+1.5)
· winner · with audio
What I saw: Click to launch fireworks — particle trails, sparkle physics, AND a synthesized whoosh + boom via Web Audio. Most polished fireworks of any model.
Solar
Sim
Fusion 9.0
·
MiniMax M3 7.5
(+1.5)
· polish · interactive UI
What I saw: Most polished solar attempt I've graded — glass-morphism control panel with time slider, sun-glow slider, orbits/labels/pause toggles, hover info cards on every planet, Saturn's rings, accurate moons. Drag-to-orbit + scroll-to-zoom. Beats Opus on UI density without losing the physics.
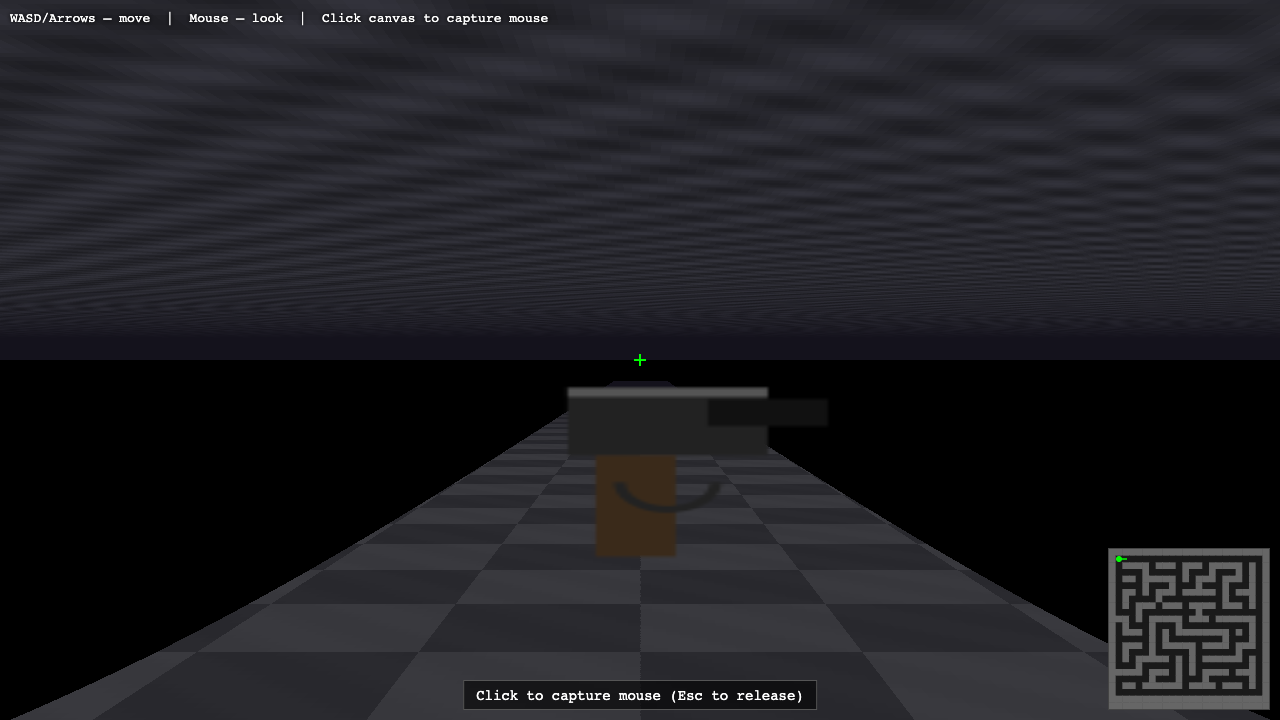
Raycaster
Game
Fusion 8.5
·
MiniMax M3 7.0
(+1.5)
What I saw: Pure canvas-2D raycaster with pointer-lock mouse look, WASD movement, shift-to-run, M-map toggle. Internal render resolution scales by aspect for speed. Polished HUD with kbd-styled key hints, FPS counter, click-to-capture overlay. Strong technical implementation.
Where MiniMax M3 beat Fusion
The tasks where I gave MiniMax M3 a higher 0–10 score on the same prompt — with the actual commentary from my source guides.
