
Real head-to-head · same prompt, one shot
Claude Fable 5 vs Kimi K2.7 · Quality
The newest Anthropic model — first Mythos-class made generally available. vs Quality mode — deepest thinking, best output.
What I tested — same prompt, two models
I run the same fixed prompt set through every new model the day it drops — same string, one shot, single HTML file out — and I score the result 0–10 on whether it ran, how close it hit the brief, and how good it looked. Below is what came out when I gave the exact same prompts to Claude Fable 5 and Kimi K2.7 · Quality, side by side, on 42 shared tasks inside the Agent Operating System.
Both models were given identical prompts inside the Agent Operating System — no help, no iteration, no "best of N" tricks. I run each prompt once, save the HTML file the model produces, and score it 0–10 on whether it ran, how close it hit the brief, and how good it looked. The scoring is mine. The verdicts below are pulled from my source comparison guides at agentos.guide where I publish every score and the reasoning behind it.
Claude Fable 5 · Selected from Agent OS for the highest-stakes one-shot work — it replaced Opus 4.8 as the safety net on hard prompts, and the full 42-task bench run now backs that call.
Kimi K2.7 · Quality · Reserved for one-shot builds where the output is the deliverable — polish over speed.
Side-by-side on 42 shared tasks
Click any cell to play that model's actual one-shot attempt. Medals are derived from my 0–10 scores per task (highest = 🥇, second = 🥈, third = 🥉).
Task ↓
Claude Fable 5
Kimi K2.7 · Quality
Game

Game

Game

Game

Game

Game


Game


Game


Game


Game


Game

Game


Game
Game

Game


Game
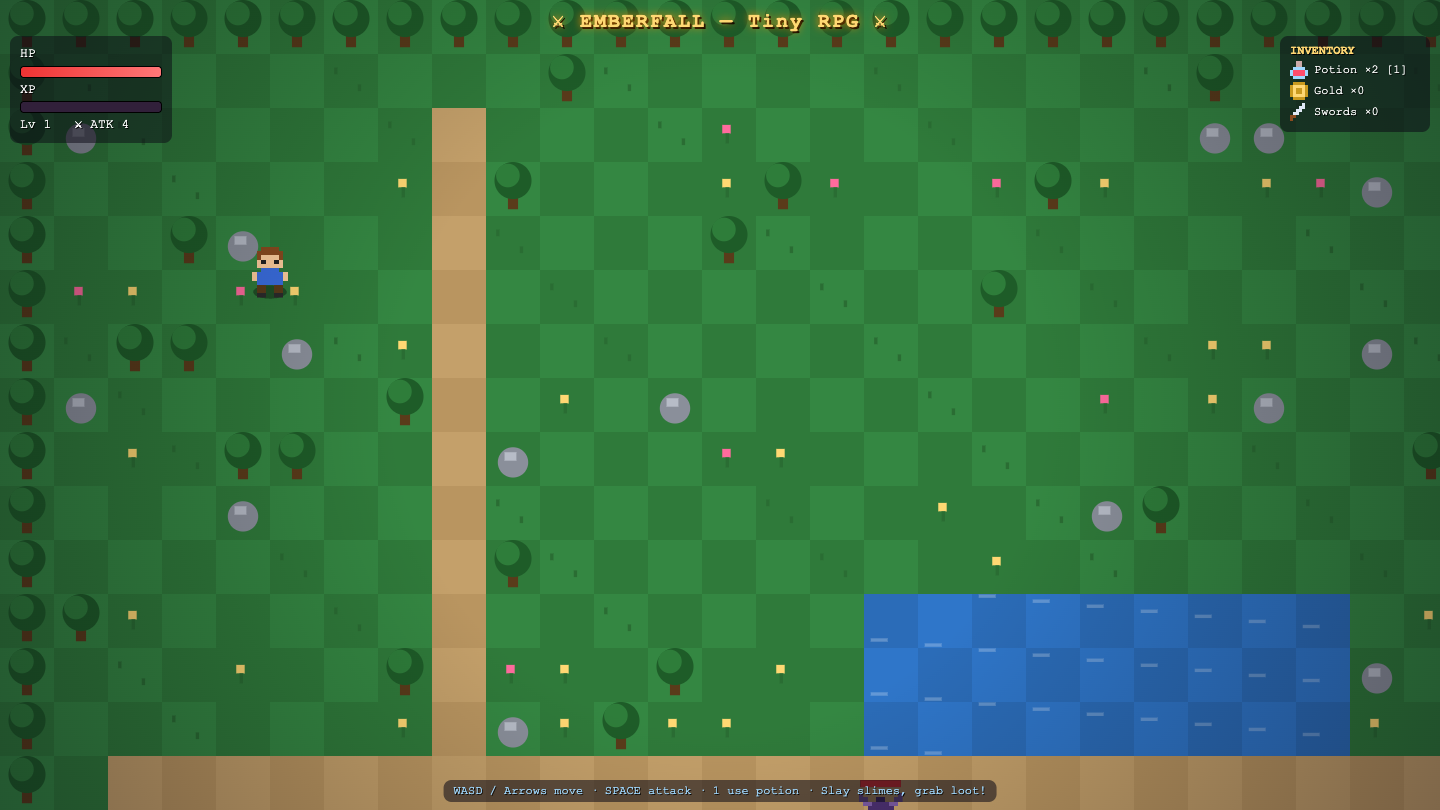
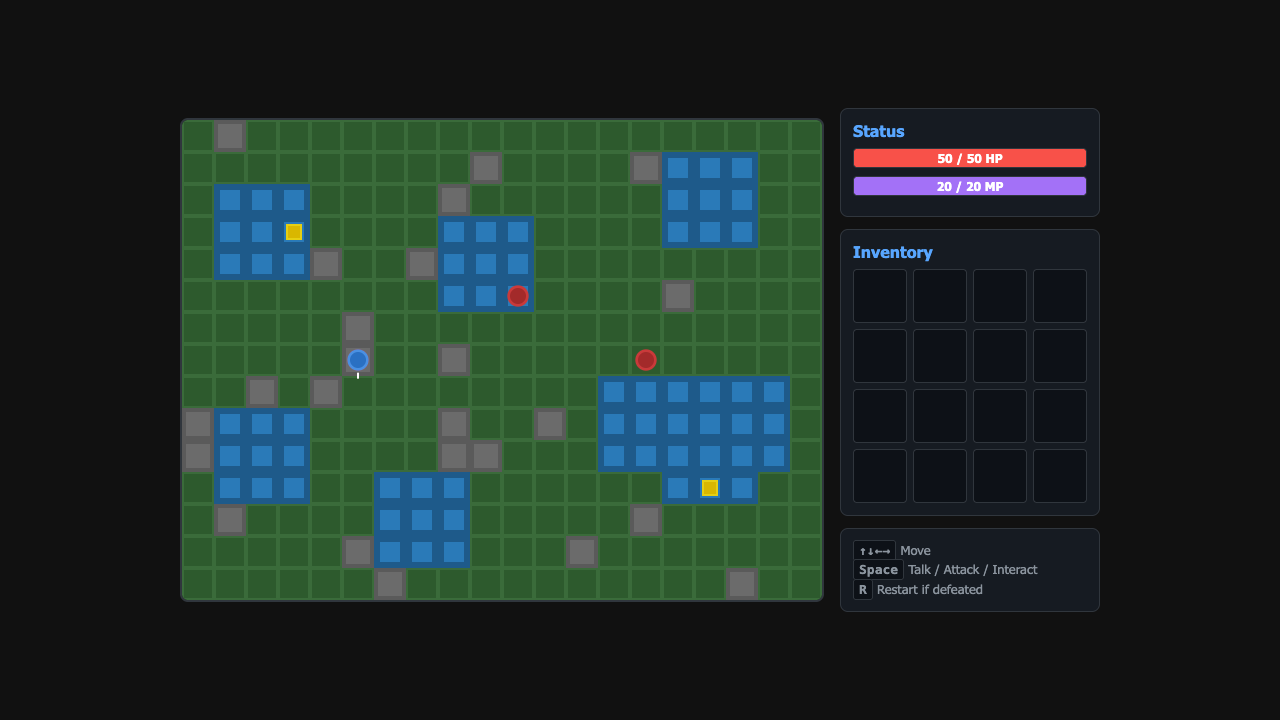
Game