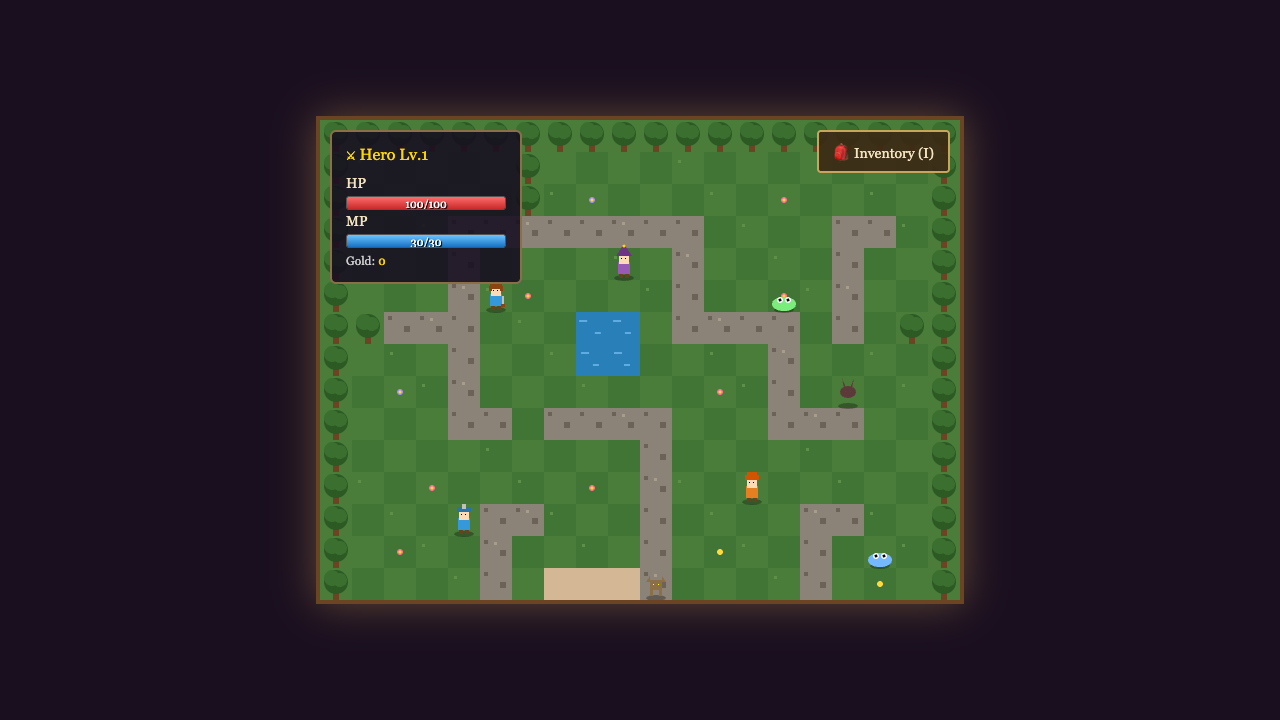
Twilightvale
Game
MiniMax M3 9.0
·
Fusion 4.0
(+5.0)
· winner · biggest open world
What I saw: 47KB — densest open-world. Village, NPCs, combat, day/night, weather, inventory.
Dogfight
Game
MiniMax M3 8.5
·
Fusion 4.0
(+4.5)
What I saw: 25KB 3D dogfight with enemy AI, missiles, guns.
Neonblaster
Game
MiniMax M3 8.5
·
Fusion 4.0
(+4.5)
What I saw: 30KB neon space shooter — waves, bosses, power-ups, screen-shake.
Nordiccrypt
Game
MiniMax M3 9.0
·
Fusion 6.5
(+2.5)
What I saw: 41KB Nordic crypt with torch-lit corridors, chasing skeletons, boss room.
Dragonflight
Game
MiniMax M3 8.5
·
Fusion 6.5
(+2.0)
What I saw: Fly a dragon through neon rings — full HUD, score, fire-breath gauge.
Strengths & weaknesses I logged
Fusion
Strengths
- Premium Fusion panel scored 69.0% on DRACO deep-research benchmark — beats solo Fable 5 by +3.7 points
- Budget panel ties Fable 5 at ~64.7% for roughly half the cost
- Vendor-agnostic — model panel can swap as new frontier releases land
Trade-offs
- Ensemble latency higher than any single model (panel calls run in parallel but the slowest still gates the response)
- No per-task goldiebench scoring yet — bench rank pending
MiniMax M3
Strengths
- 1M token context — full repo / full deep-research corpus fits in one call
- $0.30/M input is roughly 1/30th of Opus 4.8 — built for high-volume agent loops
- Solid one-shot HTML output — clean structure on game and visual prompts
Trade-offs
- Less polished than Fusion's panel-ensembled output on the toughest deep builds
- Newer model — less community calibration vs Fable 5 / Opus 4.8
Pricing & context — the spec sheet
| Spec | Fusion | MiniMax M3 |
|---|---|---|
| Vendor | OpenRouter | MiniMax |
| Context window | Varies — depends on which panel models are dispatched | 1,048,576-token context — matches GLM-5.2 and Fable 5 |
| Price | OpenRouter Fusion API pricing | $0.30 / 1M input tokens, $1.50 / 1M output |
| Pricing detail | OpenRouter's Fusion API dispatches a single prompt to multiple frontier models and ensembles the answers. Premium panel: Fable 5 + GPT-5.5. Budget panel: cheaper open-weights models. Roughly half the per-token cost of a Fable 5 solo call. | MiniMax M3 is the cheapest 1M-context frontier model on the bench — roughly 1/200th the per-call cost of OpenRouter Fusion and 1/30th of Claude Opus 4.8. Designed for high-volume agent workloads where context length matters but per-call budget is tight. |
| Release | 2026-06-14 | 2026-06-18 |
| Bench coverage | 42/42 scored · avg 8.00/10 | 42/42 scored · avg 7.96/10 |
The verdict — which should you pick?