Game


Game
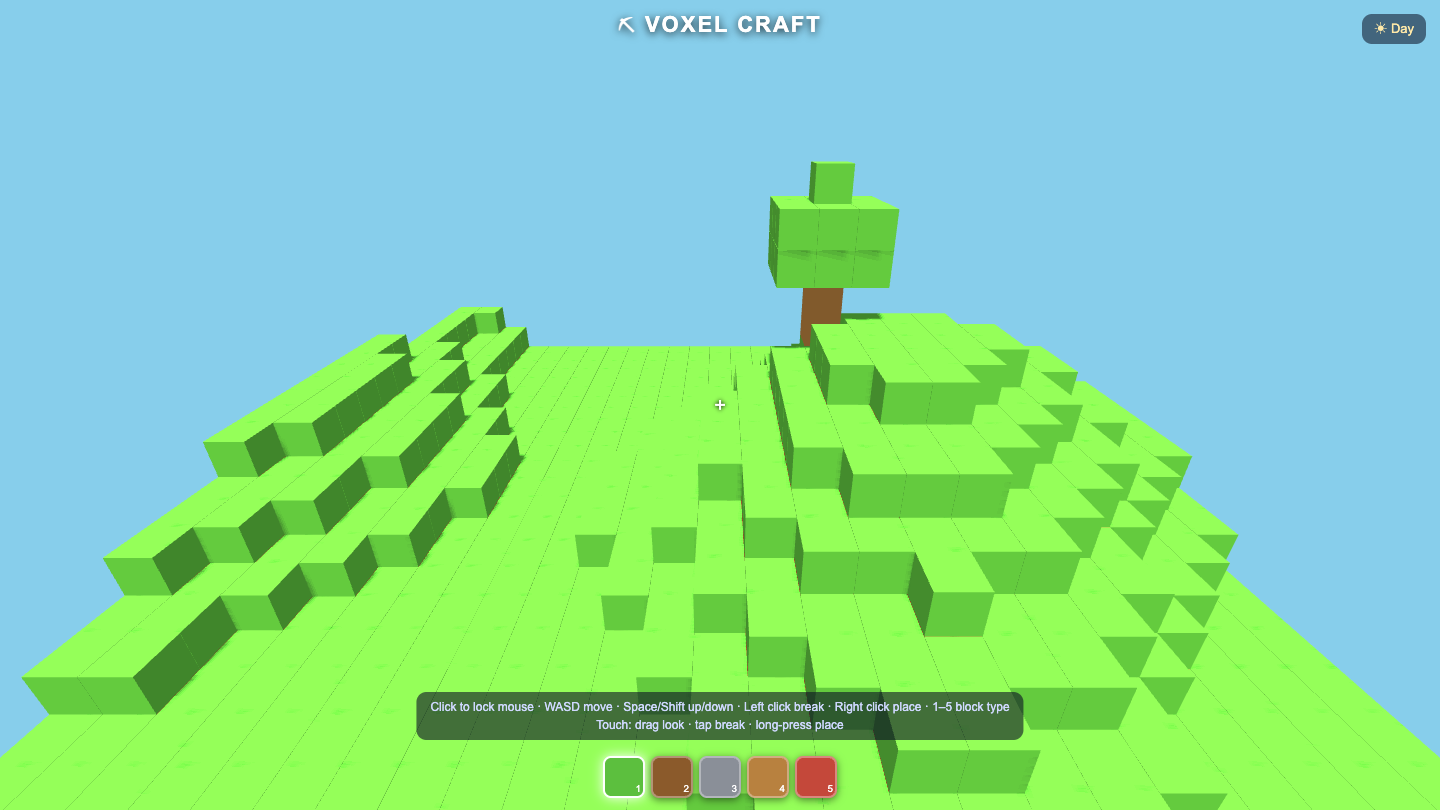
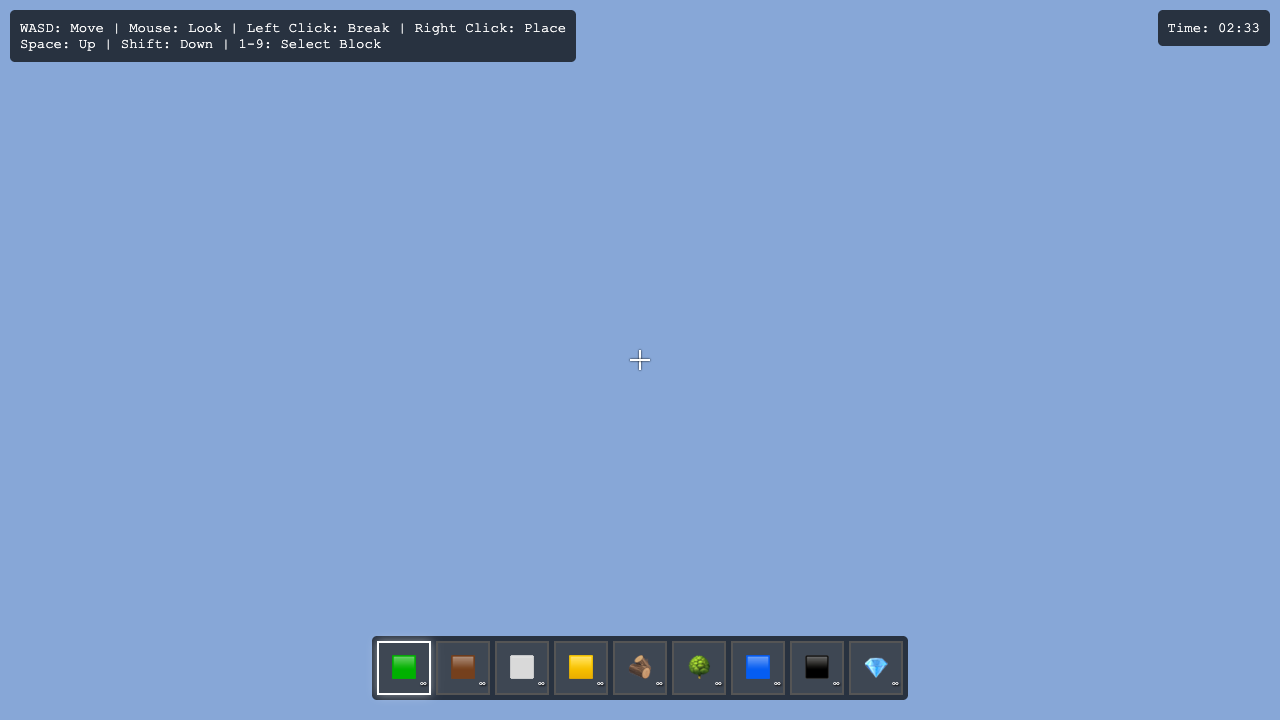
Page