Across 42 scored shared tasks, the averages are essentially tied — Fusion 8.00 vs MiniMax M3 7.96. This isn't the comparison where one wins; it's the comparison where you pick based on context, pricing, and what you're actually trying to ship.
If you only run one of these inside your stack, the head-to-head average above is the call. If you can run both, my honest play is to wire Fusion and MiniMax M3 both into the Agent Operating System and dispatch each from the kanban by task type — deep-research workflows where panel consensus beats single-model answers → Fusion, high-volume agent workflows where per-call cost dominates → MiniMax M3. That's the same setup I run for the 3,600+ founders inside the AI Profit Boardroom.
FAQ — Fusion vs MiniMax M3
Which is better, Fusion or MiniMax M3?
On Goldie Bench, Fusion averages 8.00/10 across the shared tasks, with 27 gold, 8 silver, 4 bronze overall. MiniMax M3 averages 7.96/10, with 12 gold, 11 silver, 8 bronze. Fusion wins the head-to-head 26–8.
How much does Fusion cost vs MiniMax M3?
Fusion: OpenRouter's Fusion API dispatches a single prompt to multiple frontier models and ensembles the answers. Premium panel: Fable 5 + GPT-5.5. Budget panel: cheaper open-weights models. Roughly half the per-token cost of a Fable 5 solo call. MiniMax M3: MiniMax M3 is the cheapest 1M-context frontier model on the bench — roughly 1/200th the per-call cost of OpenRouter Fusion and 1/30th of Claude Opus 4.8. Designed for high-volume agent workloads where context length matters but per-call budget is tight.
What's the context window for Fusion vs MiniMax M3?
Fusion has a Varies — depends on which panel models are dispatched context window. MiniMax M3 has a 1,048,576-token context — matches GLM-5.2 and Fable 5 context window.
When should I pick Fusion over MiniMax M3?
Pick Fusion for: Deep-research workflows where panel consensus beats single-model answers; Cost-sensitive operators who want Fable-5-class output at ~half the bill; Production agents that benefit from vendor-redundancy on every call. The trade-off is the weaknesses we logged on the bench: Ensemble latency higher than any single model (panel calls run in parallel but the slowest still gates the response); No per-task goldiebench scoring yet — bench rank pending.
When should I pick MiniMax M3 over Fusion?
Pick MiniMax M3 for: High-volume agent workflows where per-call cost dominates; 1M-context tasks (whole-repo refactors, deep-research synthesis); Drop-in cheaper alternative to GLM-5.2 with comparable 1M context. The trade-off is the weaknesses we logged on the bench: Less polished than Fusion's panel-ensembled output on the toughest deep builds; Newer model — less community calibration vs Fable 5 / Opus 4.8.
How does Goldie Bench score Fusion vs MiniMax M3?
Every demo on this page was built by Julian Goldie inside the Agent Operating System — same fixed prompt for both models, one shot, single HTML file out. Each result gets a 0–10 score on whether it ran, how close it hit the brief, and how good it looked. The highest score on each task gets gold; second gets silver; third gets bronze. See methodology for full provenance.
Related comparisons
Other head-to-heads using the same scoring system:
Fusion vs Opus 4.8 MiniMax M3 vs Opus 4.8 Fusion vs GLM-5.2 MiniMax M3 vs GLM-5.2 Fusion vs Grok MiniMax M3 vs Grok Fusion vs Fugu Ultra MiniMax M3 vs Fugu UltraFull model pages: Fusion · MiniMax M3 · back to the leaderboard
The same stack Julian uses
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.
3,600+founders
258documented wins
38countries
$100k+/mocommunity MRR