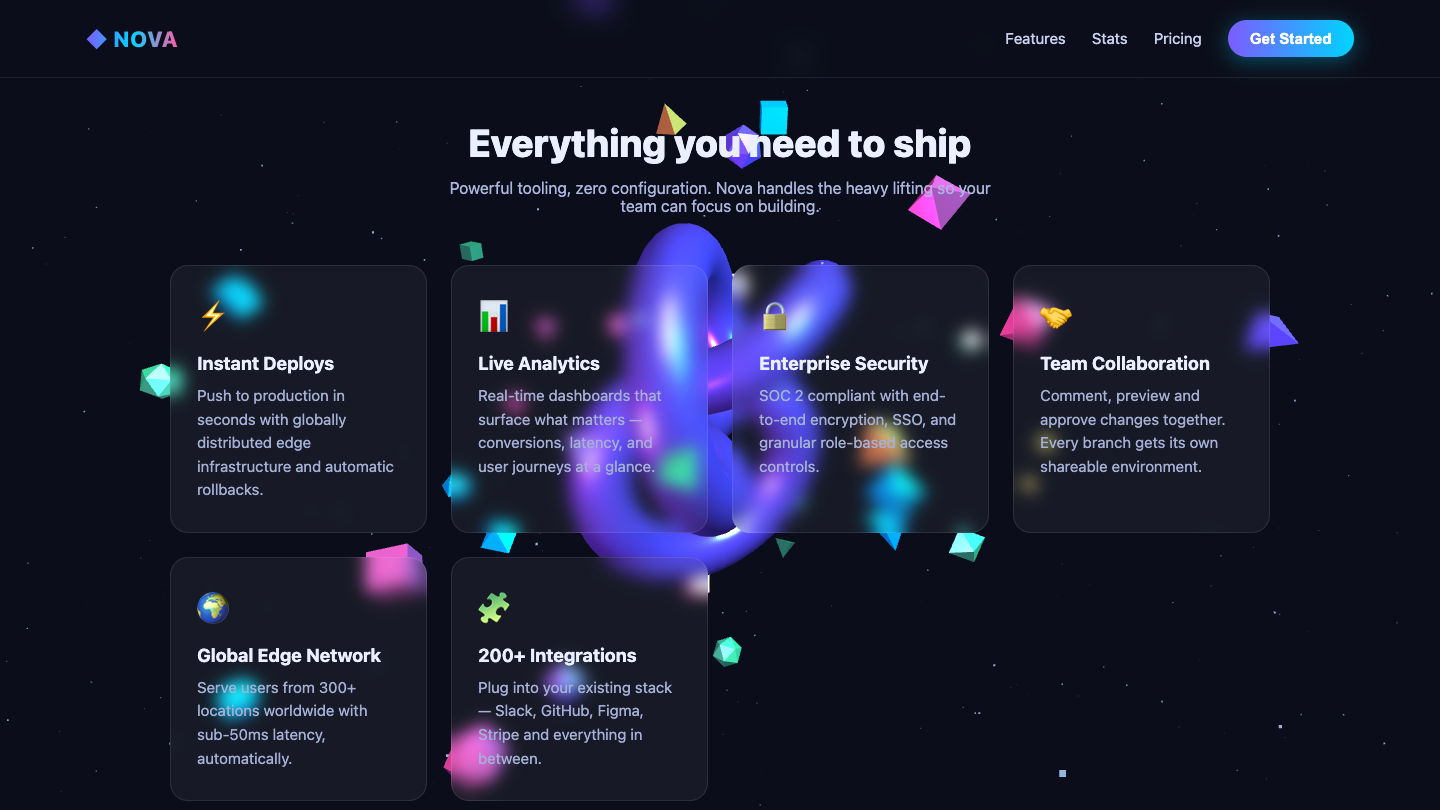
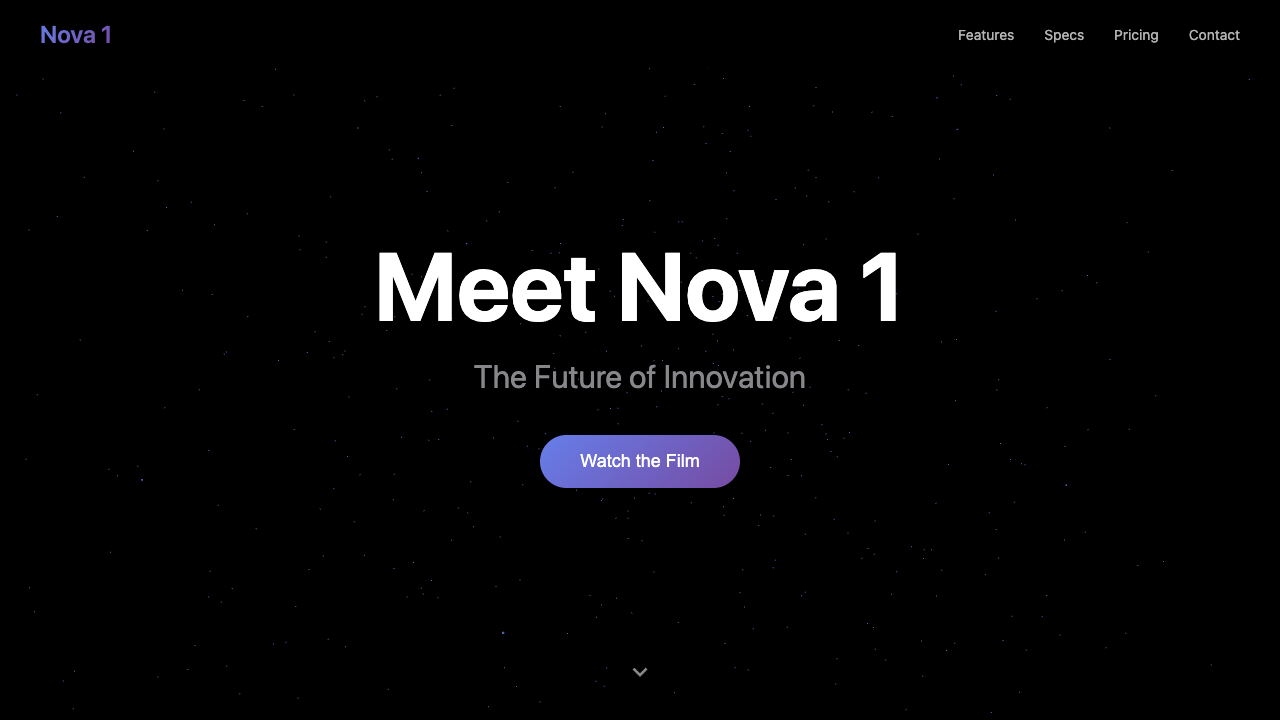
Page
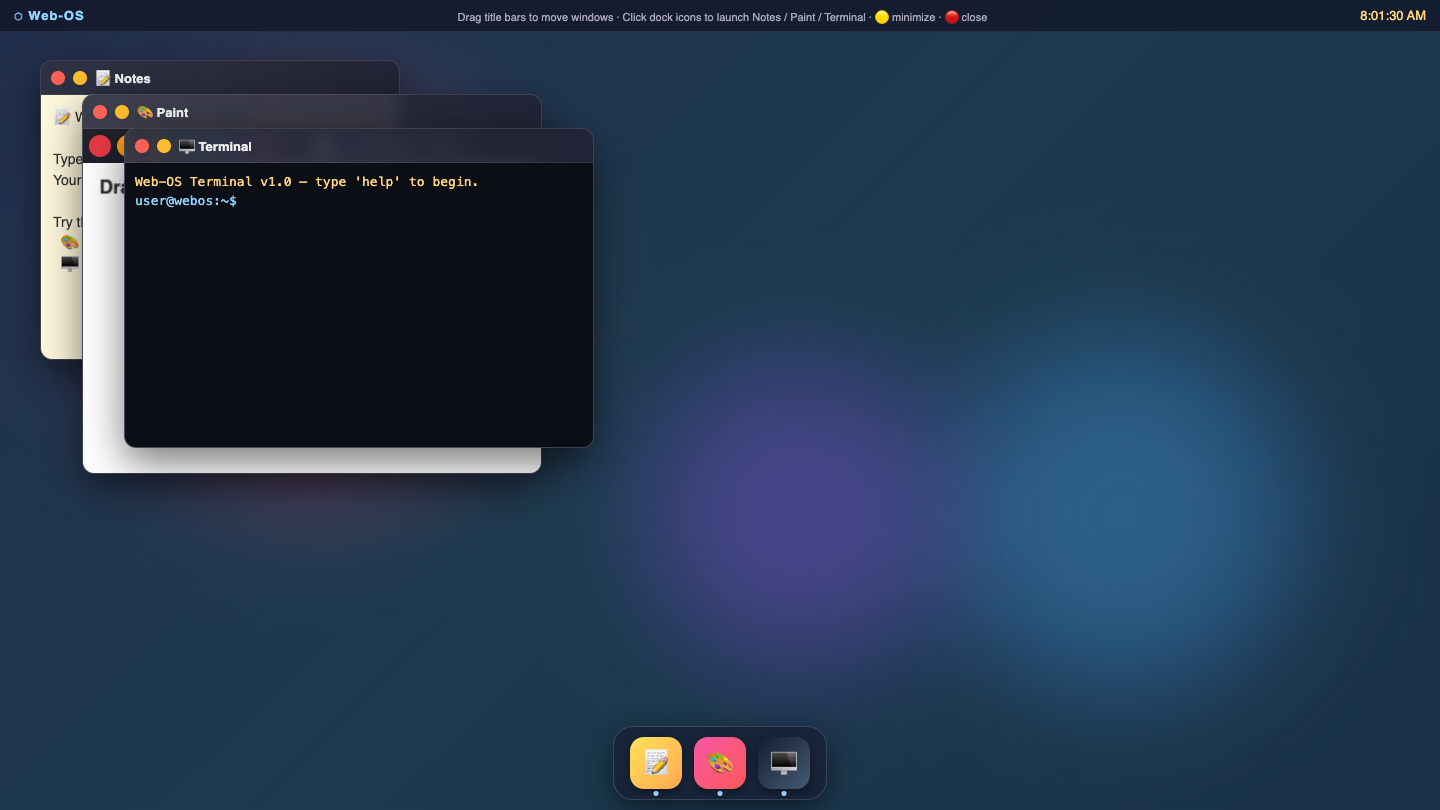

Sim


Sim
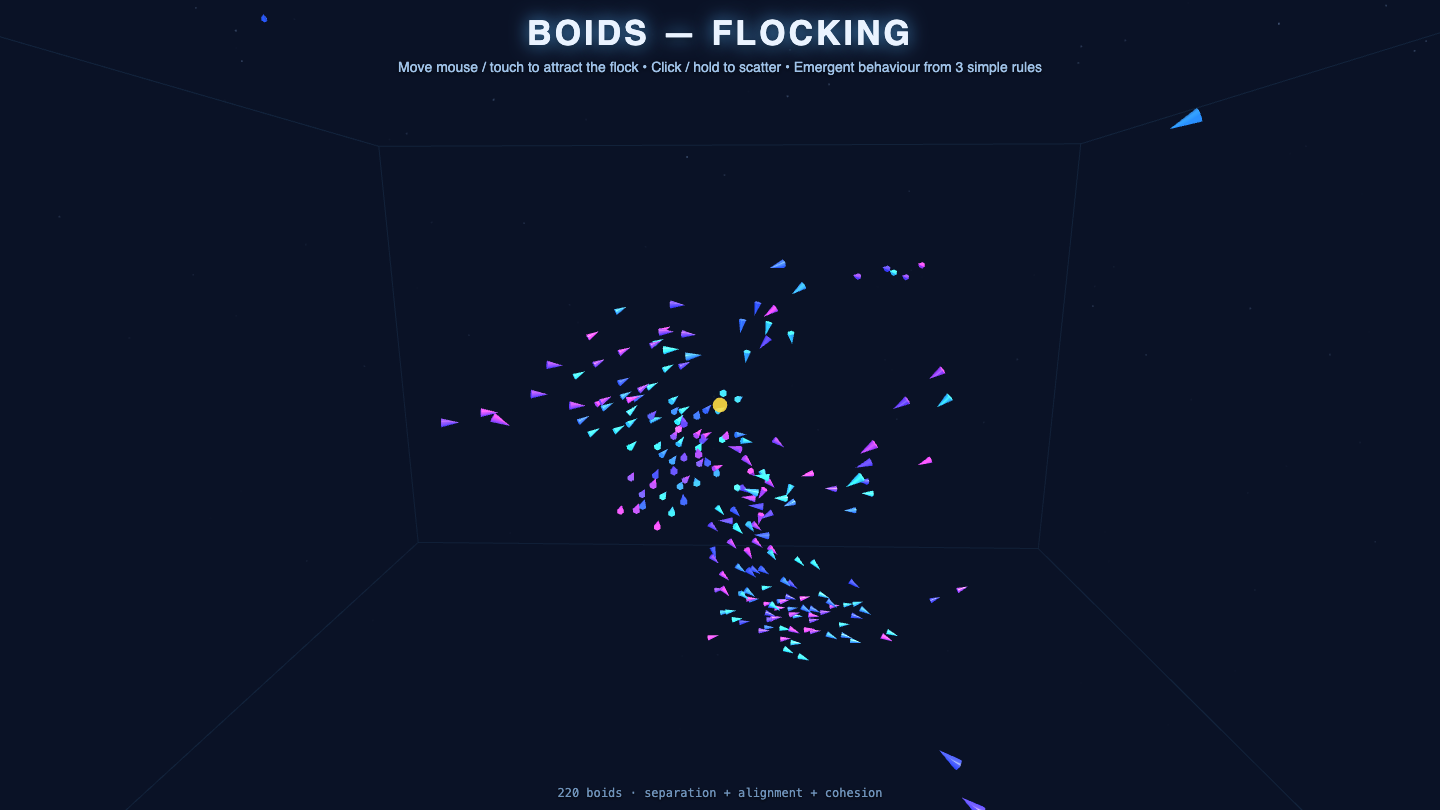
Sim

Strengths & weaknesses I logged
Claude Fable 5
Strengths
- Best solo Anthropic model on this bench — 7.72 avg beats Opus 4.8 (7.49) and Sonnet 5 (7.18)
- Wins most head-to-heads vs every solo rival: beats Opus 4.8 on 26/42 tasks and GLM-5.2 on 27/42 — two one-shot crashes, not the craft, cost it the average
- 10 task-winner tags in a single one-shot run — shader/GPU physics is its superpower (Cornell-box path tracer 8.7, black-hole lensing 8.7, synthwave outrun 8.7)
- Tops external SWE-bench Verified at 95.0% in Julian's three-dragons writeup
Trade-offs
- Two one-shot black-screens (crypt, twilightvale) from three.js r128 API drift — called THREE.Geometry / CapsuleGeometry, which the pinned CDN doesn't have
- Free GLM-5.2 still edges it on creative one-shots (7.77 vs 7.72) at $0 — the $10/$50 premium buys agentic depth, not one-shot visuals
Kimi K2.7 · Quality
Strengths
- Highest-effort reasoning path of the three Kimi modes
- Hand-tuned output polish on creative tasks
- Same flat-rate plan as Fast and No-Think — no premium
Trade-offs
- Slower than Fast and No-Think — not for snappy loops
- Not scored on the standalone bench — see methodology
Pricing & context — the spec sheet
| Spec | Claude Fable 5 | Kimi K2.7 · Quality |
|---|---|---|
| Vendor | Anthropic | Moonshot AI |
| Context window | 200,000 tokens (1M with extended thinking) | 256,000 tokens |
| Price | $10 / $50 per M tokens | Flat plan (no per-token bill) |
| Pricing detail | Released alongside Mythos 5 on June 9, 2026 as the publicly-available member of the new Mythos class. Premium per-token pricing on the Anthropic API; available everywhere Opus 4.8 ships. | Same flat-rate plan as standard Kimi K2.7 — Quality mode runs the deepest reasoning path. Vendor: Moonshot AI (moonshot.ai). |
| Release | 2026-06-09 | 2026-06 |
| Bench coverage | 42/42 scored · avg 7.72/10 | 0/42 scored · avg — |
The verdict — which should you pick?
Not enough scored shared tasks yet for a head-to-head average. The live demos for both are on the matrix above — play them and form your own opinion.
If you only run one of these inside your stack, the head-to-head average above is the call. If you can run both, my honest play is to wire Claude Fable 5 and Kimi K2.7 · Quality both into the Agent Operating System and dispatch each from the kanban by task type — mission-critical one-shot builds where you want anthropic's newest reasoning → Claude Fable 5, one-shot games and sims where polish matters → Kimi K2.7 · Quality. That's the same setup I run for the 3,600+ founders inside the AI Profit Boardroom.
FAQ — Claude Fable 5 vs Kimi K2.7 · Quality
Which is better, Claude Fable 5 or Kimi K2.7 · Quality?
On Goldie Bench, Claude Fable 5 averages no scored verdicts yet across the shared tasks, with 3 gold, 1 silver, 7 bronze overall. Kimi K2.7 · Quality averages no scored verdicts yet, with 0 gold, 0 silver, 0 bronze. Not enough scored shared tasks yet to call a winner.
How much does Claude Fable 5 cost vs Kimi K2.7 · Quality?
Claude Fable 5: Released alongside Mythos 5 on June 9, 2026 as the publicly-available member of the new Mythos class. Premium per-token pricing on the Anthropic API; available everywhere Opus 4.8 ships. Kimi K2.7 · Quality: Same flat-rate plan as standard Kimi K2.7 — Quality mode runs the deepest reasoning path. Vendor: Moonshot AI (moonshot.ai).
What's the context window for Claude Fable 5 vs Kimi K2.7 · Quality?
Claude Fable 5 has a 200,000 tokens (1M with extended thinking) context window. Kimi K2.7 · Quality has a 256,000 tokens context window.
When should I pick Claude Fable 5 over Kimi K2.7 · Quality?
Pick Claude Fable 5 for: Mission-critical one-shot builds where you want Anthropic's newest reasoning; Long-context work using extended thinking up to 1M tokens; Plan-heavy multi-step tasks where intelligence in the plan matters more than the build. The trade-off is the weaknesses we logged on the bench: Two one-shot black-screens (crypt, twilightvale) from three.js r128 API drift — called THREE.Geometry / CapsuleGeometry, which the pinned CDN doesn't have; Free GLM-5.2 still edges it on creative one-shots (7.77 vs 7.72) at $0 — the $10/$50 premium buys agentic depth, not one-shot visuals.
When should I pick Kimi K2.7 · Quality over Claude Fable 5?
Pick Kimi K2.7 · Quality for: One-shot games and sims where polish matters; Creative writing where you want the model to slow down; Final-pass refinement of an earlier draft. The trade-off is the weaknesses we logged on the bench: Slower than Fast and No-Think — not for snappy loops; Not scored on the standalone bench — see methodology.
How does Goldie Bench score Claude Fable 5 vs Kimi K2.7 · Quality?
Every demo on this page was built by Julian Goldie inside the Agent Operating System — same fixed prompt for both models, one shot, single HTML file out. Each result gets a 0–10 score on whether it ran, how close it hit the brief, and how good it looked. The highest score on each task gets gold; second gets silver; third gets bronze. See methodology for full provenance.
Related comparisons
Other head-to-heads using the same scoring system:
Claude Fable 5 vs Fusion Kimi K2.7 · Quality vs Fusion Claude Fable 5 vs Hermes MoA Kimi K2.7 · Quality vs Hermes MoA Claude Fable 5 vs Grok Kimi K2.7 · Quality vs Grok Claude Fable 5 vs MiniMax M3 Kimi K2.7 · Quality vs MiniMax M3Full model pages: Claude Fable 5 · Kimi K2.7 · Quality · back to the leaderboard
The same stack Julian uses
Run this stack yourself.
Every demo on this bench was built inside the Agent Operating System — one prompt, one shot, single HTML file out. The Agent OS, the prompts, the templates, the weekly walkthroughs and 3,600+ founders shipping with it every day all live inside the AI Profit Boardroom.
3,600+founders
258documented wins
38countries
$59/momonthly